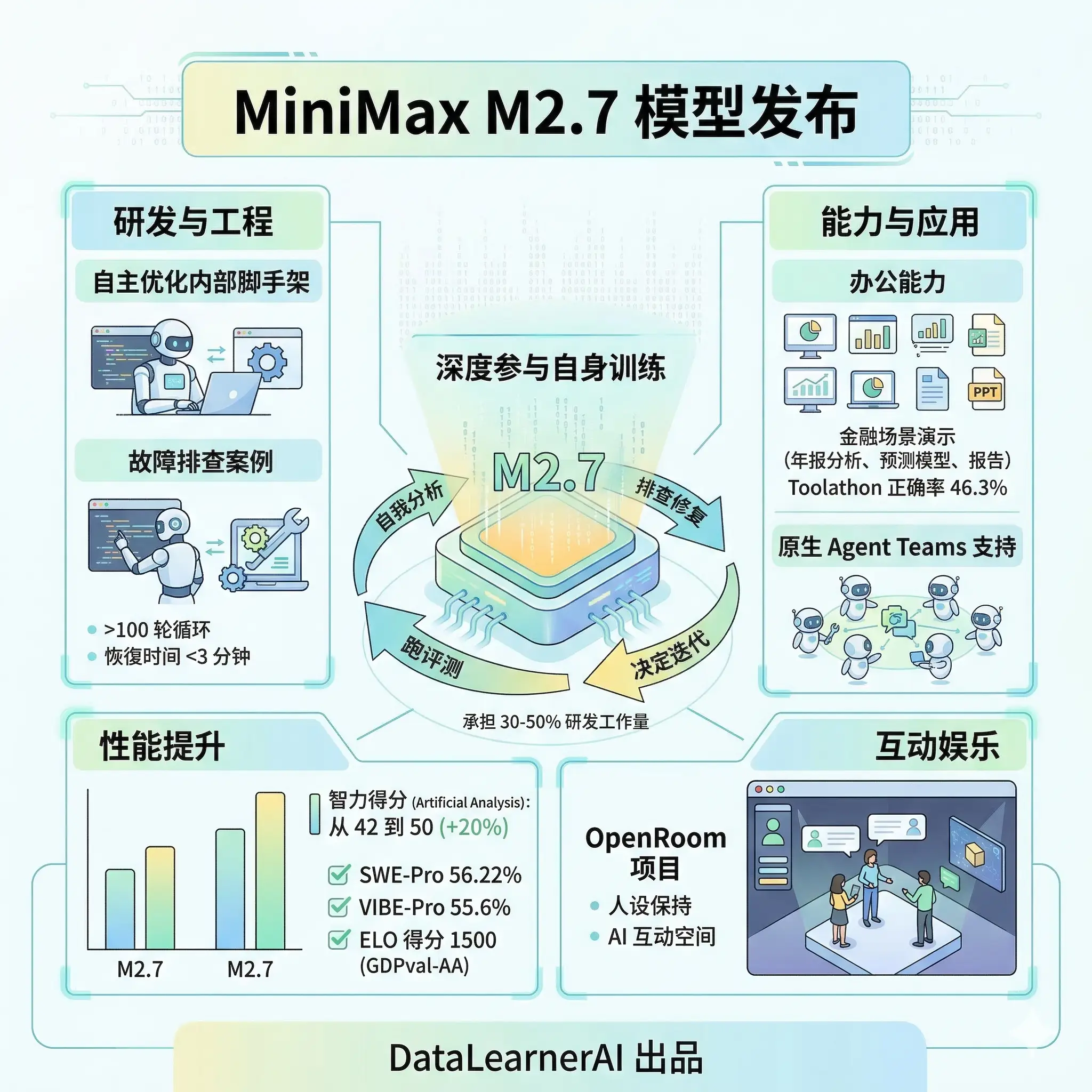
MiniMax M2.7 发布:模型开始帮自己训练自己
MiniMaxAI 刚刚发布了全新的 M2.7 模型,官方说本次发布的 M2.7 最大的特点是第一个深度参与迭代自身训练流程的模型,也就是说模型在训练过程中进行了自我分析并参与迭代。目前 M2.7 已经可以在官网使用,接口价格不变。不过该模型当前并未宣布开源,还不确定未来情况。
汇总「MiniMax」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
MiniMaxAI 刚刚发布了全新的 M2.7 模型,官方说本次发布的 M2.7 最大的特点是第一个深度参与迭代自身训练流程的模型,也就是说模型在训练过程中进行了自我分析并参与迭代。目前 M2.7 已经可以在官网使用,接口价格不变。不过该模型当前并未宣布开源,还不确定未来情况。
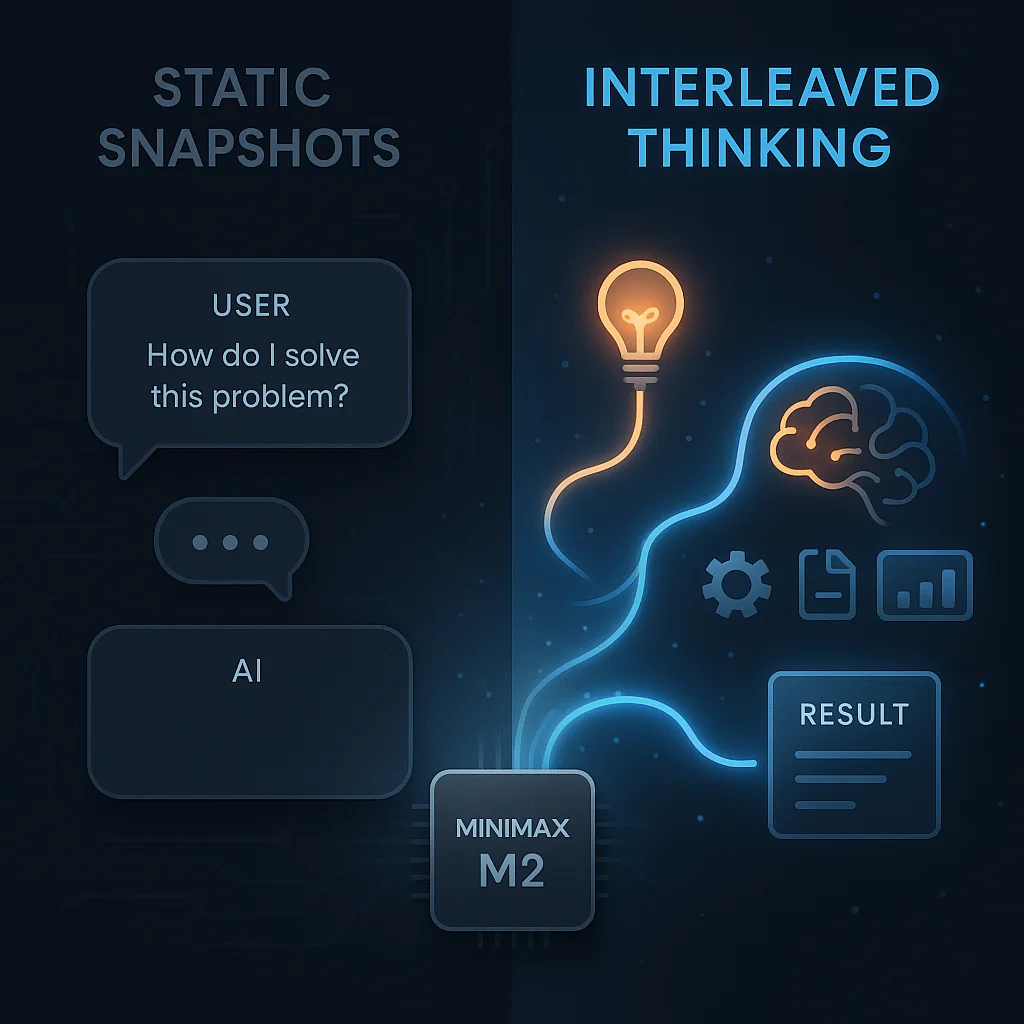
MiniMax M2发布2周后已经成为OpenRouter上模型tokens使用最多的模型之一。已经成为另一个DeepSeek现象的大模型了。然而,实际使用中,很多人反馈说模型效果并不好。而此时,官方也下场了,说当前大家使用MiniMax M2效果不好的一个很重要的原因是没有正确使用Interleaved Thinking。正确使用Interleaved thinking模式,可以让MiniMax M2模型的效果最多可以提升35%!本文我们主要简单聊聊这个Interleaved thinking。

MiniMax正式开源MiniMax M2模型,该模型定位是“Mini 模型,Max 编码与代理工作流”。最大的特点是2300亿总参数量,但是每次推理仅激活100亿,类似于10B模型。这款模型非常火爆,原因在于这么小的激活参数数量,推理速度很快,但是其评测结果非常优秀。

MiniMaxAI于2025年6月17日正式发布了其新一代大模型——MiniMax-M1。MiniMax-M1的核心亮点在于结合了混合专家(MoE)架构和创新的闪电注意力(Lightning Attention)机制。MiniMax-M1不仅原生支持高达100万Token的上下文长度,推理的tokens也支持最高80K,是当前支持的最多推理长度的大模型。此外,MiniMax-M1在计算效率上也很高,例如在生成10万Token时,其FLOPs消耗仅为DeepSeek R1的25%!