AA-LCR:大模型长上下文推理能力的权威评测基准(Artificial Analysis Long Context Reasoning)是什么?包含哪些任务?如何测试大模型超长上下文能力?
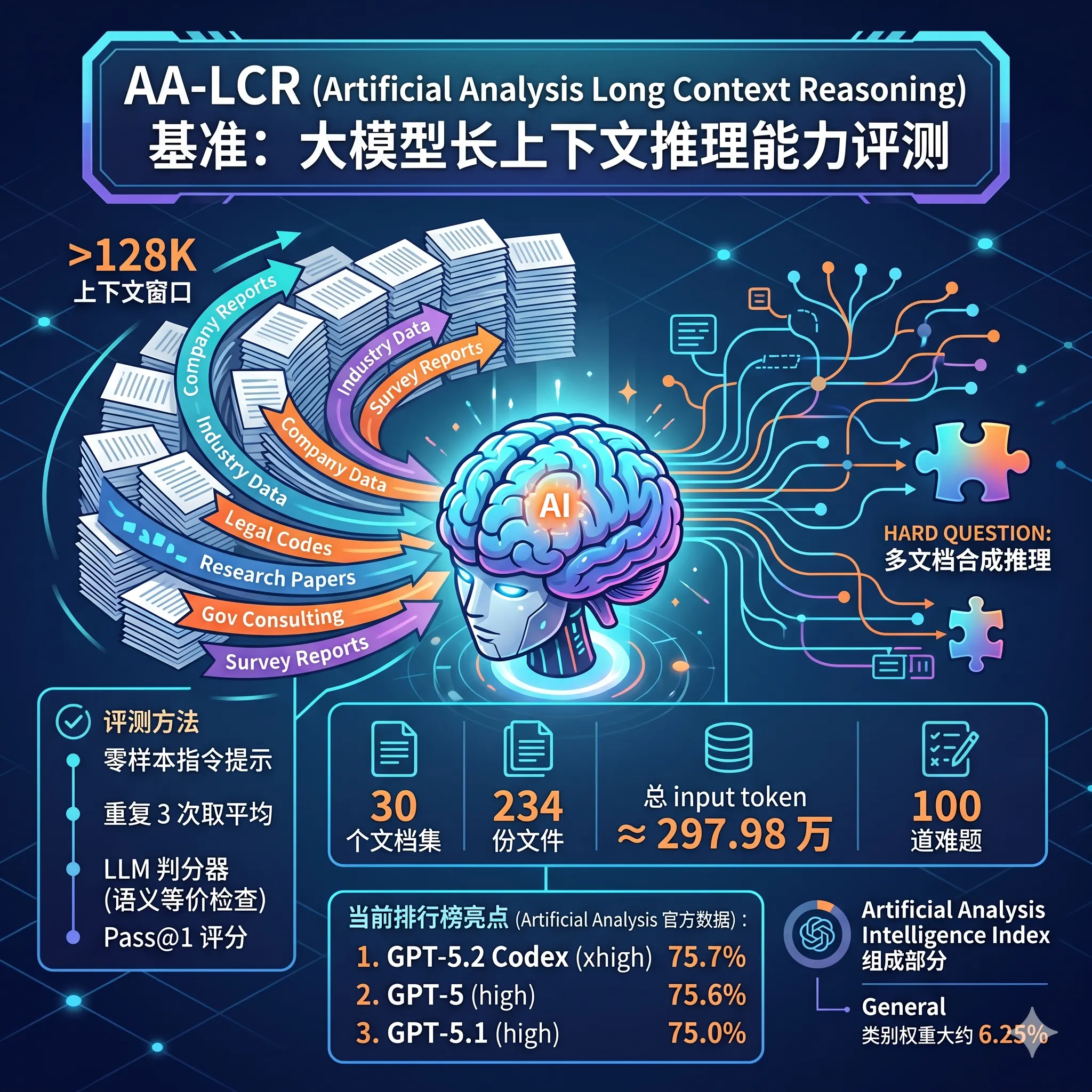
在当今大语言模型(LLM)迅猛发展的时代,长上下文处理能力已成为区分前沿模型的关键指标之一。许多模型宣称支持百万级上下文窗口,但实际“有效”长上下文推理能力往往难以验证。Artificial Analysis(简称 AA)推出的 AA-LCR(Artificial Analysis Long Context Reasoning)基准,正是针对这一痛点设计的一套高难度、真实世界导向的评测标准。它专注于评估模型在处理多文档、长输入(平均约10万token)时的信息提取、合成与复杂推理能力,已成为 Artificial Analysis Intelligence Index 的重要组成部分。
什么是 AA-LCR?其设计目的
AA-LCR 是由独立 AI 评测机构 Artificial Analysis 开发的基准测试集,旨在真实模拟知识工作者(如分析师、研究员、律师)处理海量文档的场景。它不是简单的检索任务,而是要求模型:
- 从多个分散的长文档中提取关键信息;
- 进行多步推理、数学计算、逻辑合成、法律/财务解读、时间序列分析等;
- 生成无歧义的开放式答案。
基准强调**“真正推理而非简单提取”**,问题设计避免了直接引用某一段落即可回答的情况。
核心数据:
- 100 道难题(hard questions);
- 30 个文档集,总计 234 份真实世界文档;
- 总独特输入 token ≈ 297.98 万(使用 cl100k_base tokenizer);
- 每个文档集平均 ≈ 99,325 token(范围 71k–115k),模型需至少支持 128K 上下文窗口才能完整评测;
- 7 大文档类别:Company Documents(公司报告/财务报表,63 题)、Industry Reports(行业报告)、Government Consultations(政府咨询/监管文件)、Academia(学术论文)、Legal(法律文本)、Marketing Materials(营销材料)、Survey Reports(调查报告)。
文档均来自公开来源(如欧盟竞争政策 PDF、澳大利亚财政部非竞争条款咨询文件、公司财报、欧盟 AI Act 文本等),无版权问题。
评测方法与评分机制
AA-LCR 采用零样本(zero-shot)指令提示,无 few-shot 示例:
BEGIN INPUT DOCUMENTS
[文档1]
[文档2]
...
END INPUT DOCUMENTS
START QUESTION
[问题]
END QUESTION
- 重复 3 次 取平均,降低随机性;
- 开放式答案,使用强大 LLM 判分器(Qwen3 235B A22B 2507 Non-Reasoning 版本)进行语义等价检查(equality checker),而非严格字符串匹配;
- pass@1 评分:首次生成即正确才算通过;
- 温度设置:非推理模型 0,推理模型 0.6(或其他官方指定);
- 纯英文文本 输入与评估。
人类表现基准:基准设计难度极高,领域专家首次尝试准确率通常仅 40–60%,体现了其挑战性。
当前排行榜亮点(数据来自 Artificial Analysis 官方 leaderboard)
前沿模型在 AA-LCR 上表现显著优于 2024 年中期的 <50% 水平:
- GPT-5.2 Codex (xhigh):75.7%(当前最高)
- GPT-5 (high):75.6%
- GPT-5.1 (high):75.0%
其他值得关注的开源/闭源模型也在持续迭代中(如 Kimi、DeepSeek、Llama 等在长上下文任务上的进步)。AA-LCR 是 Artificial Analysis Intelligence Index 的 General 类别组成部分(权重约 6.25%),与 MMLU-Pro、GPQA Diamond、HLE、IFBench、SciCode、Terminal-Bench Hard、𝜏²-Bench 等共同构成综合智能指数(95% 置信区间 < ±1%)。
为什么 AA-LCR 重要?实际意义
- 填补长上下文评测空白:传统基准(如 Needle-in-a-Haystack)多为简单检索,AA-LCR 强调多文档合成推理,更贴近真实企业/科研场景(财报分析、监管合规、学术文献综述等)。
- 推动模型进步:暴露了当前模型在超长上下文下的“注意力衰减”“信息遗忘”“推理链断裂”等痛点,促使开发者优化 RoPE、稀疏注意力、KV 缓存、测试时扩展等技术。
- 独立可信:Artificial Analysis 以标准化、重复测试、跨提供商一致性著称,避免了厂商自报数据的偏差。
- 开源数据集:完整数据集已在 Hugging Face 公开(https://huggingface.co/datasets/ArtificialAnalysis/AA-LCR),包含问题、参考答案、文档文件名/URL、token 计数等,便于研究者和开发者复现或微调。许可证为 Apache-2.0(问题部分),文档为公开来源。
如何获取与使用
- 官网 leaderboard:https://artificialanalysis.ai/evaluations/artificial-analysis-long-context-reasoning
- 方法论详情:https://artificialanalysis.ai/methodology/intelligence-benchmarking
- 数据集:Hugging Face Datasets(CSV + Parquet,支持 pandas / datasets 库快速加载)
- EvalScope 等框架 已支持 AA-LCR 评测,方便本地/云端运行。
结语
AA-LCR 代表了大模型评测从“广度”(MMLU 等)向“深度”(真实长文档推理)演进的重要一步。随着上下文窗口继续扩展(128K → 1M+),类似基准将越来越关键——它不仅衡量模型“能读多少”,更衡量模型“能理解并正确推理多少”。未来,我们期待更多开源模型在 AA-LCR 上逼近或超越闭源巨头,同时也希望看到针对中文、多模态长上下文的扩展版本。
如果你正在选型大模型、开发 Agent 或研究长上下文优化,强烈推荐关注 AA-LCR 及其所在 的 Artificial Analysis Intelligence Index。它提供了一个透明、严谨、可复现的参考框架,帮助我们超越营销宣传,看清模型的真实能力边界。
欢迎在评论区分享你对 AA-LCR 的看法或实测结果!更多前沿基准解读,敬请关注。
(本文基于 Artificial Analysis 官方文档与公开数据集整理,所有数据以官网最新为准。)
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
