阿里一次发布3款Qwen大模型:开源的全模态Qwen3-Omni和图像编辑大模型Qwen-Image-Edit-2509和不开源的语音识别大模型Qwen3-TTS
- 几个小时前,阿里一次更新了3个大模型,分别是开源的全模态大模型Qwen3-Omni、开源的图像编辑大模型Qwen3-Image-Edit和不开源的语音识别大模型Qwen3-TTS。本次发布的3个模型均为多模态大模型,可以说阿里的大模型真的是全面开花,节奏很快!

免费可商用的全模态大模型:Qwen3-Omini-30B-A3B
Qwen3-Omini-30B-A3B是阿里开源全模态大模型,所谓的全模态是指该模型可以处理文本、图片、语音和视频四种不同类型的数据,同时可以返回文本或者语音。
阿里上个版本的全模态大模型Qwen2.5-Omni是半年前发布的,是一个稠密的70亿参数规模的模型。本次阿里开源的是MoE架构的全模态大模型,总参数300亿,每次推理激活其中的30亿。
根据阿里Qwen团队的负责人Junyang Lin的描述。今年,阿里的语音团队花了很大的代价构建了大规模高质量的语音数据集,进而提升了阿里ASR、TTS模型的质量。然后,阿里将这些能力组合起来形成了这个全模态大模型。该模型是基于阿里7月升级之后的Qwen3模型打造,分为不带推理模式的版本和带推理模式的版本。
根据阿里官方的介绍,与Qwen2.5-Omni、GPT-4o和Gemini-2.5-Flash相比,Qwen3-Omini-30B-A3B在36个语音和语音多模态(Audio-Visual)上获得22个第一!十分强悍!
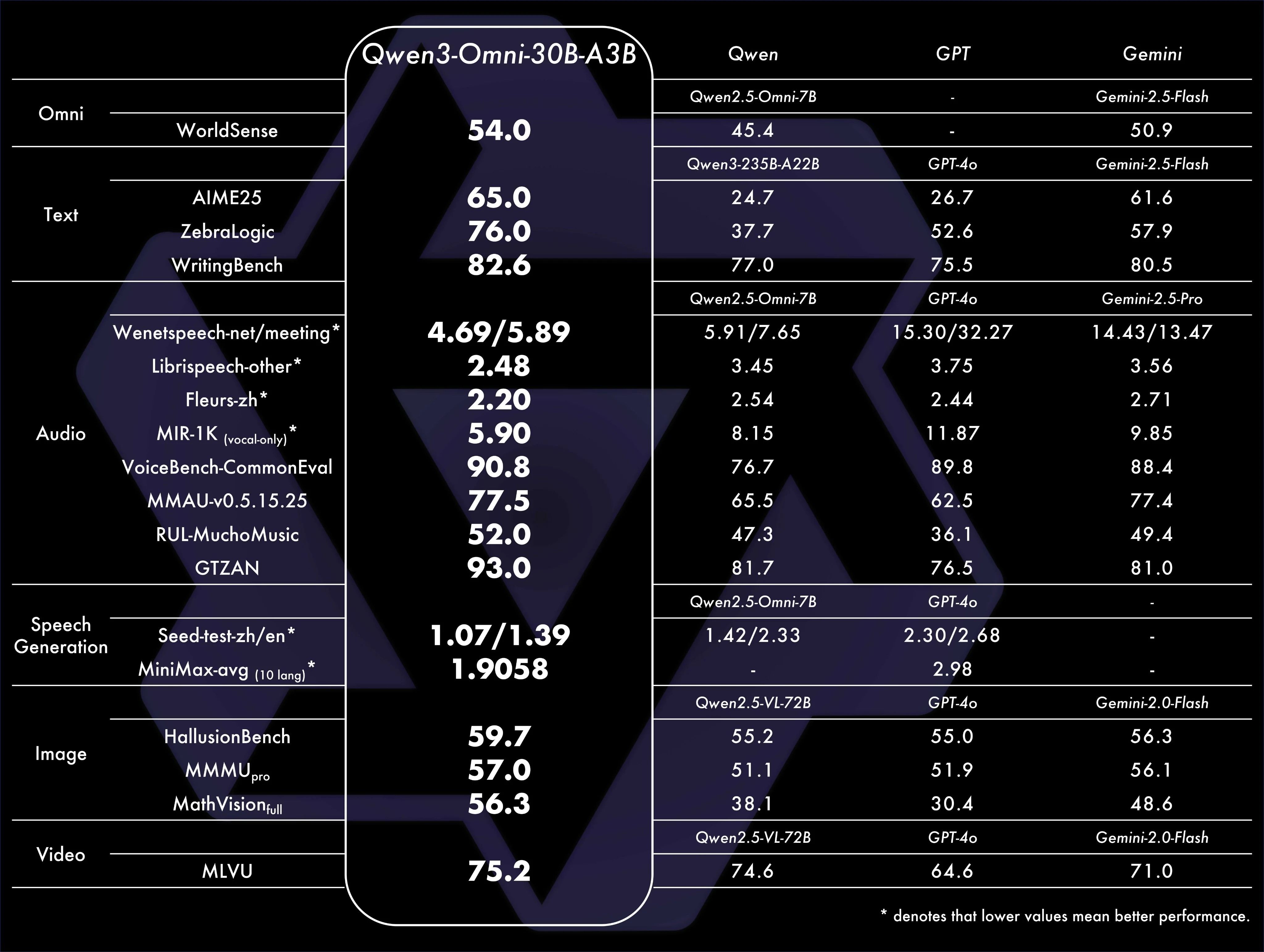
值得注意的是,本模型完全开源,开源协议是Apache2.0,可以免费商用授权,开源地址和在线演示地址可以参考DataLearnerAI的Qwen3-Omini-30B-A3B模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-Omni-30B-A3B
开源第一的图像编辑大模型Qwen-Image-Edit-2509
阿里本次开源的另一个大模型是图像编辑大模型Qwen-Image-Edit-2509,从名字也可以看到,这是一个升级版本的图像编辑大模型。
其实,上个月阿里才开源了Qwen-Image-Edit版本。这个版本已经在大模型匿名竞技场上获得了开源领域第一名的好成绩。时隔一个月阿里就开源了这个升级版本的模型,可谓十分敏捷!
简单来说,这次Qwen-Image-Edit-2509升级主要有三大块:
-
现在能玩多图了! 之前主要处理单张图,现在新版学会了“拼图”大法。你可以把好几张图一起扔给它,让它帮你处理。比如把两个人P到一起,或者把人P到某个产品旁边,玩法更多了。
-
P单张图的效果更逼真、更一致了! 这是个大改进,尤其是:
- P人像更稳了:现在给人换造型、换风格,脸不容易崩了,能很好地保住“这是同一个人”的感觉。
- P商品更准了:修改商品海报时,产品本身的样子保持得更好了,不会变得面目全非。
- P文字更强了:不光能改文字内容,现在连字体、颜色、质感(比如做成金属字)也能一起改了。
-
自带“控制开关”(ControlNet):这个对懂行的朋友是福音!现在它原生就支持用深度图、线稿、骨骼点图这些“指引图”来精确控制生成效果,不用再折腾了,出图更可控。
总之,就是功能更强,效果更自然,可控性也更高了!在大模型匿名竞技场的Image Edit Arena的评测对比上,全球网友匿名投票结果中,8月份的Qwen-Image-Edit就是全球开源模型的第一名,本次升级的Qwen-Image-Edit-2509应该也会有更靓眼的表现!
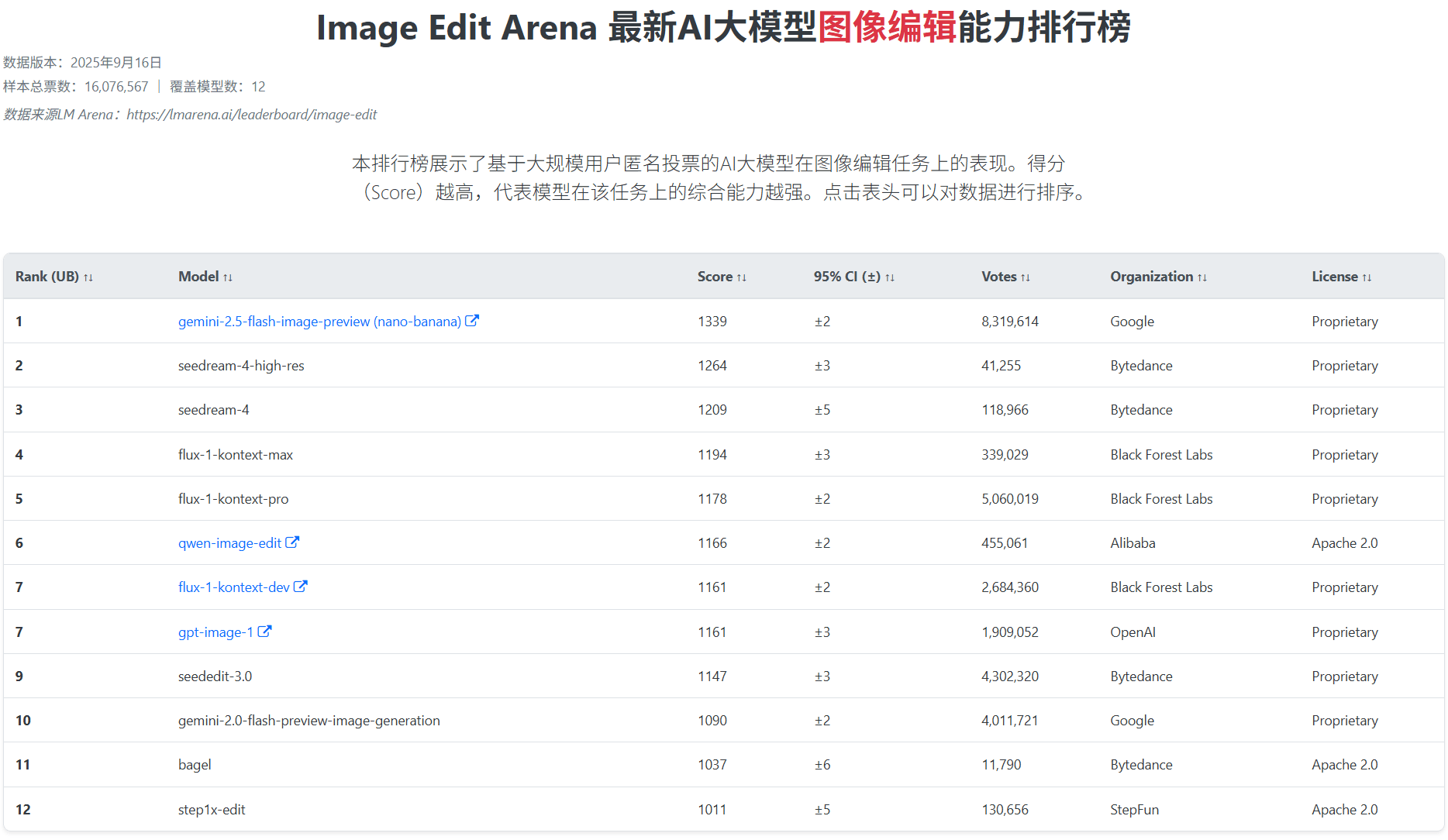
最最重要的是,该模型也是免费商用开源协议,具体的开源地址和在线体验地址也可以参考DataLearnerAI的大模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/Qwen-Image-Edit-2509
不开源但是很便宜的语音识别大模型Qwen3-TTS-Flash
除了上述2个开源模型外,本次阿里还发布了一个收费模型Qwen3-TTS-Flash。
前面也说过,今年阿里的语音团队花了很大代价构建了高质量的语音数据集,其最重要的产出就是语音识别和语音合成大模型。2025年9月8日,阿里发布了Qwen3-ASR模型,语音识别错误率低于GPT-4o和Gemini 2.5 Pro!也是一个不开源的模型。
本次阿里再次发布语音合成模型Qwen3-TTS-Flash,其最大的特点应该是说话带着情感,声音更像真人,在专业的语音合成稳定性测试中,其结果已经超过了SeedTTS、MiniMax 甚至 GPT-4o-Audio-Preview 这些知名对手,达到了目前最好的水平。
此外,Qwen3-TTS-Flash支持17中声音,每种声音都支持10种不同的语言,包括中文、英文、韩语、德语、意大利语、西班牙语、法语、俄语等。此外,它也支持很多中文和英文的方言,包括粤语、四川话、美式口音、英式口音等。
Qwen3-TTS-Flash不开源,API价格是1万个字符8毛钱(人民币),最大支持600个字符的输入(官方目前只有中文价格介绍,这个字符可能是tokens)。
Qwen3-TTS-Flash的其它信息也可参考DataLearnerAI模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-TTS-Flash
总结
整体来看,这次阿里一次性放出三个多模态模型,其实透露出一个很明确的战略思路:一边通过开源的全模态和图像编辑模型来做生态,把开发者和社区都拉进来;另一边,则用闭源但低价的语音合成模型来直接跑商业化,形成“开源做势能、闭源兑现金”的两条线并行。
阿里开源的模型质量很高,赢得了很好的声誉。目前看他们的节奏也非常快,每个月都有大量的新模型出现,十分值得关注。在很多细分领域,其开源的模型都获得了非常好的结果。
DataLearner WeChat
Follow DataLearner WeChat for the latest AI updates
