
仅需一行代码即可微调大语言模型——LightningAI发布全新Python库Lit-Parrot
大模型微调依然是针对大量私有数据或者特定领域不可缺少的方法。就在前不久,LightningAI发布了一个轻量级大模型微调库Lit-Parrot,仅需一行代码即可微调当前开源大模型。
A curated list of original AI and LLM articles related to "fine-tuning", updated regularly.
大模型微调依然是针对大量私有数据或者特定领域不可缺少的方法。就在前不久,LightningAI发布了一个轻量级大模型微调库Lit-Parrot,仅需一行代码即可微调当前开源大模型。
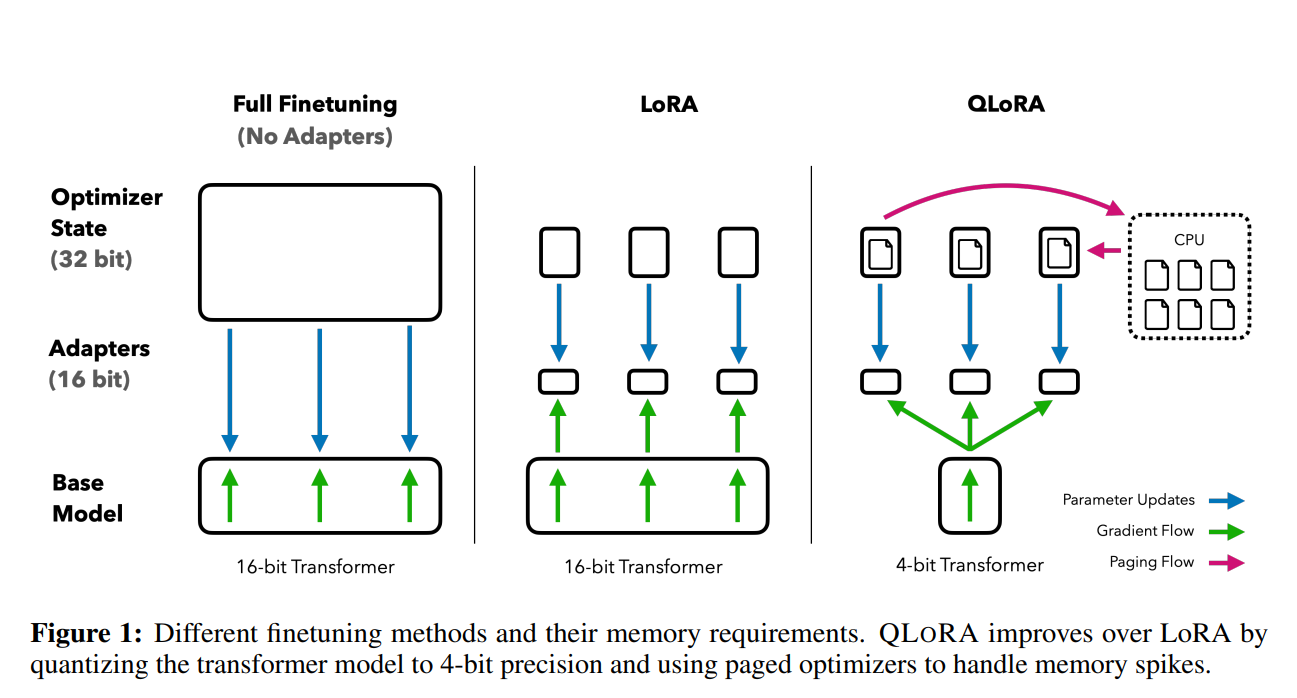
前段时间,康奈尔大学开源了LLMTune框架(https://www.datalearner.com/blog/1051684078977779 ),这是一个可以在48G显存的显卡上微调650亿参数的LLaMA模型的框架,不过它们采用的方法是将650亿参数的LLaMA模型进行4bit量化之后进行微调的。今天华盛顿大学的NLP小组则提出了QLoRA方法,依然是支持在48G显存的显卡上微调650亿参数的LLaMA模型,不过根据论文的描述,基于QLoRA方法微调的模型结果性能基本没有损失!
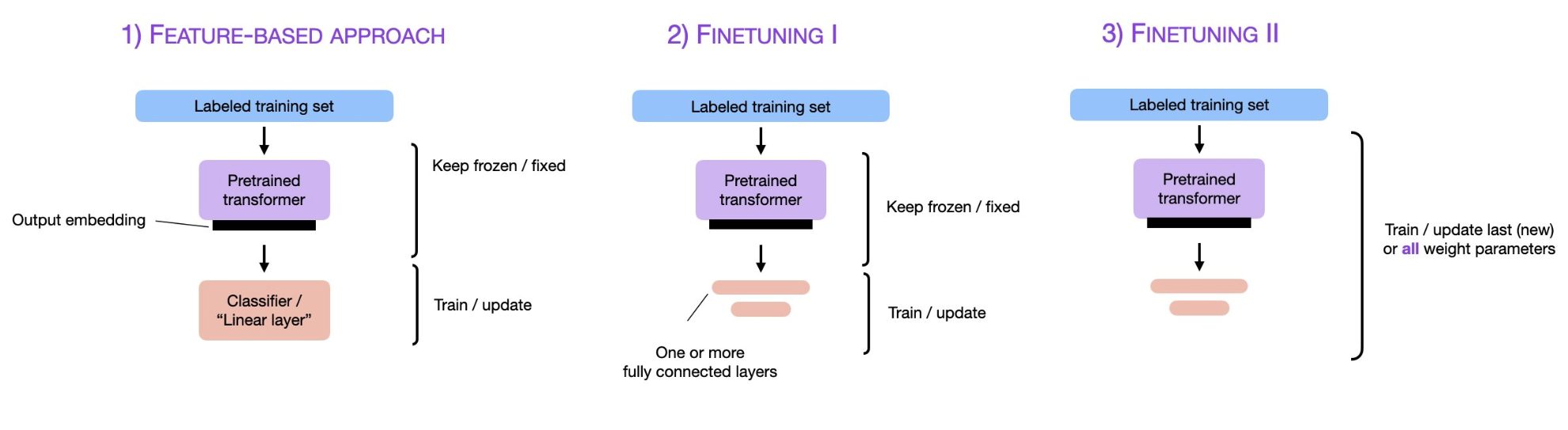
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。