FreeWilly2 - FreeWilly2
模型详细情况和参数
FreeWilly2
- 模型全称
- FreeWilly2
- 模型简称
- FreeWilly2
- 模型类型
- 基础大模型
- 发布日期
- 2023-07-21
- 预训练文件大小
- 287GB
- 是否支持中文(中文优化)
- 否
- 最高支持的上下文长度
- 2K
- 模型参数数量(亿)
- 700.0
- 模型代码开源协议
- CC BY-NC-SA 4.0
- 预训练结果开源商用情况
- CC BY-NC-SA 4.0 - 不可以商用
- 模型GitHub链接
- 暂无
- 模型HuggingFace链接
- https://huggingface.co/stabilityai/FreeWilly2
- 在线演示地址
- 暂无
- 基础模型
-

LLaMA2
查看详情 - 发布机构
FreeWilly2 简介
FreeWilly2是由StabilityAI发布的一个基于LLaMA2微调的大语言模型。FreeWilly2利用了原始的 LLaMA2-70B 基础模型,并通过 Supervised Fine-Tune (SFT) 在标准的 Alpaca 格式下,使用新的合成生成的数据集进行了精细调整。
FreeWilly系列模型的训练直接受到了微软在其论文 "Orca: Progressive Learning from Complex Explanation Traces of GPT-4" 中提出的方法的启发。StabilityAI数据生成过程与微软的类似,但数据源不同。StabilityAI数据集版本包含了 600,000 个数据点(大约是原始 Orca 论文使用的数据集大小的 10%),通过使用以下由 Enrico Shippole 创建的数据集中的高质量指令提示语言模型来创建:COT Submix Original、NIV2 Submix Original、FLAN 2021 Submix Original、T0 Submix Original。使用这种方法,StabilityAI生成了 500,000 个简单的 LLM 模型示例,以及 100,000 个更复杂的 LLM 模型示例。
为了确保公平的比较,Stability仔细筛选了这些数据集,并删除了源自评估基准的示例。尽管训练样本量只有原始 Orca 论文的十分之一(显著降低了训练模型的成本和碳足迹),但 FreeWilly 模型在各种基准测试中展示出了出色的性能,验证了合成生成数据集的方法。
模型通过在上述数据集上进行监督精调来学习,以混合精度(BF16)进行训练,并使用 AdamW 进行优化。训练的超参数:
| Dataset | Batch Size | Learning Rate | Learning Rate Decay | Warm-up | Weight Decay | Betas |
|---|---|---|---|---|---|---|
| Orca pt1 packed | 256 | 3e-5 | Cosine to 3e-6 | 100 | 1e-6 | (0.9, 0.95) |
| Orca pt2 unpacked | 512 | 3e-5 | Cosine to 3e-6 | 100 | 1e-6 | (0.9, 0.95) |
与FreeWilly2一同发布的还有FreeWilly1,这个模型是基于LLaMA微调的。
FreeWilly系列一发布就占据了各个榜单的排名靠前位置。二者的评估结果如下:
FreeWilly在HuggingFace的OpenLLM榜单排名
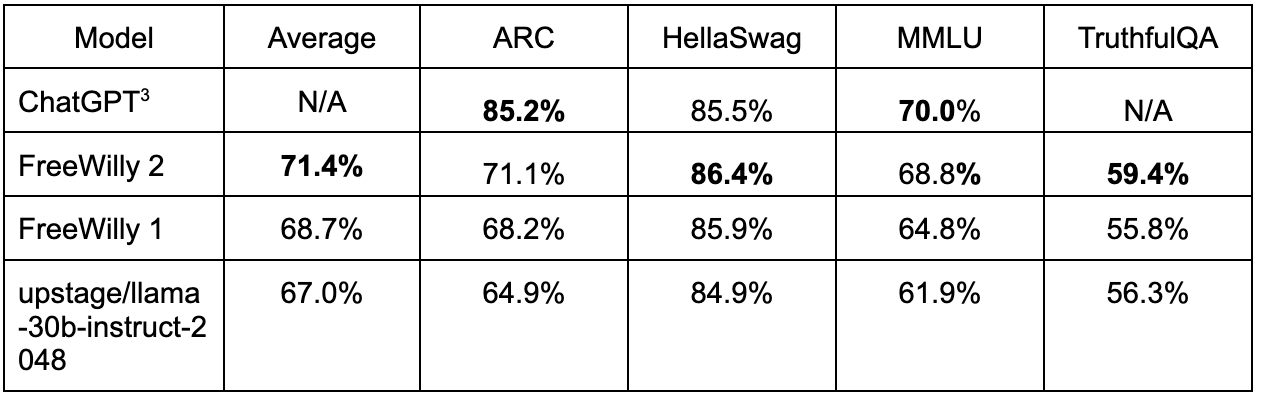
链接如下: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
在2023年7月23日的榜单上,FreeWilly2排名第一,FreeWilly1排名第二。
FreeWilly在GPT4All榜单得分

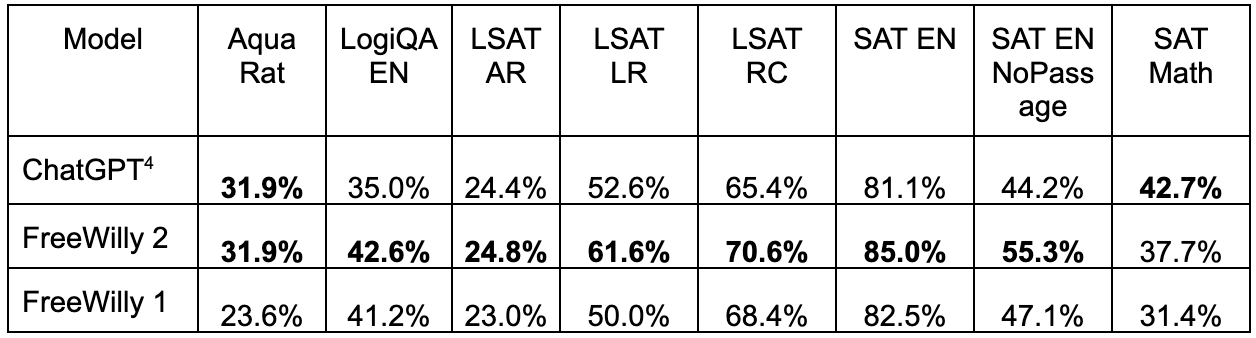
FreeWilly在微软的AGIEval得分
AGIEval是微软提出的一种通用人工智能评估工具,有20个任务,包括两个完形填空任务(Gaokao-Math-Cloze 和 MATH)和 18 个多选题回答任务(其余的)。在多选题回答任务中,Gaokao-physics 和 JEC-QA 有一个或多个答案,其他任务只有一个答案。在这个评估中,FreeWilly2的评估结果与ChatGPT差不多。
注意,FreeWilly2是不可商用的!
欢迎大家关注DataLearner官方微信,接受最新的AI模型和技术推送
