狄利克雷过程(Dirichlet Process Mixture Model,DPMM)的详细推导
首先,我们从高斯混合模型开始。有K个类别的高斯混合模型可以写成如下形式:
p(x|\theta_1,\cdots,\theta_K)= \sum_{j=1}^K \pi_j \mathcal{N}(x|\mu_j,S_j)
参数集合$\theta_j = \{\mu_j,S_j,\pi_j\}$是第$j$个组件的参数。$\pi$是混合比例(正值,且总和为1),$\mu_j$是组件$j$的均值向量,$S_j$是精度(是逆协方差矩阵)。当我们对所有组件的参数定义一个联合先验分布$G_0$,且引入一个指示变量$c_i,i=1,\cdots,n$,那么上述模型可以写成如下形式:
\begin{aligned}
x_i|c_i,\Theta & \sim \mathcal{N}(\mu_{c_i}, S_{c_i}) \\
&\\
c_i|\pi & \sim Dsicrete(\pi_1,.\cdots,\pi_K) \\
&\\
(\mu_j,S_j) & \sim G_0 \\
&\\
\pi|\alpha & \sim Dir(\alpha/K,\cdots,\alpha/K)
\end{aligned}
在给定了混合比例&\pi&的情况下,每个组件包含的观测值数量称之为占有数量,是一个多项式分布:
p(n_1,\cdots,n_K | \pi) = \frac{n!}{n_1!n_2!,\cdots,n_K!} \prod _{j=1}^K \pi_j^{n_j}
那么指示变量的分布是:
p(c_1,\cdots,c_n|\pi) = \prod_{j=1}^K\pi_j^{n_j}
指示变量是随机变量,它的值是用来对类编码的,是用来说明第$i$个观测值$y_i$所属于的类别。
给定一个对称的Dirichlet分布,其参数是$\alpha/K$,并将所有的组件都看成是一样的,这是将DPMM定义成一个有限的带参数的混合模型中关键的部分。我们将指示变量$p(c|\pi)$乘以混合比例$p(\pi)$的先验,然后将混合比例积分掉,我们可以得到在Dirichlet先验$\alpha$条件下的指示变量的形式:
p(c|\alpha) = \frac{\Gamma{(\alpha)}}{\Gamma(n+\alpha)} \prod_{j=1}^K \frac{ \Gamma(n_j+\alpha/K)}{\Gamma(\alpha/K)}
固定出了$c_i$以外的所有指示变量,由于所有的数据都是可交换的,我们可以得到如下的对于每个指示变量的条件概率:
p(c_i=j|c_{-i},\alpha) = \frac{n_{-i,j} + \alpha/K }{n-1+\alpha}
这里的下标$-i$表示除了$i$以外所有的元素,$n_{-i,j}$是出了$x_i$以外所有属于组件$j$的点的数量。假如我们的类别$K\to \infty$,那么上述$c_i$的条件先验可以写成如下形式:
1.当该类别下数据点的数量不为0的时候:
p(c_i = j | c_{-i},\alpha) = \frac{ n_{-i,j}}{n-1+\alpha}
2.当该类别下数据点数量为0,即是一个新类别的时候:
p(c_i = j | c_{-i},\alpha) = \frac{ \alpha }{n-1+\alpha}
假设我们的数据是服从正态分布的数据,即$x_i|\theta \sim \mathcal{N}(x_i|\mu_i,S_i)$,这时候我们可以定义模型的参数$(\mu_i,S_i)\sim G$,而$G\sim DP(\alpha,G_0)$。
接下来我们就是要选择基分布$G_0$了。最简单的选择是选择共轭先验,也就是说均值和方差未知的情况下,数据参数的先验可以选择正态-逆Wishart分布:
(\mu_j|S_j,\xi, \rho) \sim \mathcal{N}( \xi, (\rho S_j)^{-1})
(S_j|\beta,W) \sim \mathcal{W}(\beta, (\beta W)^{-1})
其联合先验是:
(\mu_j,S_j) \sim \mathcal{NW}(\xi,\rho,\beta,\beta W)
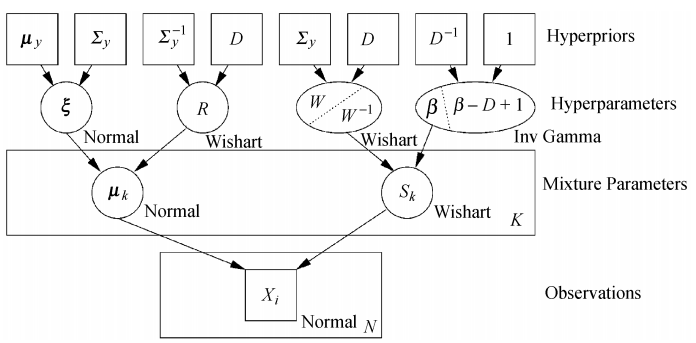
其中$\xi,\rho,\beta,W$是超参数。到这里,这个模型的图可以表达成如下形式:

注意到,上述公式中数据的精度和均值的先验是有连接的,也就是说均值的精度是以多个组件的精度。这并不是我们想要的,因为这意味着某个组件均值的先验以啊来渝这个组件的协方差,但这是要求共轭不可避免的结果。
如果我们将这个依赖关系去除掉,那么,我们就没有了共轭。所以,一个更加现实的模型可以定义如下:
p(\mu_j|\xi,R) \sim \mathcal{N}(\xi,R^{-1})
这里的均值向量$\xi$和精度矩阵$R$对所有的混合组件来说都是一样的。这就使我们得到了一个新的共轭模型,其图模型如下: