简单几步教你如何在搭建并使用DALL·E开源版本来基于文字生成图片
基于文本生成图像是NLP和CV领域这几年非常火热的领域,而OpenAI在2021年发布了DALL·E2和谷歌的大概是第一个大规模预训练模型里专门用来生成图片的模型(这也是一个120亿参数版本的GPT-3,官方说专门用来做text-to-image的)。而最近这段时间,DALL·E2和谷歌的Imagen的出现,展示了更高质量的图片生成模型(OpenAI第二代DALL·E发布,可以使用自然语言创造和编辑图片的模型)。
不过,两家都没有将这些模型公开,OpenAI的意思就是我这玩意太厉害,随便放出来可能会被你们做坏事,而谷歌训练这个应该就是为了云服务挣钱,所以都没有公开可用的版本供大家玩耍。虽然业界有基于论文的实现,但是训练模型需要耗费大量的资源,没有开放的预训练结果,我们普通个人也很难玩起来。但是,大神Sahar提供了一个免费使用开源实现的text-to-image预训练模型的方式。
首先,业界已经有Boris Dayma童鞋开发了开源实现和训练的复刻DALL·E模型的代码。目前已经公开可用的包括DALL·E mini。这个版本已经可以在hugging face上使用了:https://huggingface.co/spaces/dalle-mini/dalle-mini
而这位童鞋的更高级的DALL·E Mega正在训练中,还没完全训练完。不过,这些训练也是耗费钱的,所以即便公开可用,咱们自己机器也很难搞起来。
而Sahar老哥在GitHub上开源的代码可以帮助我们使用已经训练好的DALL·E mini等来搭建自己的text-to-image,一周时间已经有了1.1k的star了。
简单来说,官方的text-to-image不公开预训练模型,业界开源的也需要一定资源才可以,所以这个项目就是让大家可以简单的使用业界已经开源好的内容,创建了一个可视化的界面让大家使用。我体验了一把,相当简单。
一、复制代码到colab
这个项目支持在谷歌Colab免费版本或者你自己机器上载入公开的预训练结果。目前可用的版本包括DALL-E Mini、DALL-E Mega和DALL-E Mega Full。需要的资源如下:
- DALL-E Mini:4GB的GPU,Google Colab免费版可以使用。
- DALL-E Mega:高级版的DALL-E Mini,需要8GB GPU,Google Colab Pro可以支持。
- DALL-E Mega Full:最强的开源版本,需要12GB GPU。
这里给大家演示第一个模型,使用Google Colab免费版。
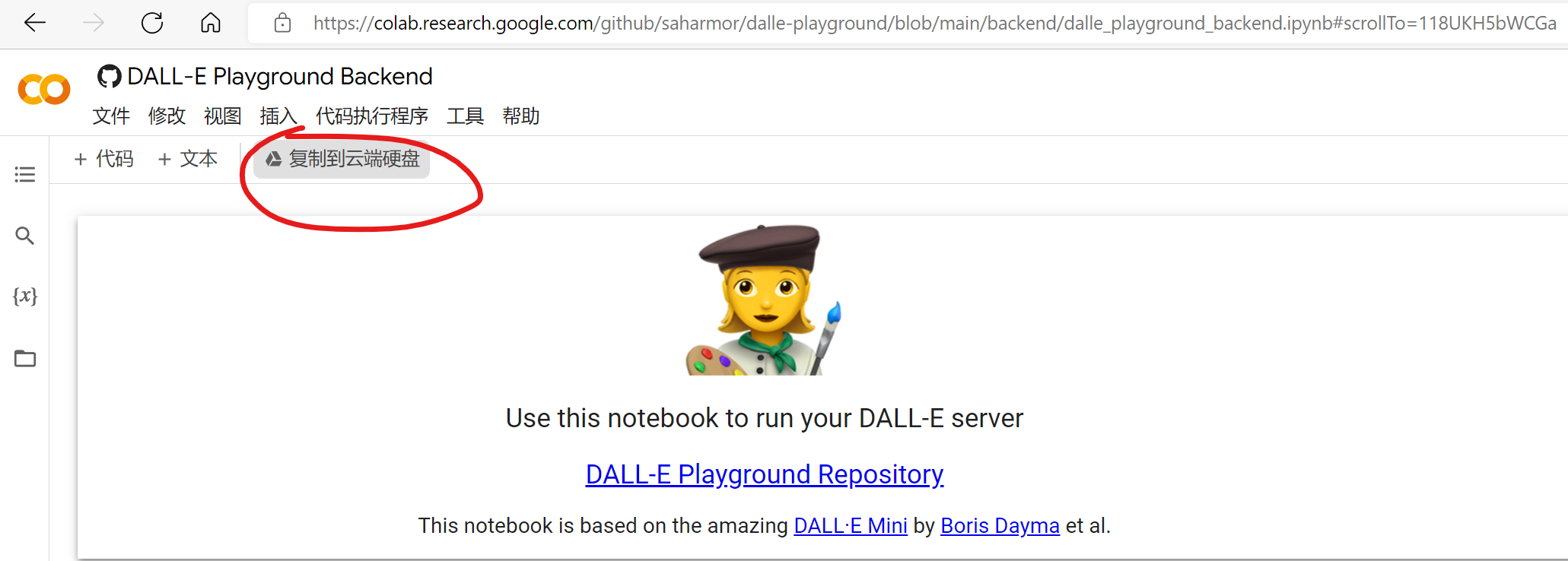
首先,大家打开官方的colab:https://colab.research.google.com/github/saharmor/dalle-playground/blob/main/backend/dalle_playground_backend.ipynb
然后,复制这个项目到你自己的colab即可。点击这个复制到云端硬盘就可以把这个项目引入到自己colab中。等待几十秒之后,完成复制后打开就能到自己的Colab上了,然后可以运行了。
二、在colab上运行代码
首先clone大神的代码,直接点击运行之后会安装环境:
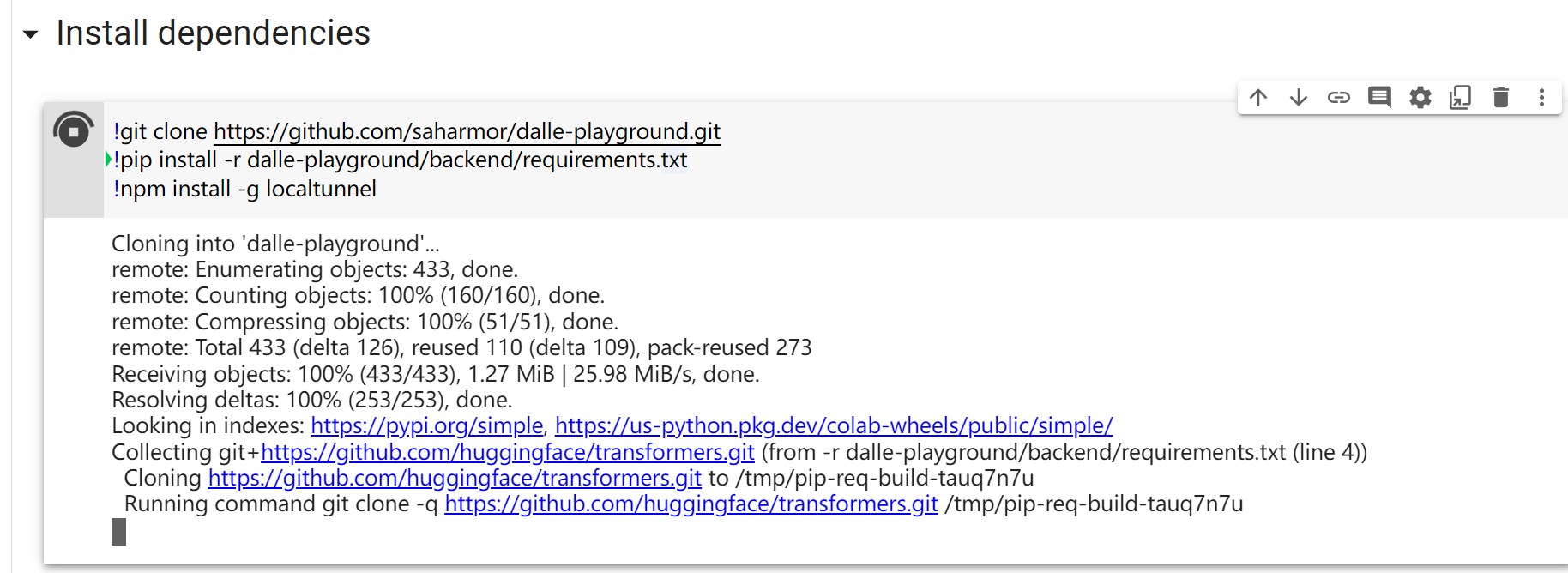
虽然点击运行谷歌会弹窗说你这个免费版本的RAM可能不够用,但是没关系,后面选择DALL·E mini是可以的。
上图也可以看到,大量下载安装依赖。外网的环境最大好处就是他们的依赖下载很快,不像我们,呵呵。
最后这里可能会出现一个错误告警:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. datascience 0.10.6 requires folium==0.2.1, but you have folium 0.8.3 which is incompatible.
没有关系,忽略它,不影响运行。
接下来,选择模型,如果你是免费版本的Colab,那么请选择mini版本,不然是无法运行的。如果你有钱,emmm,要不赞助一点给我?哈哈哈。
开个玩笑继续,选择之后运行这个cell即可。

接下来启动服务器,加载模型
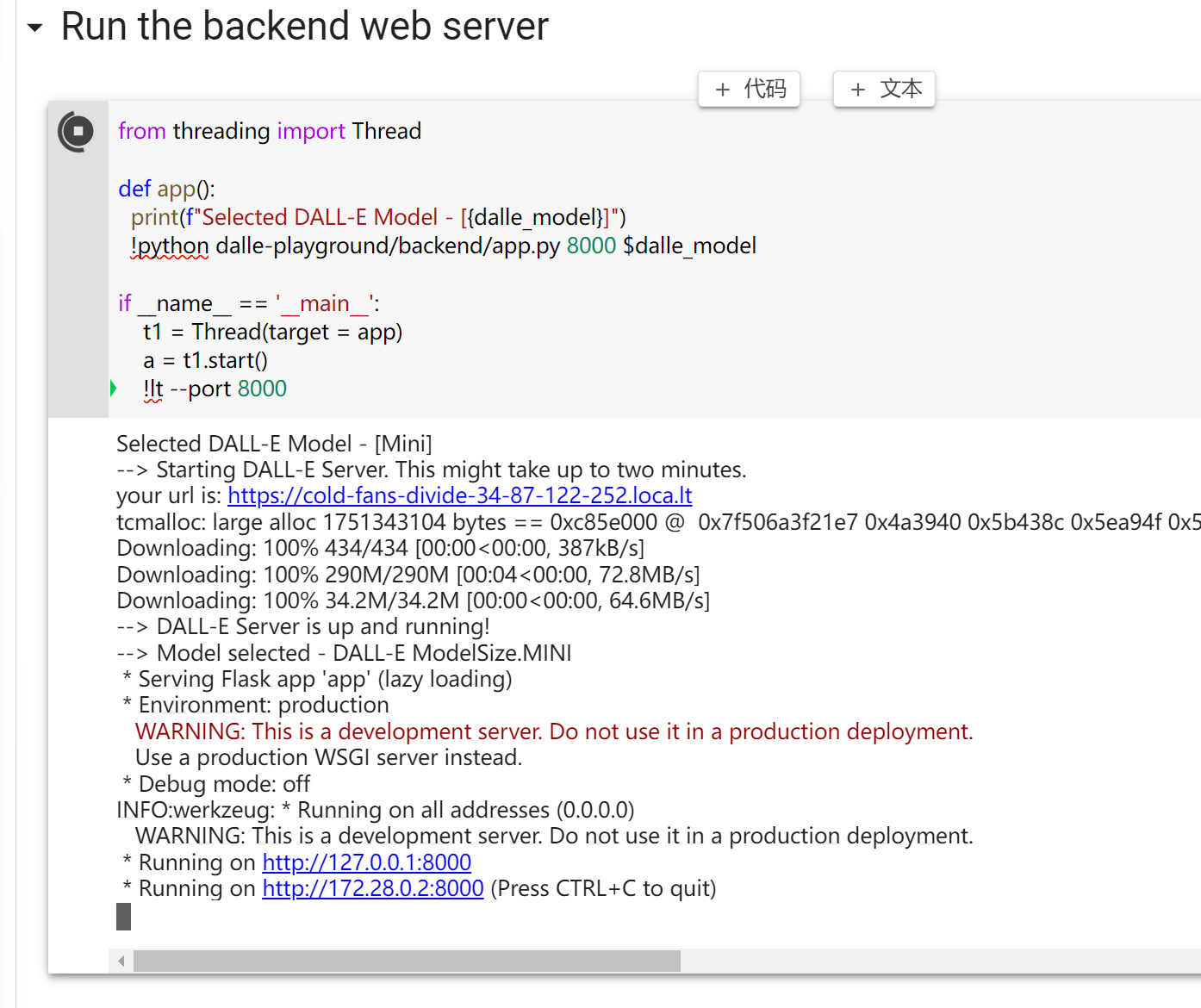
注意,加载mini版本这个步骤需要大概2分钟,所以耐心等一会,直到出现上图结果才可以继续。
接下来打开如下链接:https://saharmor.me/dalle-playground/?backendUrl=https://xxx.loca.lt
但是,需要注意的是上面backendUrl=后面换成上面运行结果出现的那个链接,我这里就是https://cold-fans-divide-34-87-122-252.loca.lt
所以上述链接就是
https://saharmor.me/dalle-playground/?backendUrl=https://cold-fans-divide-34-87-122-252.loca.lt
然后可以看到如下界面:
三、运行结果
我跑了几个看看:
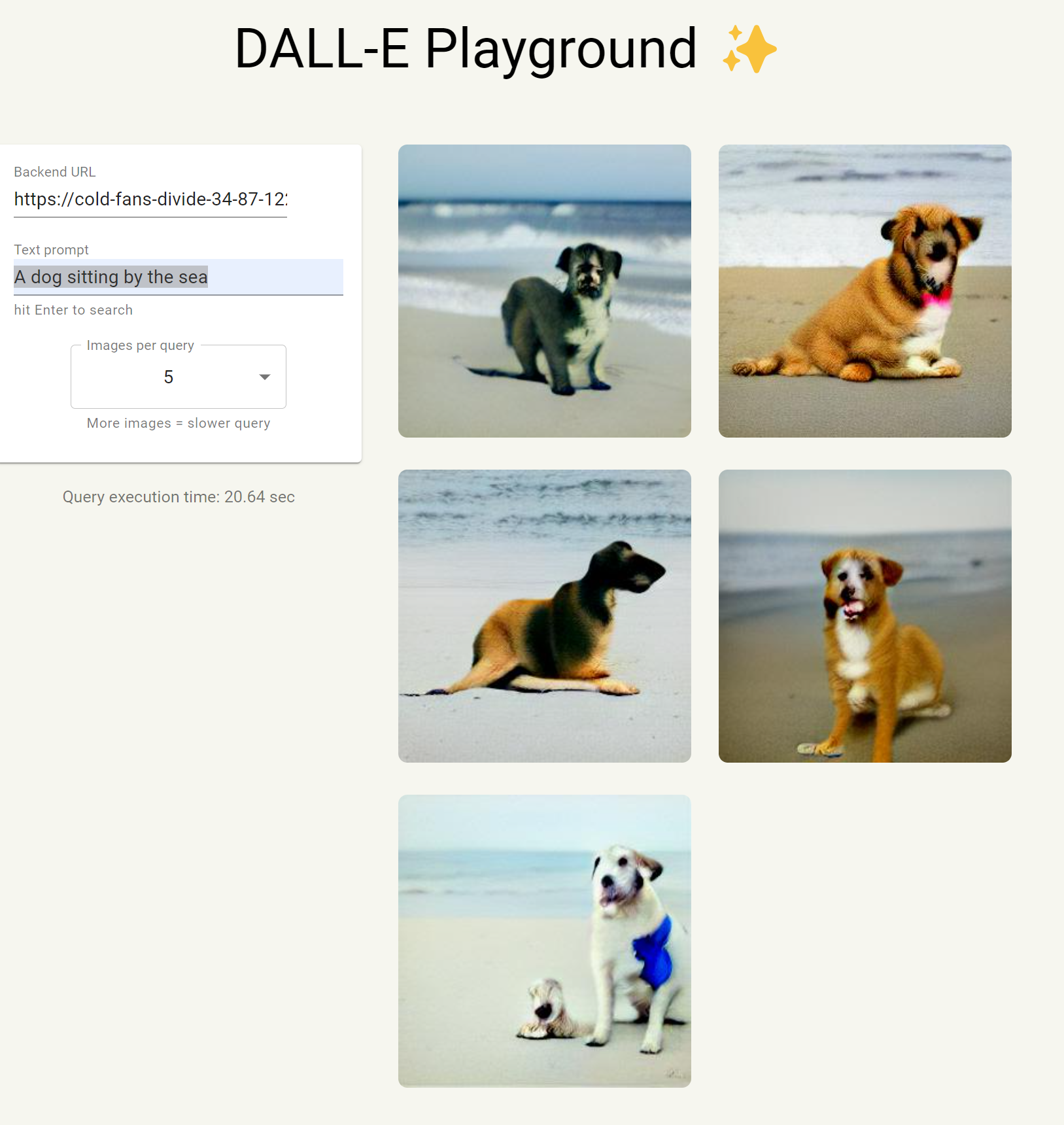
A dog sitting by the sea
A CAT EATING ICE CREAM
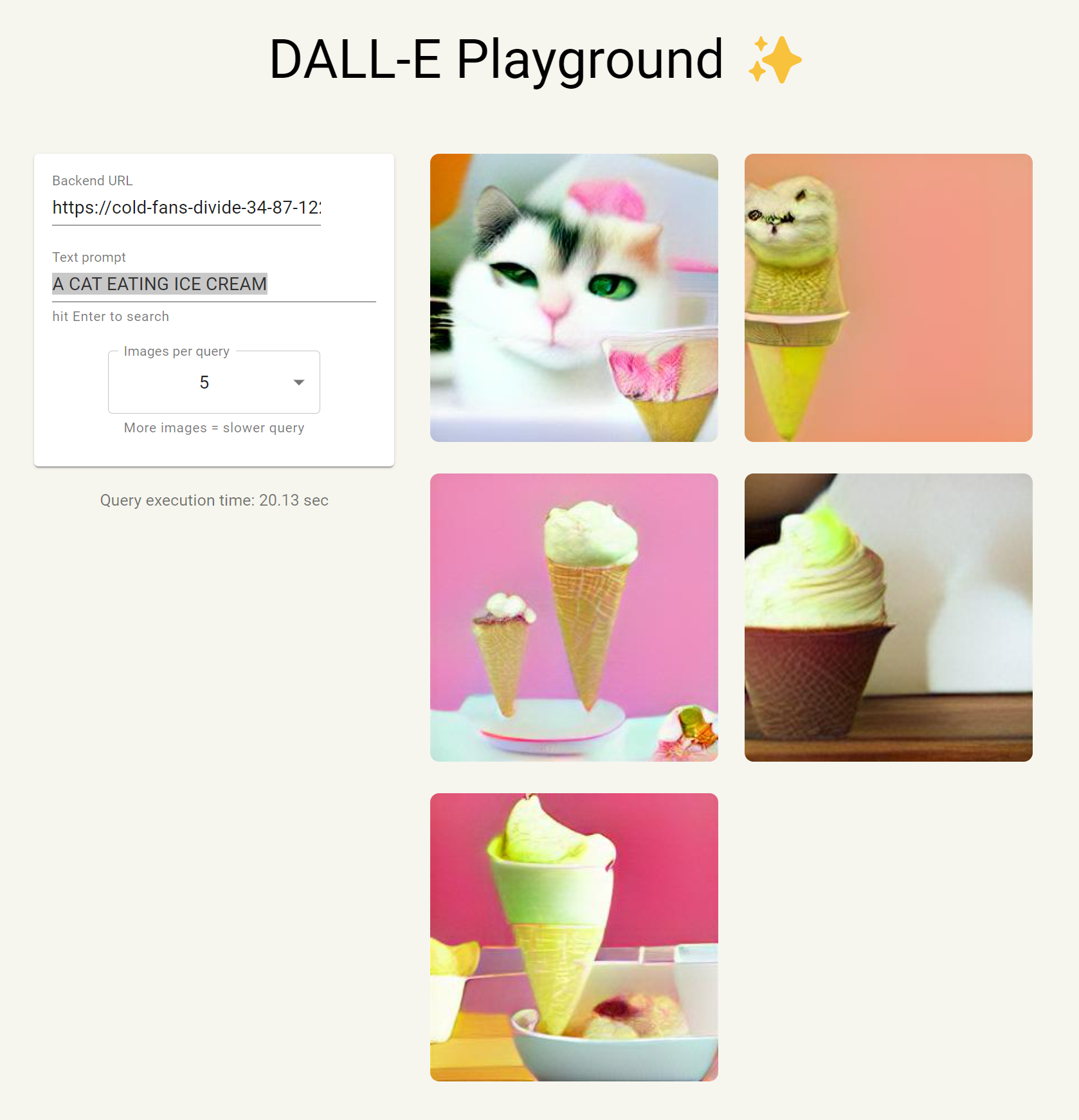
怎么说呢,免费的的确差点意思。不过,如果你有GPU资源可以自己本地运行。只需要你安装了docker和The NVIDIA Container Toolkit就可以了。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
