重磅!ChatGLM2-6B免费商用了~
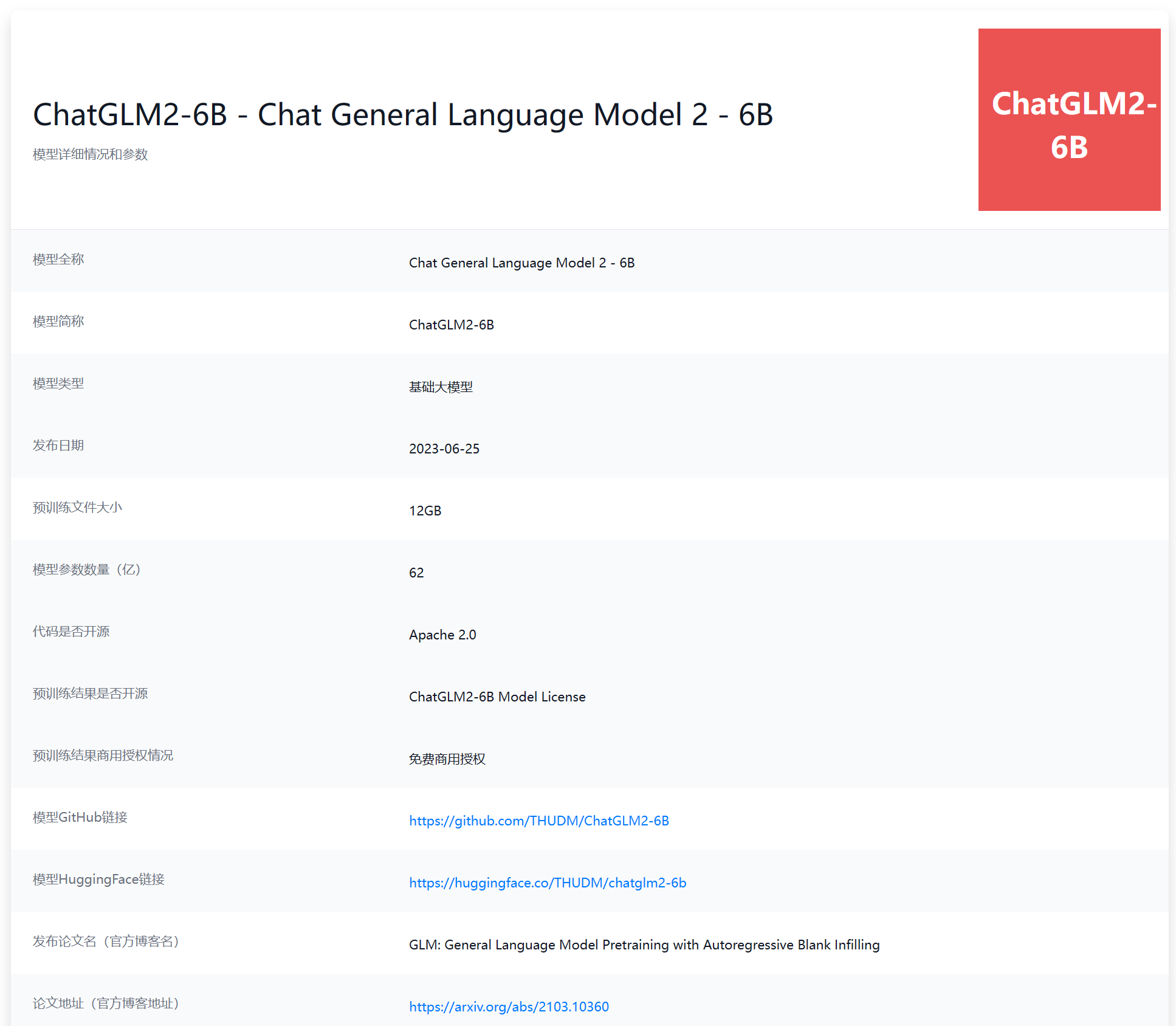
ChatGLM-6B是国产开源大模型领域最强大的的大语言模型。因其优秀的效果和较低的资源占用在国内引起了很多的关注。2023年6月25日,清华大学KEG和数据挖掘小组(THUDM)发布了第二代ChatGLM2-6B。
在七月初,ChatGLM-6B免费商用之后,ChatGLM2-6B宣布免费商用了!

相比较第一代ChatGLM模型,第二代的ChatGLM2-6B的主要升级包括:
ChatGLM2-6B升级1:基座模型升级,性能更加强大
第二代的ChatGLM2-6B的基座模型使用了GLM模型的混合目标函数,在1.4万亿中英文tokens数据集上训练,并做了模型对齐。而测试显示,第二代的ChatGLM2-6B比第一代模型有了很大提升,在各项任务中的提升幅度如下:
| 评测任务 | 任务类型 | ChatGLM-6B得分 | ChatGLM2-6B得分 | 提升幅度 | | ------------ | ------------ | ------------ | | MMLU | 英文语言理解 | 40.63 | 47.86 | ↑ 23% | | CEval | 中文大语言模型评估 | 38.9 | 51.7 | ↑ 33% | | GSM8K | 数学(英文版) | 4.82 | 32.37 | ↑ 571% | | BBH |大语言模型的BIG-Bench Hard任务 | 18.73 | 33.68 | ↑ 60% |
可以看到,第二代模型的性能提升很高。由于第一代的ChatGLM-6B效果已经十分让人惊叹,因此第二代更加值得期待。可以看到,在数学任务上,ChatGLM2-6B性能提升571%!
ChatGLM2-6B升级2:更长的上下文
在第一代ChatGLM-6B上,模型的最高上下文长度是2K。而第二代的ChatGLM2-6B的基座模型使用了FlashAttention技术,升级到32K。而据此微调的对话模型ChatGLM2-6B则可以在8K长度上下文条件下自由流畅进行对话。因此,支持更多轮次的对话,并且官方表示将在后续继续优化上下文长度限制。
ChatGLM2-6B升级3:更高效的推理,更快更便宜!
ChatGLM2-6B使用了Multi-Query Attention技术,可以在更低地显存资源下以更快的速度进行推理,官方宣称,推理速度相比第一代提升42%!同时,在INT4量化模型中,6G显存的对话长度由1K提升到了8K! 这意味着,我们可以用更低的资源来支持更长的对话。甚至是读取更长的文档进行相关的提取和问答。
ChatGLM2-6B升级4:更加开放的协议
ChatGLM2-6B开始发布的时候商用授权协议是30万一年,而7月14日晚上开始完全免费。
需要注意的是,商用授权需要登记,登记地址表单扫描二维码:

大家可以用起来了! ChatGLM2-6B的模型信息卡同步更新:https://www.datalearner.com/ai-models/pretrained-models/ChatGLM2-6B 关于ChatGLM2-6B的其它信息介绍:https://www.datalearner.com/blog/1051687694704581