Baichuan系列大语言模型升级到第二代,百川开源的Baichuan2系列大模型详解,能力提升明显,依然免费商用授权
百川智能是前搜狗创始人王小川创立的一个大模型创业公司,主要的目标是提供大模型底座来提供各种服务。虽然成立很晚(在2023年4月份成立),但是三个月后便发布开源了Baichuan系列开源模型,并上架了Baichun-53B的大模型聊天服务。这些模型受到了广泛的关注和很高的平均。而2个月后,百川智能再次开源第二代baichuan系列大模型,其能力提升明显。
Baichuan2系列模型在各项评测中提升明显:
Baichuan2系列开源模型简介
Baichuan2系列开源模型包含2个参数规模的版本,分别是7B和13B,但是官方开源的模型包含6个:
可以看到,官方开源的模型版本很丰富,包含基础模型Baichuan2-7B-Base/Baichuan2-13B-Base,这是在2.6万亿tokens的高质量数据集上预训练得到的。而在这2个模型基础上,Baichuan还针对对话进行对齐和微调得到了Baichuan2-7B-Chat/Baichuan2-13B-Chat两个聊天优化大模型,此外,还针对模型的显存占用问题发布了2个量化版本的模型,可以在更低的显存资源上运行。
总结一下,Baichuan2系列模型的特点如下:
- Baichuan 2 是百川智能推出的新一代开源大语言模型,采用了2.6万亿Tokens的高质量语料进行训练。
- 该模型在多个权威的中文、英文和多语言的通用、领域benchmark上取得了同尺寸最佳的效果。
- 本次发布包括了7B、13B的Base和Chat版本,并提供了Chat版本的4bits量化。
- 所有版本对学术研究完全开放,开发者可以通过邮件申请并获得官方商用许可后,即可免费商用。
Baichuan2系列模型的训练细节
本次官方还提供了一个技术报告,详细描述了Baichuan2系列模型的训练细节。
Baichuan2大模型训练数据集
关于Baichuan 2的训练数据集和处理方式,可以概括以下几点:
- 数据来源:训练数据来自多种渠道,包括常规网页、书籍、研究论文、代码库等,以求最大程度覆盖不同领域的知识。
- 数据量:原始数据量约为4.6万亿字,经过处理后用于预训练的数据量为2.6万亿字(2.6 trillion tokens)。
- 频率处理:通过集群和去重提高数据频率,构建大规模的近似去重系统,对文本按句、段、文档级别进行聚类和去重。
- 质量处理:对每个文档、段落、句子进行打分,采样时根据质量分数进行加权。
- 清洗处理:设计了一套规则和模型对有害内容进行过滤,如暴力、色情等。
- 采样策略:除常规随机采样外,也提高某些积极价值观数据集的采样概率。
- Token化:使用基于BPE的SentencePiece,扩展词表规模至12.5万,不添加虚拟前缀。
Baichuan2大模型训练数据集组成
可以看出,Baichuan 2在训练数据的选取、处理和采样方面进行了精心设计,旨在构建一个高质量、高覆盖率的多语种预训练语料库。这为模型性能的提升奠定了数据基础。
Baichuan2大模型的架构细节
在原有的技术文档中,Baichuan解释了Baichuan2的训练过程和一些训练细节设置,我们总结如下:
以下是修正后的段落:
好的,我将详细总结论文2.2到2.7章节中Baichuan 2的模型架构和训练细节,并简单解释每一步的设计动机:
- Tokenizer
Baichuan 2的分词器需要平衡两个关键因素:高压缩率以实现高效的推断,以及适当大小的词汇表以确保每个词嵌入的充分训练。为了实现这一平衡,Baichuan 2的词汇表大小从Baichuan 1的64,000扩展到125,696,具体如下:
- 扩大词表规模到125K,增加词汇覆盖范围,提高稀有词表达能力。
- 不添加虚拟前缀,保持输入原始信息。
- 分解数字,增强处理数字语料的能力。
Baichuan2模型与其它模型的词汇对比:
可以看到,baichuan2的词汇表非常丰富!
-
模型结构 Baichuan 2采用了SwiGLU激活函数并对Transformer块的输入使用了Layer Normalization,以提高模型的稳健性和效率。具体如下:
- 使用RoPE或ALiBi位置编码,提高序列外推能力。
- 采用SwiGLU激活函数,效果优于ReLU和GELU。
-
LayerNorm
- 在Transformer块输入使用LayerNorm,与warm-up计划配合效果更佳。
-
优化器 Baichuan 2使用AdamW优化器进行训练,并采用了BFloat16混合精度来提高训练的稳定性和效率。
- 使用AdamW优化器,相比Adam更稳定。
- weight decay可缓解过拟合。
- 梯度裁剪防止异常梯度破坏训练。
-
混合精度
- 使用BFloat16加速训练,相比FP16动态范围更宽。
- 关键操作使用FP32避免数值精度问题。
-
NormHead
- 标准化输出embedding,训练更稳定,分类也更准确。
-
Max-z loss
- 限制最大logit值,使训练和推理都更稳定。
-
分布式训练
- 采用各种通信优化手段,提升分布式大规模训练的时间和性能。
-
推理优化
- 使用转置注意力、张量分割等方式减少内存消耗。
总体来看,Baichuan 2在各个方面都进行了精心设计,这些优化策略提升了模型训练效率、稳定性以及最终性能。
Baichuan2的训练细节
Baichuan 2模型在RLHF训练过程中首先对Critic模型进行了20个training steps的预热。随后,Critic和actor模型都通过标准的PPO算法进行了更新。整个训练过程中,使用了0.5的梯度裁剪、5e-6的恒定学习率和0.1的PPO裁剪阈值。此外,设置了从0.2递减至0.005的KL惩罚系数,并进行了350次的训练迭代,最终得到了Baichuan 2-7B-Chat和Baichuan 2-13B-Chat两个模型。
以下是Baichuan 2模型的训练细节总结:
这是根据3.4小节的内容制作的训练细节表格。如果您需要更多的详细信息或其他部分的概述,请告诉我。
Baichuan2大模型的对齐方法
Baichuan 2的模型对齐方式包括两个主要组成部分:监督微调(Supervised Fine-Tuning, SFT)和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)。在监督微调阶段,使用人类标注员对从各种数据源收集的提示进行标注,每个提示都根据其是否有助于或无害于关键原则进行标记。接着,通过RLHF方法进一步改进结果。此外,还设计了一个三层分类系统,包括6个主要类别、30个次要类别和超过200个三级类别,以确保从用户的角度全面覆盖所有类型的用户需求。
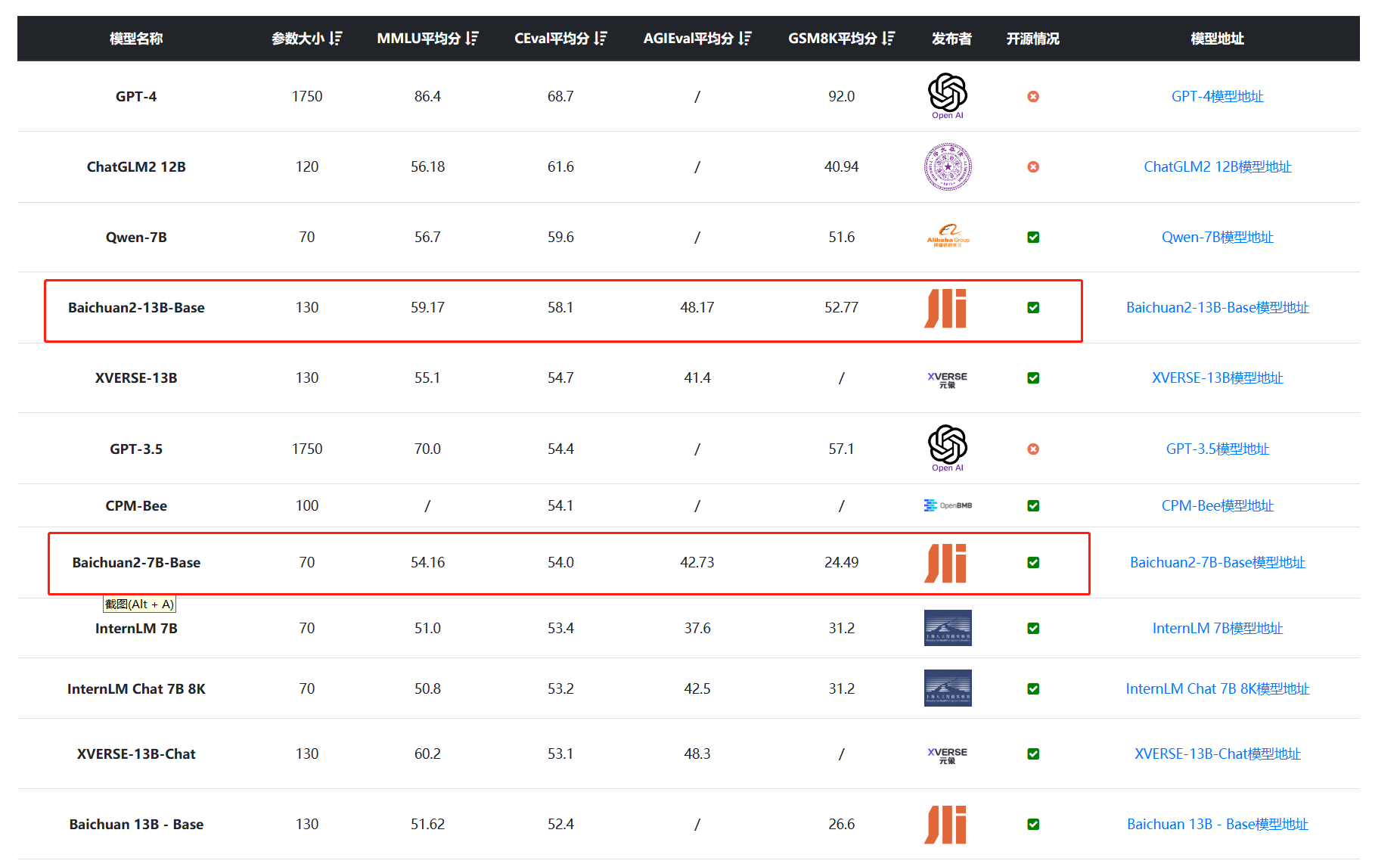
Baichuan2在各个任务的评测结果
Baichuan2给出了非常详细的评测结果,在传统的MMLU、C-Eval、GMS8K等的理解可以参考DataLearner大模型综合评测排行:https://www.datalearner.com/ai-models/llm-evaluation
在代码方面的评测也可以参考DataLearner大模型编程排行:https://www.datalearner.com/ai-models/llm-coding-evaluation
论文的一些具体有意思的对比我们也可以看看。
Baichuan2在医疗和法律领域的评测结果:
Baichuan2在数学和编程能力的评测结果对比:
Baichuan2系列模型的推理硬件(显存)资源要求和限制地址
话不多说,模型资源(包括下载地址、开源协议等)参考DataLearner模型信息卡,评测结果也可以参考DataLearner评测排名收集结果:
而Baichuan2模型所需的硬件资源(显存需求)如下:
可以看到,量化后的模型显存占用极低,Baichuan2-13B的4bit量化仅需8.6GB。
量化后的性能如下:
可以看到,区别并不明显~
