LLaMA2 7B一样的性能但是由15倍的推理速度!Deci开源DeciLM-6B和DeciLM-6B-Instruct,发布一天上榜HuggingFace Trending
随着大型语言模型(LLMs)的不断发展,它们在训练和推理方面的计算需求已经呈指数级增长。这一趋势不仅带来了高昂的成本和能源消耗,还引入了模型部署和可伸缩性方面的障碍。为此,DeciLM开源了2个全新的DeciLM-6B和DeciLM-6B-Instruct大模型,参数比LLaMA2 7B略低,性能相当,但是推理速度却超过LLaMA2 7B的15倍。
这2个模型一发布就上榜HuggingFace的趋势榜,可以说引起了很多的关注。DataLearner目前已经上架了DeciLM 6B的模型信息卡地址,参考如下:
DeciLM-6B模型地址:https://www.datalearner.com/ai-models/pretrained-models/DeciLM-6b DeciLM-6B Instruct模型地址:https://www.datalearner.com/ai-models/pretrained-models/DeciLM-6b-instruct
当前大型语言模型的问题
当前大型语言模型需要庞大的计算资源,高昂的训练和推理成本,以及大量的能源。这不仅使得AI应用的开发和部署变得昂贵,还对环境产生了不小的影响,因为需要大量的能源供应。此外,大型模型也面临着延迟问题,这限制了它们在实时应用中的可用性。在最近的LLM开发中,实现模型性能、计算效率和延迟之间的平衡已成为焦点。
例如,最新发布的LLaMA2模型,尽管其能力有巨大的提升但是推理速度也被大家吐槽很多。很多人反应LLaMA2 70B的推理速度只有12-15 tokens/秒,速度非常慢。
Deci为了解决这个问题,基于SlimPajamas数据集子集进行训练,得到一个全新的开源大模型Deci-LM 6B以及基于此微调的DeciLM-6B Instruct模型,在各方面性能与LLaMA2 7B差不多的情况下,推理速度提升了15倍!
DeciLM 6B的介绍
DeciLM 6B是一款具有独特架构的大型语言模型。它采用了可变的Grouped-Query Attention(GQA)方法,不同于传统的变换器模型。GQA允许在不同的模型层中变化注意力组、键和值的数量,从而在保持效率的同时提高模型质量。此外,DeciLM 6B的架构是使用Deci的AutoNAC引擎生成的,这是一种高效的神经架构搜索引擎。
本次开源的DeciLM 6B包含2个版本,一个是DeciLM-6B基础大模型,一个是基于基础DeciLM-6B进行聊天优化的聊天大模型DeciLM-6B-Instruct。后者使用LoRA微调技术,用OpenOrca数据集微调。
DeciLM 6B的评测结果
DeciLM 6B在各项评测中都表现出色。尽管拥有更少的参数,它在7亿参数类别的开源LLM中依然表现出色,排名靠前。这表明DeciLM 6B在性能和效率方面具有出色的优势。
官方给出了DeciLM-6B在不同评测中的表现。
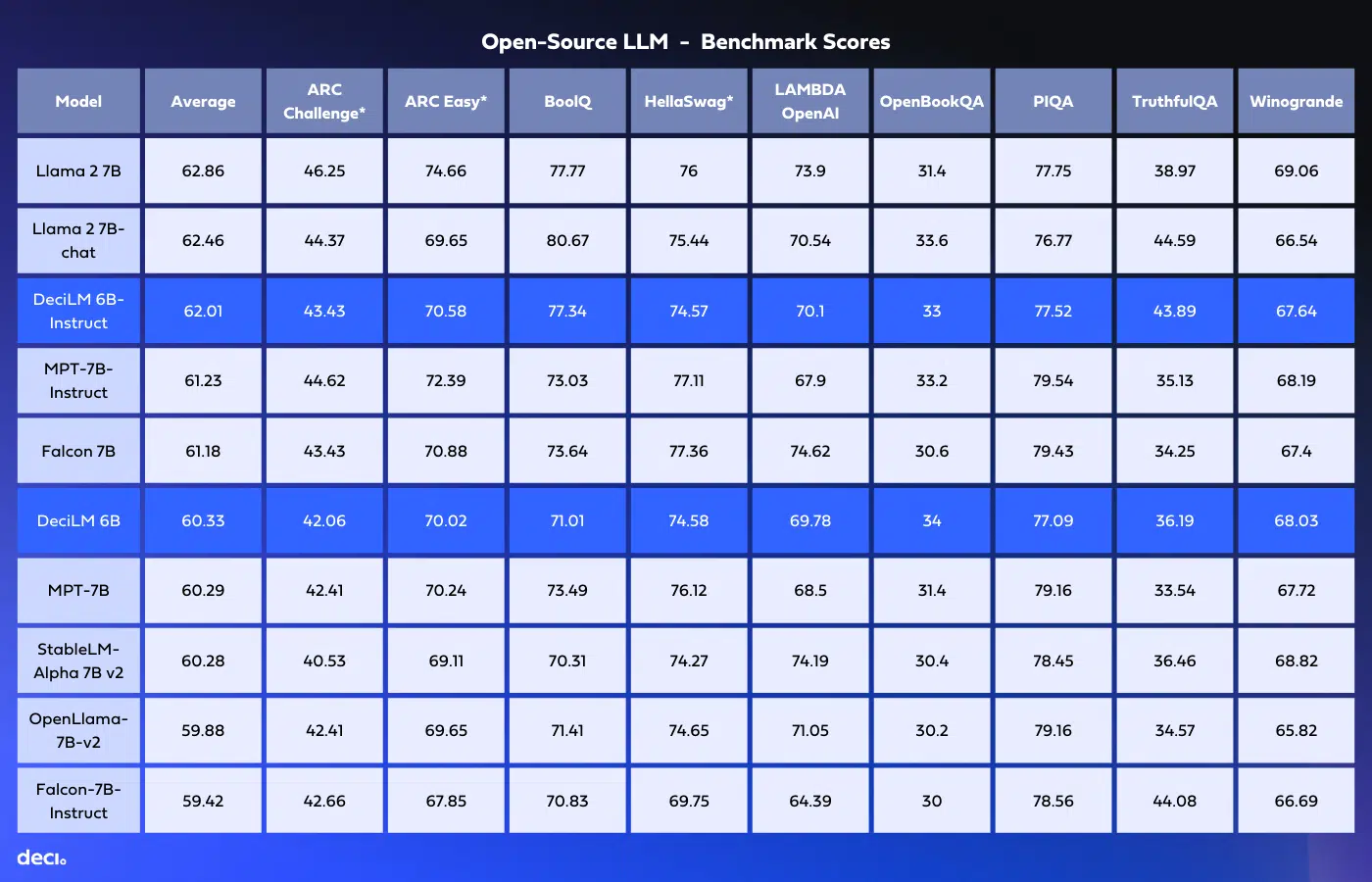
从上图可以看到,DeciLM-6B在同等规模参数的对比中效果都非常好。尽管其参数规模只有57亿,但是性能基本和70亿参数规模的LLaMA2差不多,在70亿参数左右的开源模型中综合评分第三,且仅仅比LLaMA2 7B低1个百分点。
DeciLM 6B的推理速度和吞吐量
其实,DeciLM 6B的模型效果虽然还不错,但还不能达到让人惊讶的地步。DeciLM 6B最大的创新和特点是其极高的推理速度。
与其他模型相比,DeciLM 6B展示了更高的内存效率和更高的吞吐量。当与Deci开发的推理SDK Infery-LLM一起使用时,它的吞吐量甚至可以高达Llama 2 7B的15倍。
下图是DeciLM 6B和LLaMA2 7B模型推理速度的对比。
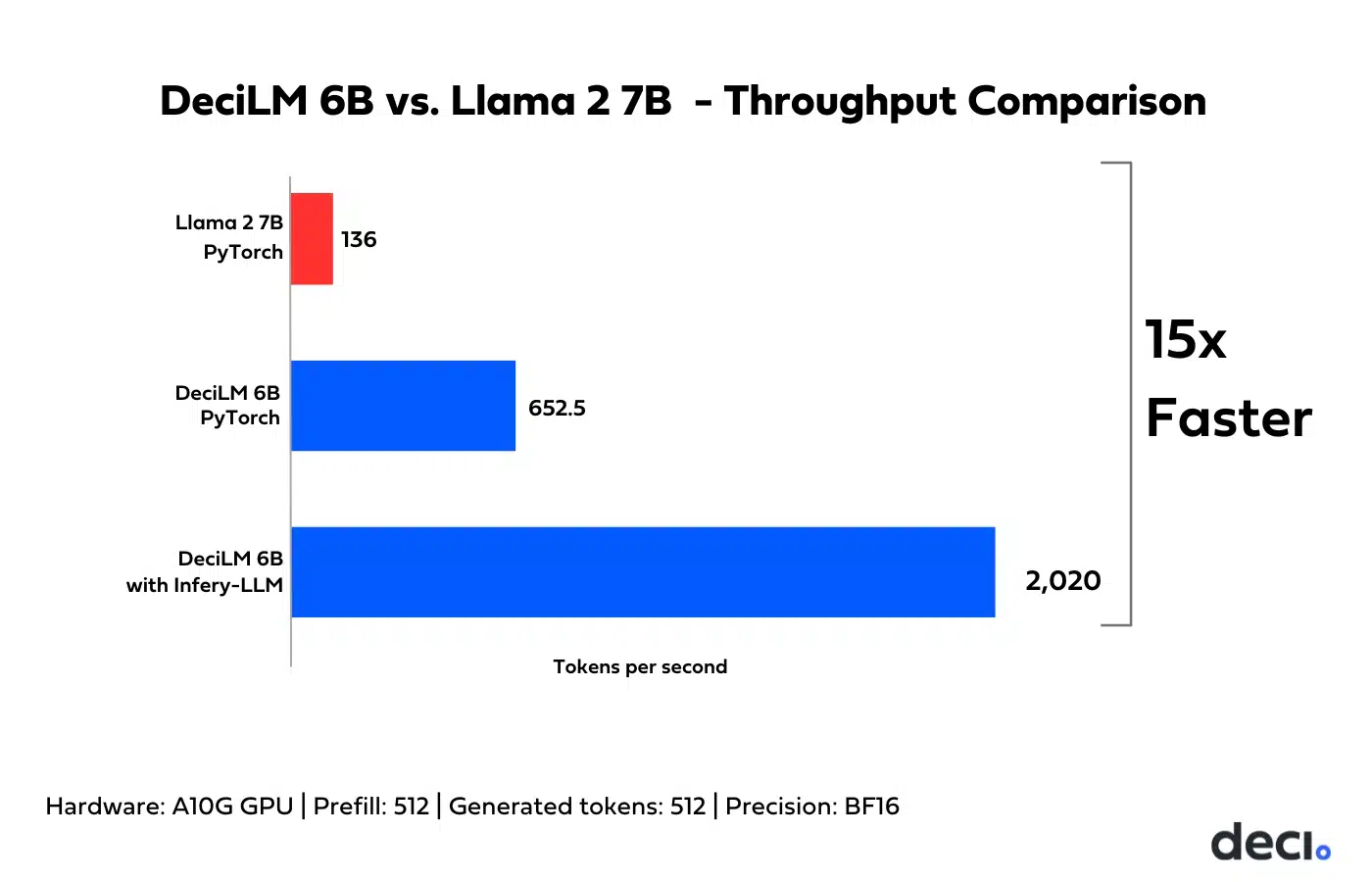
在A10G GPU生成512个Tokens的速度上,基于PyTorch实现的LLaMA2 7B每秒可以生成136个tokens,而基于PyTorch实现的DeciLM 6B的生成速度达到了每秒652.5个tokens,约是LLaMA2 7B的4.8倍!
Deci本身也是一个大模型平台软件,其中一个非常重要的内容是Infery-LLM,这是一个推理SDK,优化了推理速度。在这个框架下的DeciLM-6B的推理速度达到了每秒的2020个tokens!比基准的LLaMA2 7B快15倍!
由于每个模型在生成时的最佳吞吐量点都是在最大批量大小下实现的,因此在基准测试吞吐量时,Deci使用了每个模型的最大可能批次大小对比。结果显示,DeciLM既更节省内存,也具有更高的吞吐量。实验观察表明,DeciLM以批量大小64的方式进行数据处理。相比之下,Llama 2 7B的最大批量大小为8。DeciLM能够处理更大的批量大小,从而在GPU硬件的更有效利用下实现更高效的推断,而不受以前模型的内存限制的限制。
DeciLM 6B的训练细节
而这种效果主要是来自于DeciLM 6B模型架构的创新。
以下是DeciLM 6B的训练过程和特点的表格形式呈现:
DeciLM的架构是使用Deci专有的神经架构搜索(NAS)引擎AutoNAC生成的。传统的NAS方法虽然有希望,但计算密集。AutoNAC通过以高效的方式自动化搜索过程来解决了这一挑战。该引擎在生成多种高效基础模型方面发挥了重要作用,包括最先进的对象检测模型YOLO-NAS、文本到图像模型DeciDiffusion和代码生成LLM DeciCoder。在DeciLM的情况下,AutoNAC对模型的每个变换器层选择了最佳的GQA组参数至关重要。
DeciLM 6B可能是替代LLaMA2 7B的更优选择
当然,这里Deci顺便推广了一下自己的平台。按照HF PyTorch托管的方式计算,使用LLaMA2B 7B处理100万个tokens需要26.66美元,而使用DeciLM配合Infery-LLM处理100万个tokens只需要1.38美元。从这方面看如果LLaMA2 7B满足你的要求,那么使用DeciLM-6B配合Infery-LM应该更划算!
简单解释一下,Infery-LLM是由Deci开发的专门的推断SDK,旨在增强大型语言模型的计算处理能力。基于高级工程技术,如选择性量化和混合编译,以及采用专有的优化内核、快速波束搜索等,Infery是大型语言模型推断加速的重要工具。
DeciLM 6B的开源地址和在线演示地址
DataLearner目前已经上架了DeciLM 6B的模型信息卡地址,参考如下:
DeciLM-6B模型地址:https://www.datalearner.com/ai-models/pretrained-models/DeciLM-6b DeciLM-6B Instruct模型地址:https://www.datalearner.com/ai-models/pretrained-models/DeciLM-6b-instruct
这两个模型都是用LLaMA2的开源协议方式开源,所以可以是免费商用授权,但也需要注意与Deci的竞争关系。下载地址可以参考上述两个DataLearner模型信息卡地址。
官方还提供了一个在线演示地址:https://colab.research.google.com/drive/1LugJCifOv0L426ukRHjOblBRWwUImAit
总结来说,DeciLM 6B代表了大型语言模型领域的一项重大创新,它通过独特的架构和高效的计算方法解决了当前LLM的问题。这不仅提高了AI应用的性能,还降低了成本,减少了对环境的影响。Deci的开源精神使得这一技术对广大研究人员和开发者都是可用的,将进一步推动大型语言模型的发展。DeciLM 6B无疑为未来的高效AI建模提供了宝贵的经验和启示。
