Google Gemini Pro多模态接口开放!DataLearnerAI第一时间测试Gemini Pro多模态能力,比想象惊喜!
Google Gemini是Google最新发布的大模型系列。这是一系列的多模态的大模型,谷歌官方宣布在各项评分中Gemini超过了GPT-4V。但是,谷歌的宣传视频被很多人质疑造假嫌疑,导致被全网嘲讽。而今天,Google官方的Gemini多模态接口开放,DataLearnerAI第一时间申请测试,结果让人惊喜,结论就是Gemini的多模态能力很强。

Google的Gemini简介
Gemini模型是一个系列模型,包含三个不同参数规模的4个模型。
根据官方的提示,这四个模型均为多模态大模型。在今天,Google的Pro版本的多模态接口已经开放,Gemini Pro可以根据输入的视频、图片以及图文混合指令生成文本内容。
DataLearnerAI本次测试的能力包括手写文本识别、图片文本信息json化抽取、视频描述、基于图文few-shot的图片理解几个内容。
手写文本识别
在这个测试中,我们分别用Gemini识别提取图片中手写的文本内容,结果发现英文效果不错,但是中文识别不够(其实难度也很高)。

这是在手机上手写的一个中文结果,最终Gemini返回的如下:
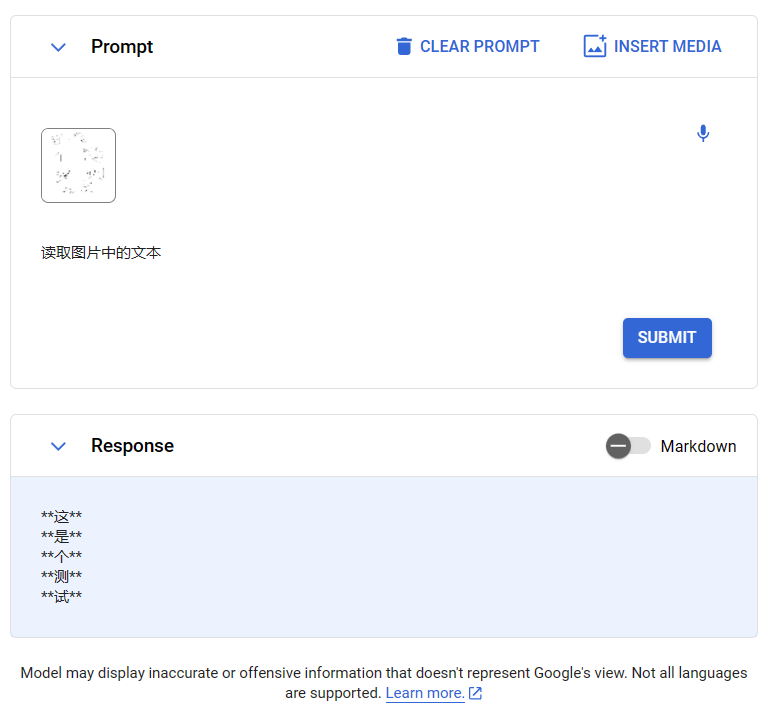
可以,看到漏掉了几个字。但是如果换成英文,则效果不错:

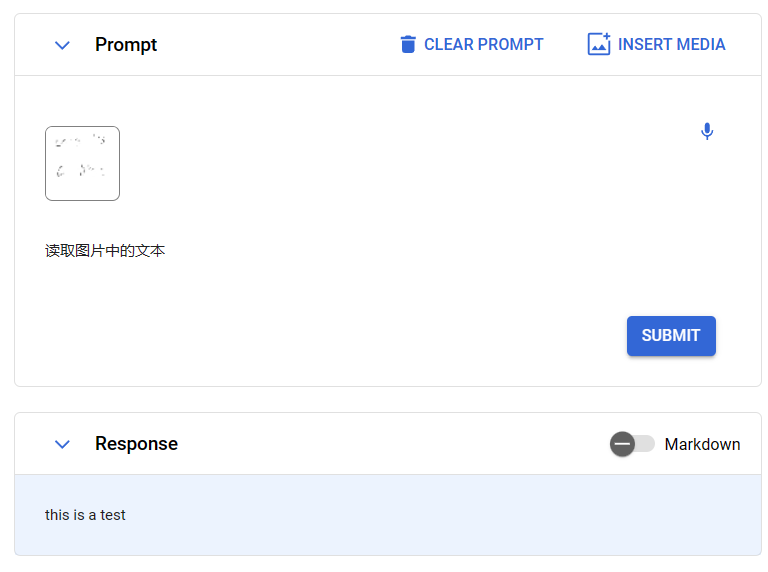
图片信息json格式化提取
在这个测试中,我们从HKT官网截取了一段运营商套餐费用信息,然后使用Gemini提取图片信息,并用json返回,信息提取非常准确,而且可以识别是三个不同的套餐,进而生成了一个数组,包含了三组json:

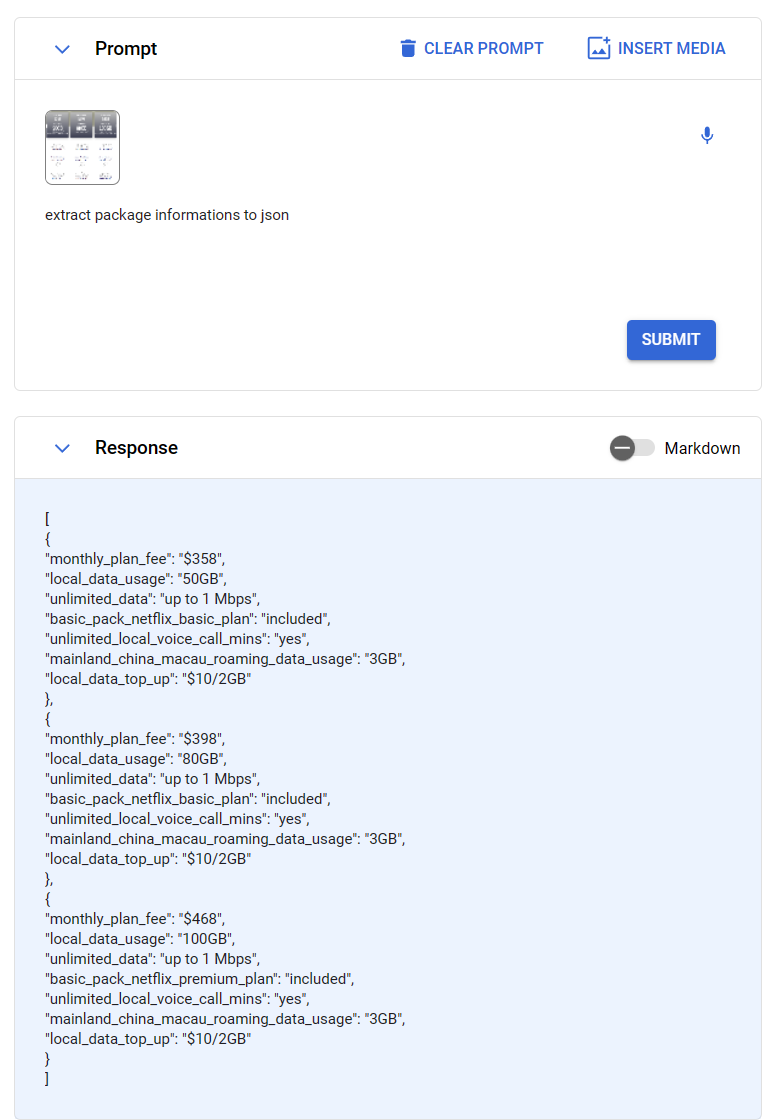
可以看到,尽管这个图片信息密集,但是Gemini可以准确识别其中的逻辑结构,并分组输出。
基于图文few-shot的图片理解
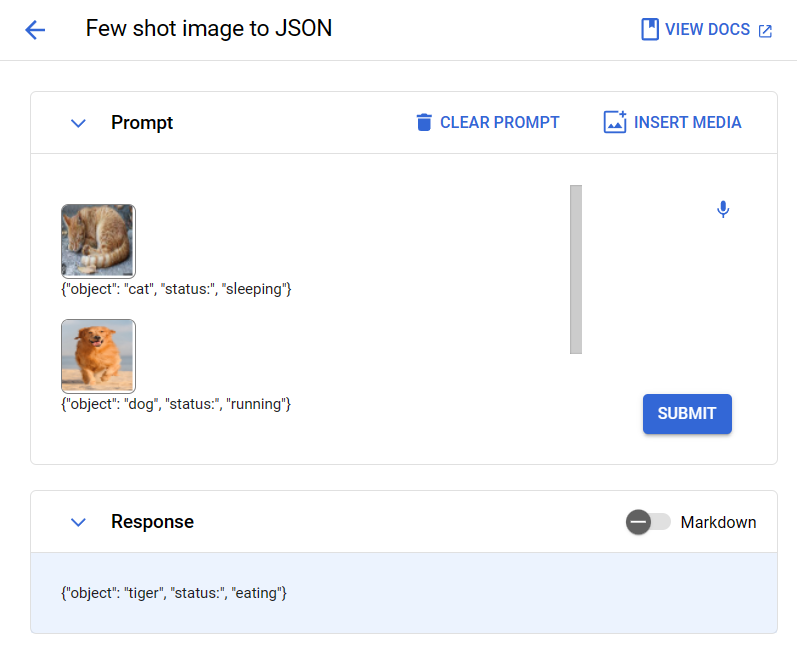
这个测试非常有意思,是一个多模态few-shot案例。就是你先给出2个图文关系,每一个都是一幅图+一个json输出。相当于有2个示例,然后给Gemini一个新的图片,Gemini可以自动理解前面的图文关系,生成新的json文本。在这个测试中,DataLearnerAI先给出了2组图片,分别是睡觉的猫咪和奔跑的狗狗,图是Google截图,类似如下的输入:
[cat.jpg]
{"object":"cat", "status":"sleeping"}
[dog.jpg]
{"object":"dog", "status":"running"}
[tiger.jpg]
最终谷歌的Gemini准确输出了一个在吃东西的老虎。

识别图片中人物(男孩女孩)的数量
这个测试中,我们先用ChatGPT生成了一组在“快乐”加班的人,然后让Gemini数这图中有多少人。

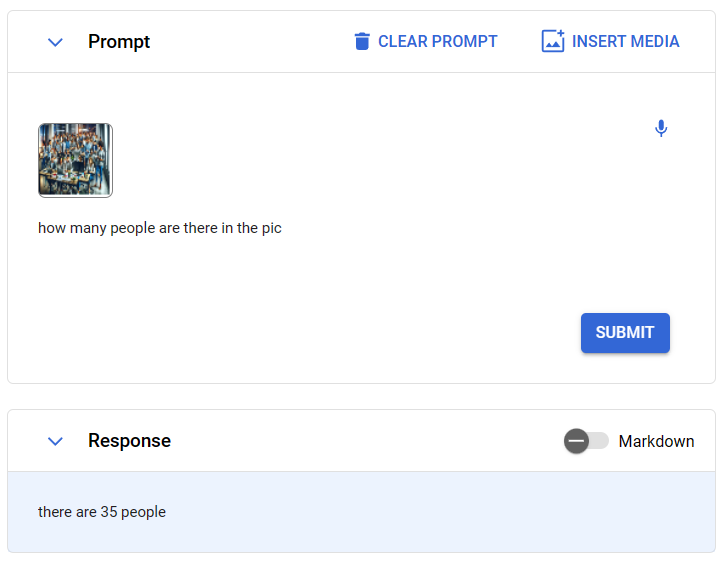
emmm,图片的人很快乐,但是多少人虽然看不太清楚,如果远处的人也算的化,应该是不止35个的。而ChatGPT认为只有20个人!
接下来,我们继续做了一个测试,输入一个图片,让Gemini用json返回图片中男孩和女孩的数量:

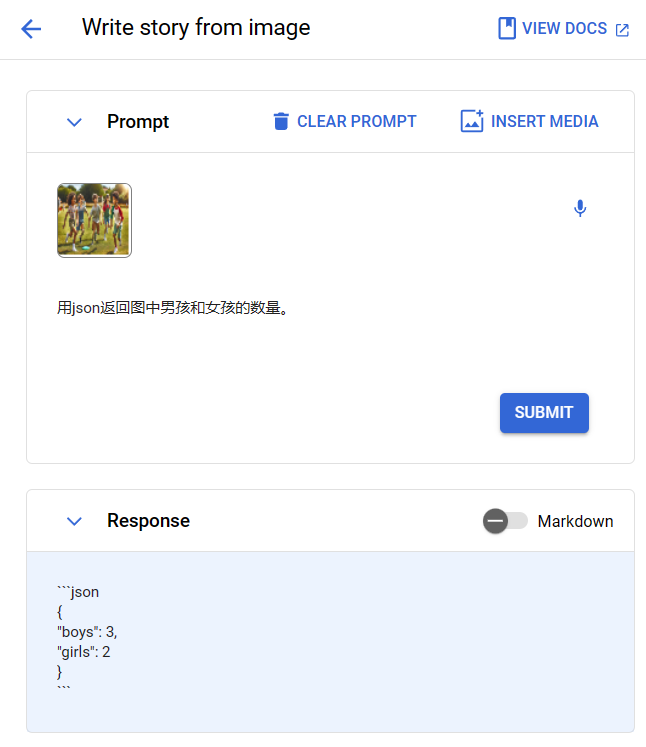
这个结果没有问题!
基于视频生成旅游描述
这一段测试主要是上传了几十秒的南京城市宣传片,让Gemini基于这个宣传片生成一份旅游广告的描述。根据官网的描述,Gemini可以理解视频描述的是什么,里面的人有什么动作或者在做什么,甚至基于视频生成广告描述。但是,我们测试了很多次,该接口都测试失败,遂放弃。
Gemini多模态能力总结
尽管测试不太完美,视频无法处理,但是总体来说还是要比想象好很多,这个能力比目前GPT-4V官方的web版本好用很多,也很准确。而且从实测结果看,可用性很高。值得推荐~
