英伟达在GTC2024大会发布新AI算力芯片:NVIDIA新AI芯片B200的升级是什么?B200与H200对比,它对GPT-4训练和推理的影响是什么?
NVIDIA在2024年GPU技术大会(NVIDIA GPU Technology Conference,GTC)发布了全新的算力芯片和服务,即基于最新的Blackwell架构的算力芯片B200和GB200服务器。但是,大多数人对于NVIDIA芯片的升级只有数字的变化,本文将针对NVIDIA的GPU算力芯片做简单的介绍,并说明NVIDIA B200以及GB200的升级的地方。

大模型训练关注的NVIDIA的GPU芯片参数
英伟达的AI芯片,如A100、H100是当前训练大模型最强大最主流的芯片。但是,大多数人并不是很清楚A100、H100上影响大模型训练效率和性能的参数。为了清楚本次B100芯片的升级之处,我们先对英伟达芯片的几个技术指标进行解释。
显存大小
首先是GPU的显存大小。这个不用多解释,主要影响了单个GPU可以载入的模型大小,越大的显存可以载入更多参数的模型,也就是可以训练更大的模型。而显存除了大小以外还需要关注显存的类型。在H100系列芯片上,最早采用的是HBM3类型的显存,而在后续的H200芯片上,英伟达为其配备了HBM3e的显存,显存带宽和大小都有提升。
显存带宽
其次是显存的带宽,如前所述,显存大小影响可以载入的模型参数量,而显存带宽是GPU读取数据的速度,影响的是训练和推理的效率。HBM3e的显存带宽比HBM3更高。可以把显存带宽理解为单个GPU内部读写数据相关的性能。
单个服务器内多个GPU互联的NVLINK
然后是NVLINK互联技术,这是英伟达独家的互联技术,在英伟达GPU芯片上使用,主要是用于单个服务器内不同GPU的互联。如前所述,显存大小影响可训练的模型大小,但是单个GPU不可能无限大显存,多个GPU显存一起互联虽然可以提供更大的显存,但是互联的速度不如GPU读取自己的显存快,传统多个GPU之间用PCIe等技术互联,速度比较慢。英伟达的NVLINK可以提供更快的速度。因此,每次NVLINK速度的提升也都会提升英伟达芯片整体算力。但是单个服务器不可能无限多的芯片互联,此前,单个服务器内最多只有8个GPU可以通过NVLINK互联。
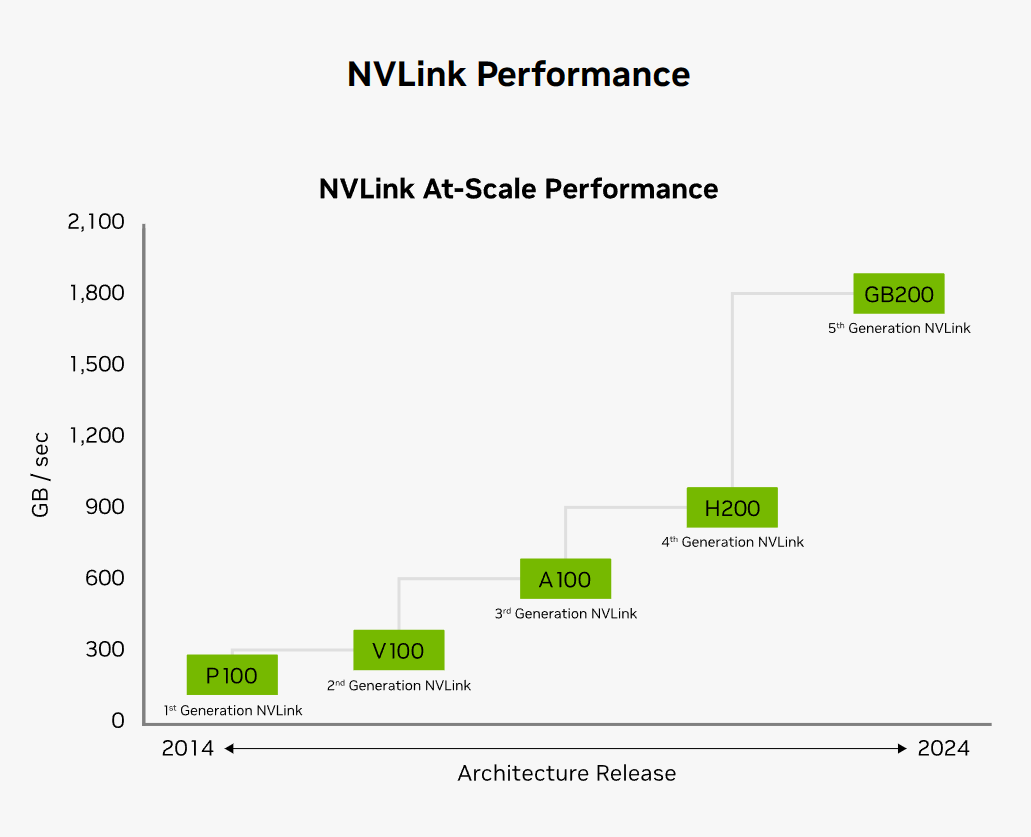
如上图所示,最新的Blackwell使用第五代NVLINK互联,带宽增长的同时,最多互联的GPU数量也大幅提高!
不同服务器的GPU之间的互联技术NV Switch
为了满足更大模型的训练需求,不同服务器之间也可以通过NV Switch互联获得更大的集群,以获得更大的算力。这部分NVLINK无法使用,所以英伟达开发了NV Switch技术。
从上面的描述可以看到,GPU算力是朝着更大的显存、更快的带宽前进的。而为了让更多GPU一起组成更大的集群,GPU带宽、单服务器内多个GPU互联带宽以及不同服务器之间GPU互联带宽都要更大才可以。理解了这部分我们就可以理解本次英伟达B100的芯片和GB100的升级了。
英伟达芯片的分类
在介绍B100的升级之前,我们再简单介绍一下英伟达芯片的分类。
英伟达GPU微架构分类
首先是英伟达的GPU有微架构的划分。每一代英伟达微架构都会延伸出不同的芯片型号。从V100开始,英伟达系列芯片架构总结如下:
可以看到,几乎每隔2年,英伟达芯片的微架构就会更新一代。也会推出相应的产品。注意,消费级显卡如3090、4090也是采用类似架构,但不属于本文讨论范围。而微架构部分基本上就定义了NVLINK带宽、相应绑定的技术等。
英伟达H100系列芯片区别
H100是基于Hopper架构开发的GPU芯片。从H100开始,英伟达的算力芯片有了更多的种类划分,主要分为H100和H200两类,前者是基于HBM3显存开发的,后者则显存类型升级到了HBM3e。
H100是NVIDIA第一个Hopper架构的芯片,其基本的规格显存是80GB(HBM3类型的显存),但是区分2个版本,一个是PCIe类型的接口,一个是SXM类型的接口,也就是物理接口形式不同。其中PCIe接口的卡在计算能力和带宽方面略低于SXM。H100还有一个类型是H100 NVL版本,它升级了显存,大小升级到94GB,又由于不单卖,而是两个通过NVL LINK连接后一起卖,所以一般规格都写188GB显存。
在H100基础上,NVIDIA推出了H200系列。相比较H100,H200最大的升级是显存类型由HBM3升级到了HBM3e,单GPU显存容量达到141GB,带宽也从HBM3的3.35TB/s升级到了4.8TB/s。而H200则只有SXM版本。
DGX GH200产品
此外,英伟达还基于ARM架构开发了自己的CPU芯片,即Grace系列,为了让自己服务器更完整,他们开发了GH200系列,即绑定了自己CPU和GPU的芯片服务器。一般称为DGX GH200,其中DGX是英伟达服务器或者工作站产品的名称。G是指Grace CPU,而H200表明配比的是H200的GPU。
有了上面的概念,我们再来看本次B200和GB200到底升级了什么。
英伟达B200以及GB200升级了什么?
Hopper架构的H100系列都采用第四代NVLINK技术,也就意味着单个服务器内最多可以有8个H100的GPU,也就是8个H100 SXM或者8个H100 PCIe或者4对H100 NVL。
B200的发布跳过了此前H100系列,直接对标的是H200和GH200产品,也就可以理解为B200是基于HBM3e显存开发的,而GB200则是配了Grace CPU和B200 GPU的产品。其次,由于NVLINK发展到了第五代,NVLINK可以互联的GPU数量也从单台服务器8个增加到单个机架都可以通过NVLINK互联,支持最多72个B200的GPU互联!所以英伟达称之为GB200 NV72。此前NVLINK都是单个服务器内GPU互联技术。显然单个服务器不太可能装72个GPU,所以NVLINK拓展到了机架式设计的服务器,采用液冷散热!
H100系列、H200与B200对比
尽管此次英伟达没有为B200芯片单独描述,但是从GB200 NV72的规格我们也可以推算出相关的参数。那么H100系列、H200系列和B200系列参数对比如下:
| | H100 PCIe | H100 SXM | H100 NVL(2个叠加) | H200 | B200* | | ------------ | ------------ | ------------ | ------------ | ------------ | | 单GPU显存 | 80GB | 80GB | 94×2=188GB | 141GB | 192 GB| | 单NVLINK域显存 | 640GB | 640GB | 752GB | 1128GB| 13.5 TB | | 单GPU显存带宽 | 2TB/s | 3.35TB/s | 3.9TB/s×2=7.8TB/s |4.8TB/s| 8 TB/s| | NVLINK带宽 | 600GB/s | 600GB/s | 900GB/s | 900GB/s | 1.8TB/s| | 单GPU的FLOAT32算力 | 51 TFLOPS | 67 TFLOPS | 67 TFLOPS×2=134TFLOPS | 67 TFLOPS| 2560 TFLOPS | | 单GPU的FLOAT16算力 | 1513 TFLOPS | 1979 TFLOPS | 1979 TFLOPS×2= 3958 TFLOPS | 3958 TFLOPS| 5120 TFLOPS |
可以看到,单个GPU来说,B200在显存大小、显存带宽上都有较大的提升。而NVLINK的提升更加明显,最终导致GB200组网的单NVLINK域内有巨大的提升。
需要注意的是,此次发布的GB200 NV72的核心是GB200 Grace Blackwell Superchip,这是类似H100 NVL那种将2个H100通过NVLINK叠加的芯片,是成对的!
对于H200 SXM来说,最多8个GPUs在单个服务器内。所以,按照单个服务器内最多8个H100 Tensor Core核心GPU组网,而GB200 NV72则直接可以用72个B200 GPU来NVLINK互联,整体性能提升巨大。它们能力对比如下:
从这个对比我们就能看出GB200 NV72的升级了。这也为什么英伟达说现在可以一个服务器训练更大规模的模型了。在单个GPU性能增长的同时,大幅提高了单NV LINK域的服务器的显存和带宽。而单个NV LINK域内虽然是多个GPU组成的,但是由于NV LINK超高的带宽,理论上可以当作一个巨型的虚拟GPU看,所以才有这暴涨的性能。
GB200 NVL72的性能提升总结——以GPT-4为例
在GTC大会上,英伟达透露了说GPT MoE架构的模型有1.8万亿参数,与此前的GPT-4泄露的信息一致(参考:未经证实的GPT-4技术细节,关于GPT-4的参数数量、架构、基础设施、训练数据集、成本等信息泄露,仅供参考)。在最新的GB200 NV72集群上,GPT-4的训练速度可以快4倍,而单GPU的生成速度可以提升30倍,从每GPU每秒3.5个tokens达到每GPU每秒116个tokens。
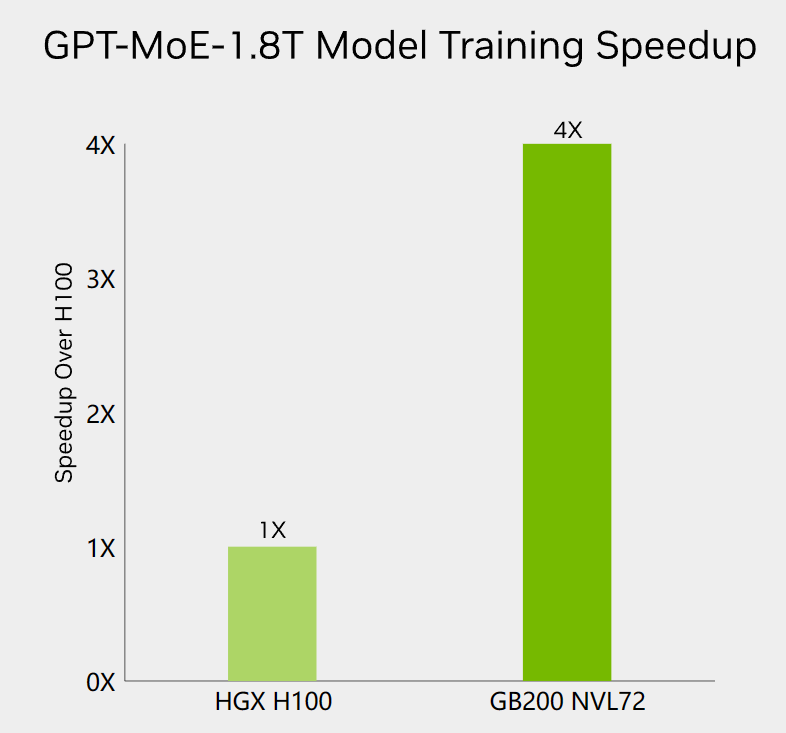
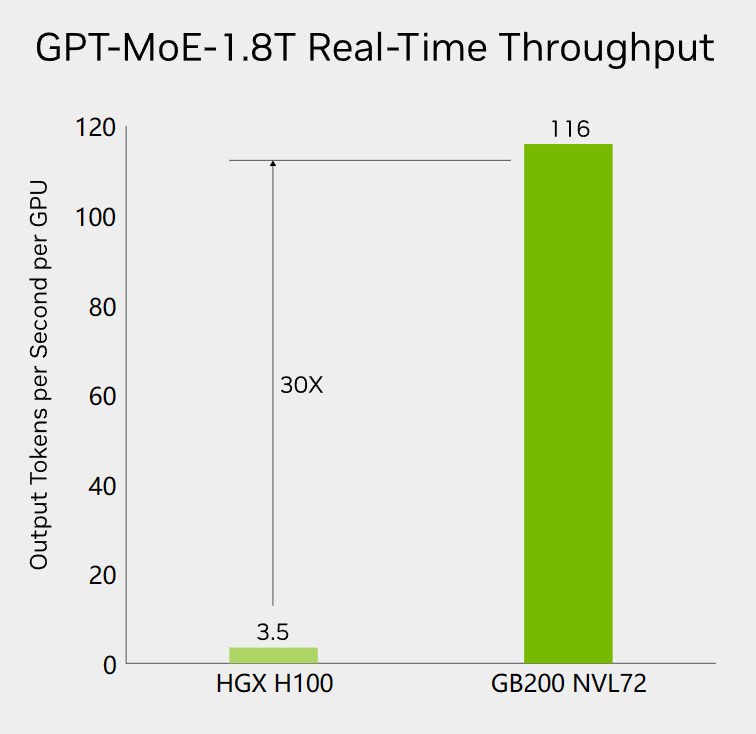
根据Artificial Analysis的统计,官方GPT-4的生成速度是每秒23个tokens左右,考虑到HGX最多8个GPU通过NVLINK互联,说明GPT-4可能正好由一个HGX集群托管进行推理(HGX和DGX一样,是配备了8个GPU的服务器,DGX是英伟达自己的服务器,HXG是其它厂商提供的配备8个英伟达GPU的服务器)!而GB 200 NVL72速度提升30倍意味着一旦OpenAI采用了新的集群,ChatGPT的服务将大幅提速!
此外,从GPT-4训练的资源看,英伟达的卡训练资源和时间也将大幅降低: 2.5万个A100训练3-5个月; 8000个H100训练3个月; 2000个B100训练3个月;
这意味着OpenAI可以更快地训练出GPT-4一样的模型,也可以训练比GPT-4大得多的模型!
