Grok3发布!马斯克旗下大模型企业xAI发布Grok3、Grok3-mini,支持Deep Research、语音交互和“思考”模式的推理大模型,推理模式评测结果全球最强
今天马斯克旗下的xAI公司发布了最新一代大语言模型Grok3,基于20万张GPU集群训练,各方面的提升都非常明显。在主流评测上都超过了现有的大模型。
Grok-3系列模型介绍
Grok-3系列模型分为2个版本,分别是Grok-3和Grok-3 mini,官方没有公布参数等信息。这两个版本的模型都支持推理模式,其中Grok-3 mini的Reasoning版本已经训练完成,而Grok-3 Reasoning目前是beta版本,并未正式发布。
Grok-3系列模型应该是普通的大模型和推理大模型的结合。其推理模式可以使用更长的推理时间和tokens来完成更加复杂的任务。但是官方没有给出不同的版本名称,也不确定是独立的推理大模型还是2种模式都支持的大模型类型。
根据马斯克透露的消息,当前xAI已经建成了20万卡集群的算力中心。从0开始搭建10万的集群用了192天,但是10万到20万集群的扩展只用了90多天时间,可见基础设施的扩展非常顺利且更为迅速。尽管,此前DeepSeek系列模型可以通过更低的训练成本完成高质量大模型的训练,但是马斯克的模型结果证明,更大更强的算力始终是有优势的。
评测结果大幅超过GPT-4o,打败了所有非推理模型
官方给出了Grok-3系列模型在不同评测的对比结果。主要是数学推理(AIME 2024)、科学事实(GPQA)以及编程(LCB)方面的评测结果。它们简单介绍如下:
AIME 2024:AIME全称是American Invitational Mathematics Examination,即美国数学邀请赛,是美国面向中学生的邀请式竞赛,3个小时完成15道题,难度很高。详情参考:https://www.datalearner.com/ai-models/llm-benchmark-tests/37 GPQA:这里的测试应该是GPQA Diamond,基准旨在衡量模型在需要深度推理和领域专业知识问题上的能力,详情参考:https://www.datalearner.com/ai-models/llm-benchmark-tests/32 LCB:这应该是Leet Code的测试,测试代码生成能力。
官方将Grok-3系列分为2个版本来对比,分别是经典的大语言模型能力和推理大模型的能力。
非推理模式的Grok-3与其它大模型能力对比
下图展示了Grok-3在非推理模式下与其它大语言模型的评测对比。
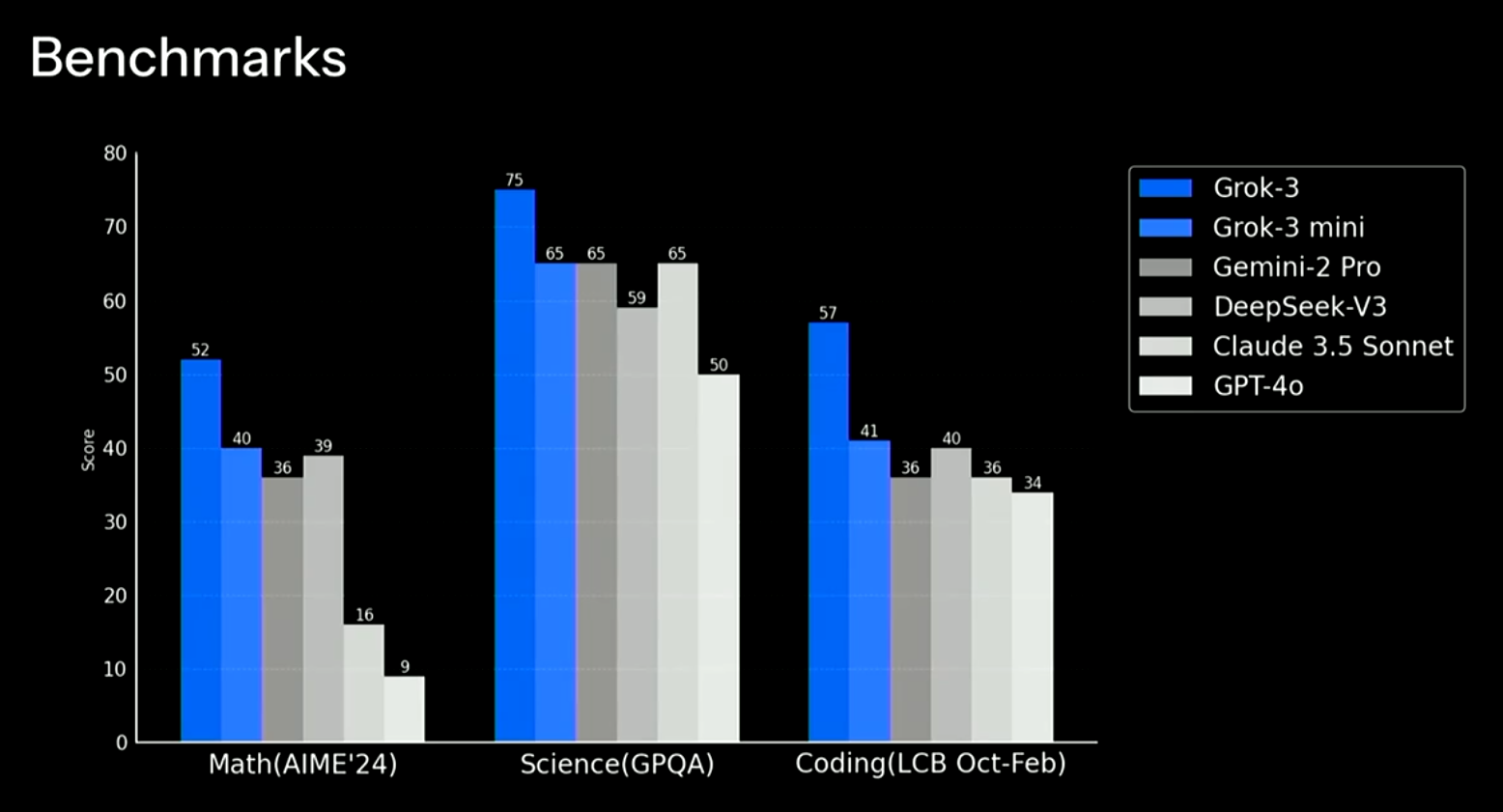
根据上图我们可以看到,传统的大模型对比上,Grok3评测结果很好。在数学评测上,即使是小版本的Grok-3 mini,得分也达到了40分,超过了6710亿参数的DeepSeek V3。而在专业推理GPQA的得分上,也超过了其它模型。Grok-3模型比GPT-4o高50%,性能十分恐怖。
推理模式的Grok-3与其它大模型能力对比
前面是非推理模式下Grok-3与其它模型的对比。但是,随着OpenAI o1/o3系列推理大模型的推出,这些评测并不能代表最新的水平。但是,这也是通过增加推理时间,生成更多tokens来获得的效果。而Grok-3本身也是支持推理模式的。其中Grok-3-mini Reasoning是已经完成训练,而Grok-3版本目前还没有训练完成。
下图展示了Grok-3推理版本模型与其他模型的对比结果。
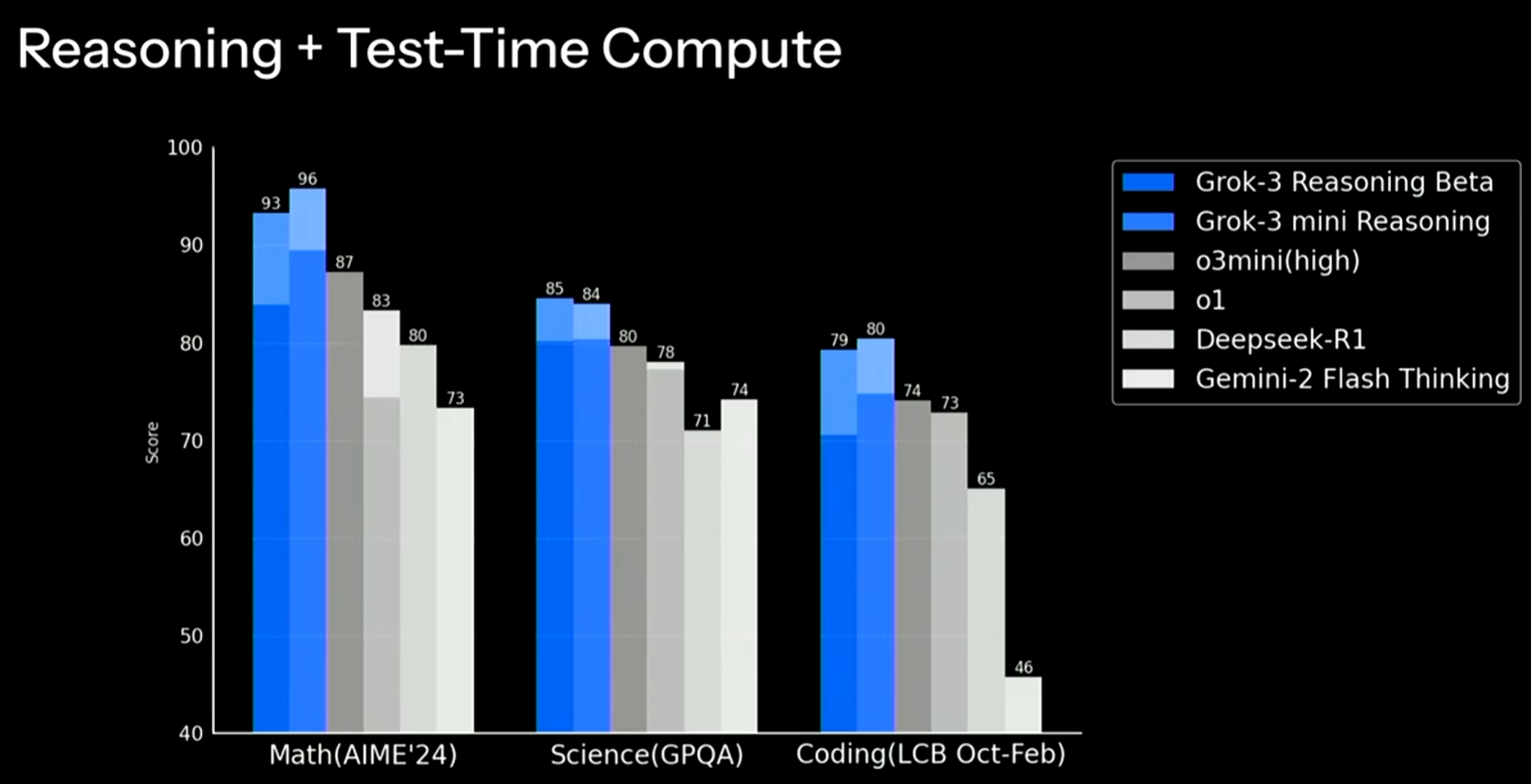
可以看到,推理版本的Grok-3系列依然是超过了其它推理大模型的效果。这里浅色部分应该是用更长的推理时间获得的。但是可以看到,Grok-3 Reasoning Beta应该是训练还没有结束,所以才导致了效果似乎没那么好。而Grok-3 mini reasoning则是最强的。
Grok-3系列所有模型在一起的测试结果
为了更加清晰对比Grok-3模型和其它模型的对比结果,我们DataLearnerAI汇总了所有的大模型对比:
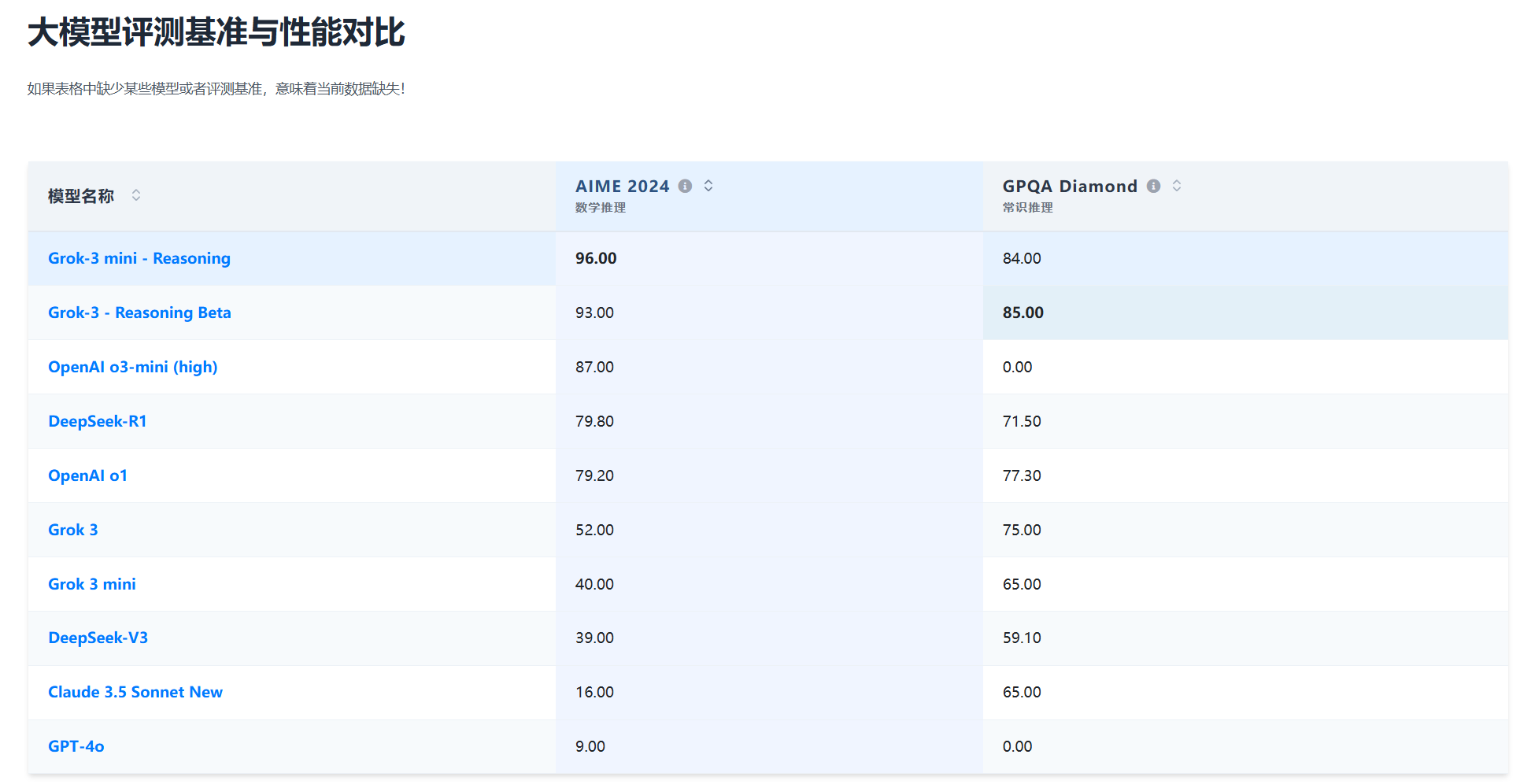
基本上Grok-3依然是最强的。此外,在Chatbot Arena大模型竞技场上,Grok-3也是最强的,是迄今为止唯一超过1400分的大模型:
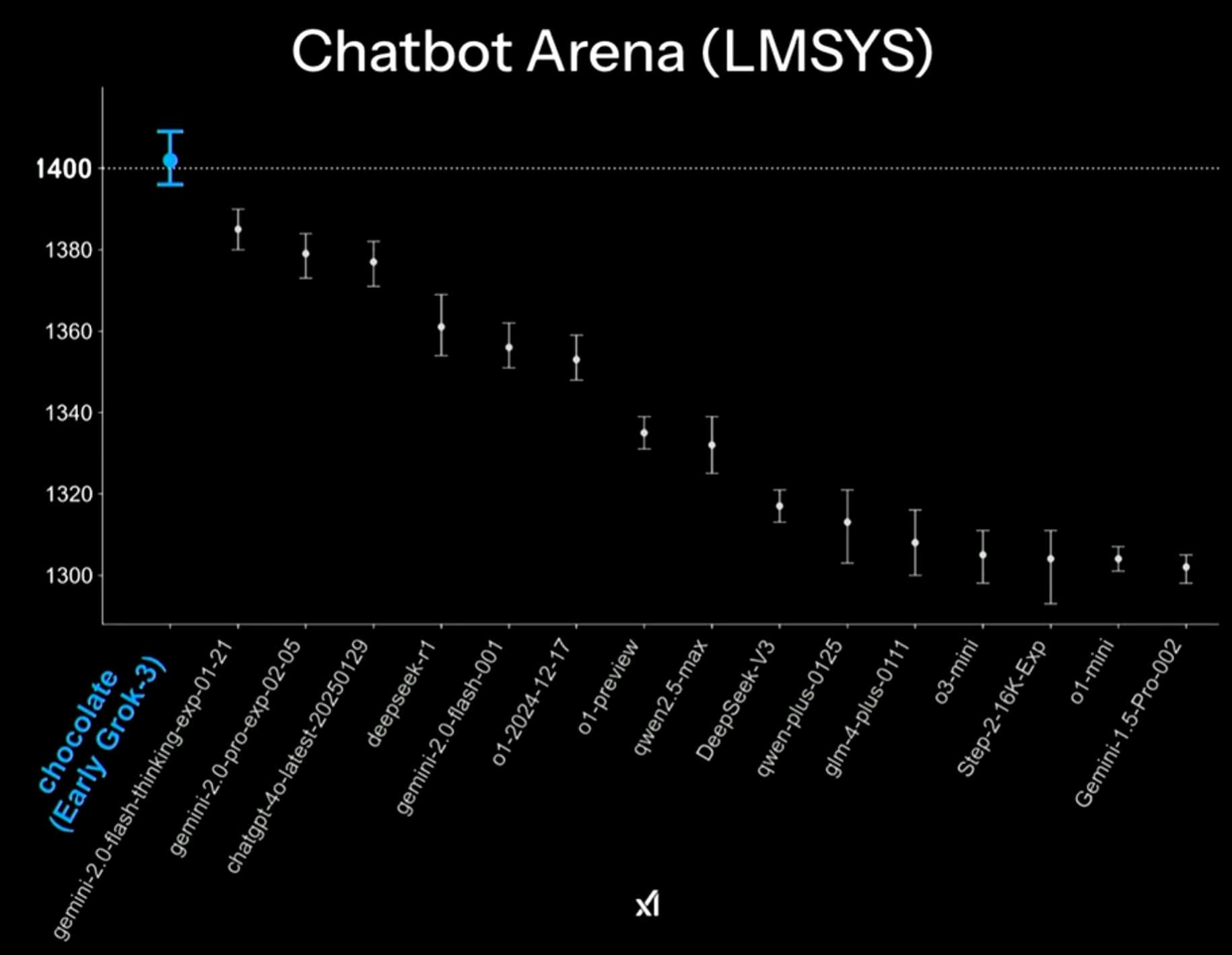
Elo评分系统最初是为国际象棋棋手排名而设计的,用于衡量玩家的相对技能水平。Chatbot Arena 采用 Elo 评分系统来评估和排名不同的 LLM。根据Elo评分系统,如果一个玩家的评分比对手高400分,那么这个玩家的预期胜率是10:1。1400分以上表示Grok-3模型在Chatbot Arena的众多模型中表现非常出色,属于顶尖水平的模型。
Grok-3的实际展示
为了更好的展示Grok-3的能力,我们也给出一些演示截图。Grok-3支持推理模式,也支持深度推理模式,从截图看效果很好。
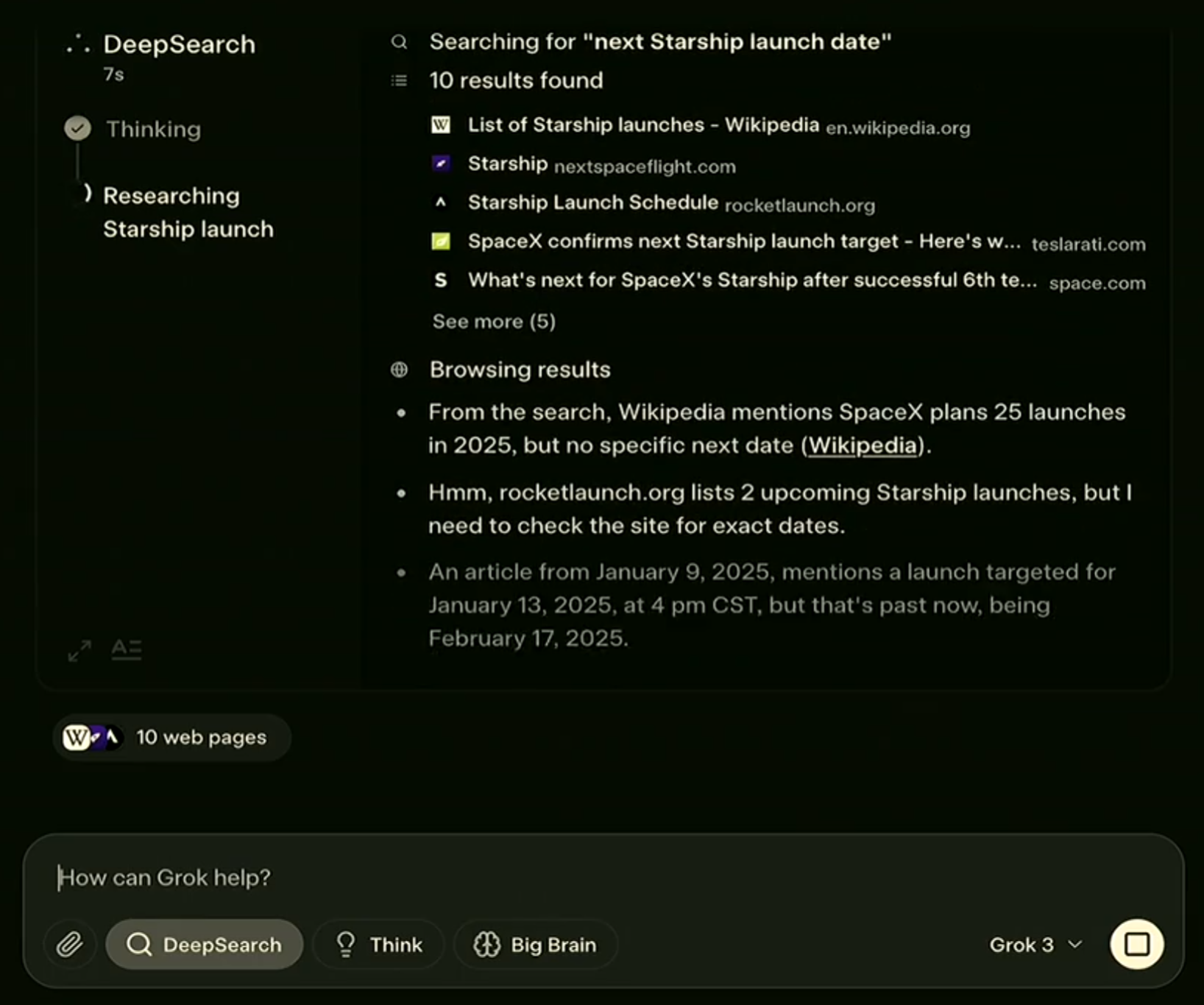
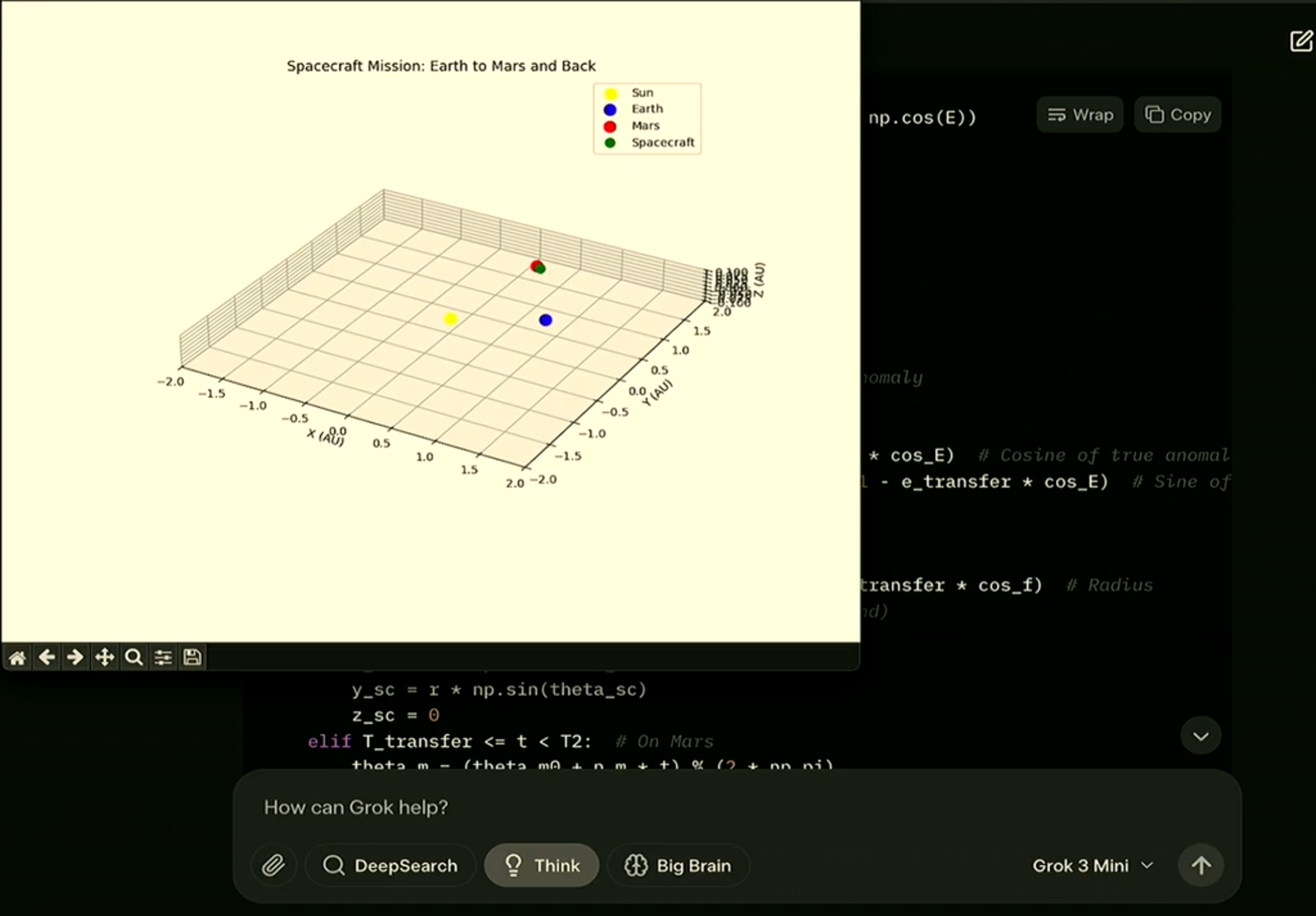
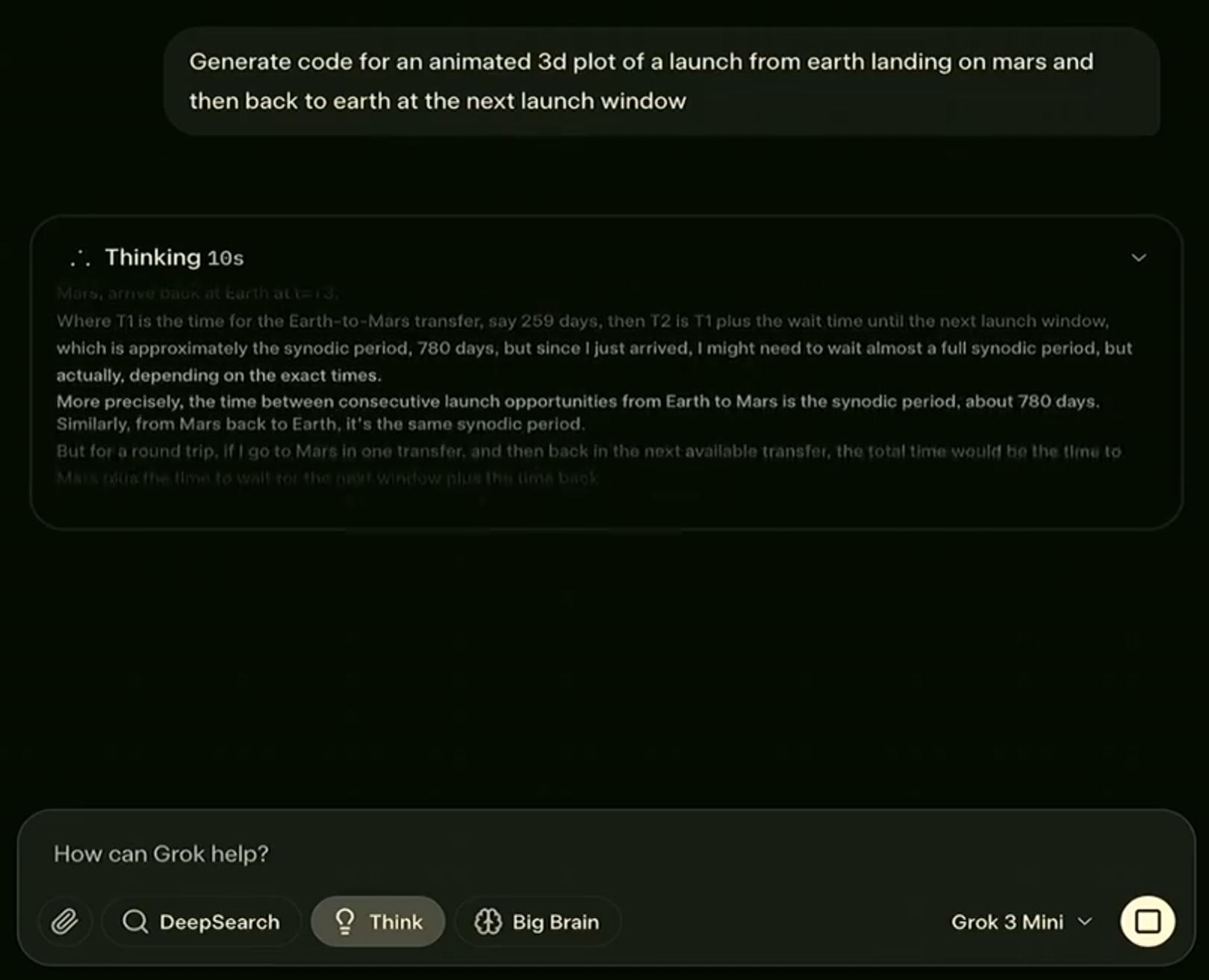
Grok-3模型总结
Grok-3模型应该是当前为止训练最多算力的模型之一,基于20万英伟达显卡训练。其结果也表明了堆算力依然是非常值得投入的事情。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
