重磅!阿里开源媲美GPT-4o的图片生成和编辑大模型Qwen Image,中文渲染能力很强,还有精确的文字控制,免费开源!
Qwen Image大模型是阿里千问团队开源的高质量图片生成和编辑的大模型。该模型在2025年8月5日发布,其核心并非又一个单纯追求图像美学或真实感的模型,而是直指一个长期存在的行业痛点:在图像中进行复杂、精准、尤其是高保真的多语言文本渲染。
重要的是,这个模型以Apache 2.0协议开源,其图像生成的质量也非常优秀,官方给出的技术报告和初步评测数据显示,Qwen-Image在通用图像生成与编辑能力上对标顶级模型的同时,在中文文本渲染这一关键垂类上实现了SOTA(State-of-the-Art)级别的表现。

关于模型的开源地址、在线演示地址等其它信息参考DataLearnerAI的模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/qwen-image
Qwen Image模型的特点和一些技术信息
Qwen Image是一个200亿参数规模的模型,其设计初衷是为了解决当前主流文生图模型面临的两大核心挑战。理解这两个挑战及其解决方案,是评估该模型价值的基础。
挑战一:复杂提示词对齐,特别是文本渲染
即便是顶级的商业模型,在处理包含多行文字、非字母语言(如中文)、特定位置文本嵌入或图文混排的复杂提示时,也常常出现字符错误、格式混乱或无法理解布局指令的问题。
Qwen-Image则主要通过数据工程与课程学习 (Curriculum Learning)两个方法提升文字渲染的精确性:
- 全面的数据管线 (Data Pipeline): 团队构建了一个包含大规模数据收集、过滤、标注、合成和平衡的复杂数据处理流程。值得注意的是,其训练数据中明确包含了“Design”和“Synthetic Data”类别,前者包含海报、UI、PPT等富含文本和布局信息的设计稿,后者则通过受控的文本渲染技术合成,这直接为模型注入了强大的文本渲染基因。
- 渐进式训练策略 (Progressive Training): 模型训练采用“课程学习”的思路,从简单的非文本图像生成开始,逐步引入简单文本,最后扩展到段落级、对布局敏感的复杂图文生成。这种由易到难的学习路径,系统性地强化了模型对文本的原生渲染能力。
挑战二:图像编辑的视觉与语义一致性
图像编辑任务要求在修改指定区域的同时,必须保持非编辑区域的视觉细节不变(如改变发色但不改变面部特征),并且维持整体场景的语义连贯性(如改变人物姿势但保持其身份和环境不变)。
为了保证图片编辑的准确性,Qwen-Image使用了多任务训练与双重编码 (Dual-Encoding)的技术:
- 增强的多任务训练范式: 框架内不仅集成了传统的文本到图像(T2I)和文本引导的图像编辑(TI2I),还引入了图像到图像的重建任务(I2I),这有助于模型学习更稳健的视觉表征。
- 双重编码机制: 这是其编辑能力的关键。当输入一张待编辑的图片时,系统会同时进行两种编码:
- 语义编码: 通过其强大的多模态模型Qwen2.5-VL提取图像的高层语义特征(场景、对象关系等)。
- 重建编码: 通过VAE编码器提取图像的底层视觉细节特征(纹理、颜色、结构等)。 将这两种特征共同作为条件输入到扩散模型(MMDiT)中,使得模型在执行编辑指令时,既能“理解”语义层面的修改意图,又能“记住”像素层面的视觉保真度,从而在二者之间取得平衡。
Qwen-Image在关键任务上的评测结果都接近GPT Image
为了评估Qwen Image的能力,官方在多个评测上给出了QwenImage和其它模型的对比测试结果,如下图所示:
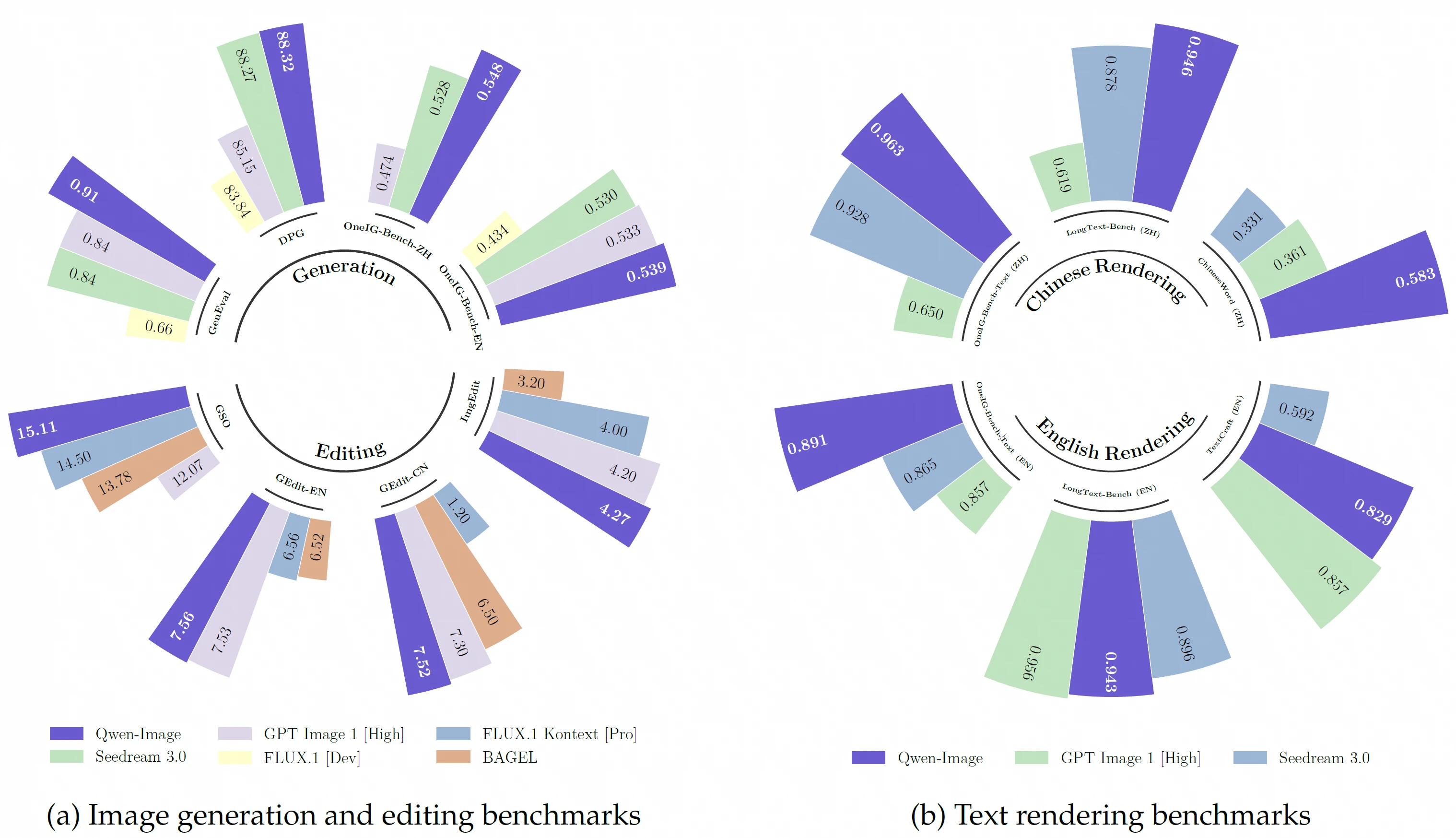
紫色是Qwen Image的结果,可以看到,不管是在图像编辑还是文本渲染上,Qwen Image的模型效果都是第一梯度的。
1. 文本生成(Text-to-Image)表现
在文本生成的核心能力上,Qwen-Image的表现可以概括为“通用能力强,文本渲染精”。
-
通用图像生成: 在衡量综合能力的多个公开基准测试(如DPG、GenEval、OneIG-Bench)上,Qwen-Image的得分均位列前茅,与GPT Image 1 [High]、Seedream 3.0等顶级闭源模型处于同一梯队。在阿里巴巴内部的AI Arena匿名对战平台上,Qwen-Image是唯一进入前三名的开源模型,Elo评分超过了GPT Image 1和FLUX.1 Kontext。
-
文本渲染能力 (核心亮点): 这是Qwen-Image最引人注目的部分。
- 中文渲染: 在新推出的
ChineseWord基准测试中,Qwen-Image在渲染一级常用字(3500个)时的准确率达到了惊人的97.29%,而Seedream 3.0为53.48%,GPT Image 1 [High]为68.37%。这几乎是断层式的领先优势。 - 长文本与多语言: 在
LongText-Bench测试中,它在中英文长文本渲染上均取得第一或第二的成绩。在OneIG-Bench的文本专项上,无论中文还是英文,它都排名第一。
- 中文渲染: 在新推出的
从官方博客提供的定性示例来看,无论是生成包含复杂对联和匾额的中式厅堂,还是生成带有多个英文标签和书名的书店橱窗,Qwen-Image都能准确、清晰地完成文本渲染,且布局合理,与场景融合度高。
2. 图像编辑(Image Editing)表现
Qwen-Image的编辑能力同样在多个基准测试中得到了验证。
-
指令编辑: 在
GEdit-Bench(衡量对复杂指令的遵循度)和ImgEdit(覆盖9种常见编辑任务)上,Qwen-Image的综合评分均排名第一,超越了包括GPT Image 1 [High]和FLUX.1在内的所有对手。这得益于其前述的“双重编码”机制,使其在执行“换顶戴花翎”、“保持姿势坐到楼梯上”等精细操作时,能更好地保留人物身份和背景的一致性。 -
多模态通用编辑: 报告还展示了其在“新视角合成”(Novel View Synthesis)和“深度估计”(Depth Estimation)等任务上的潜力。这些任务被统一在图像编辑的框架下,通过输入图像和文本指令(如“向右转90度”)来完成。结果显示,作为一个通用的图像基础模型,Qwen-Image在这些专业任务上的表现甚至可以媲美一些专门为此设计的模型,展示了其强大的多任务泛化能力。
Qwen Image实测结果
下图是官方给出的实际图片集合,非常精美:

不过由于Qwen团队暂时还没有将该模型上架到Qwen Chat,所以大家只能在HF上测试,只是HF也是问题比较大,经常失败。

不过,官方表示Qwen Chat很快就会上架这个模型,大概率还是免费直接用。
分析与展望:Qwen-Image的战略价值与行业影响
Qwen-Image是当前开源领域稍有的图像编辑和文字渲染都非常强的文生图大模型,此前大多数这类模型都是闭源或是质量不太好的。
Qwen-Image的发布,可能预示着文生图领域的竞争焦点正在发生微妙的转移。
以往,社区对模型的评判标准更多集中在图像的真实感、艺术风格和美学质量上。Qwen-Image将“文本渲染”这一功能性指标提升到了前所未有的高度,强调了模型作为信息传达工具的价值。这可能引导未来的模型发展更注重**“视觉-语言用户界面 (Vision-Language User Interfaces, VLUIs)”**的构建,即AI不仅能生成好看的图,更能生成信息准确、结构清晰、可用于解释复杂概念的图。
开源力量的再次冲击: 在Midjourney、GPT-4等闭源模型构筑起商业壁垒后,开源社区急需一个能与之抗衡的基座。Stable Diffusion系列扮演了开创者的角色,只是Stable Diffusion各种问题导致了当前已经掉队很多,而Qwen-Image则可能成为一个新的、性能更全面的追赶者和挑战者。它不仅为个人开发者和研究者提供了免费的强大工具,也为希望构建自有视觉模型的企业提供了坚实的基础。
总而言之,Qwen-Image的发布不仅是一次技术成果的展示,更是一次清晰的战略布局。它通过解决一个具体而关键的行业难题,展示了其深厚的技术积累,并通过开源的方式,向整个AI社区发出了强有力的信号。未来,基于Qwen-Image的二次开发和创新应用,以及它将如何影响闭源模型的迭代方向,都将是值得我们持续关注的焦点。
关于Qwen Image的开源地址和在线演示地址请访问:https://www.datalearner.com/ai-models/pretrained-models/qwen-image
