大模型到底能否真正提升写代码效率?Anthropic 内部 20 万条数据首次公开大模型在真实代码工作流中的表现
随着模型能力不断增强,AI 不再只是“写点代码的小帮手”,而是开始深度嵌入整个工程团队的日常工作。从 debug、写脚本、跑实验,到重新定义“谁是初级工程师、谁是高级工程师”,很多事情都在悄悄改变。
几天前,Anthropic 发布了一篇很有意思的研究博客——《How AI Is Transforming Work at Anthropic》,他们把“研究对象”直接对准了自己:132 名工程师与研究员、53 场深度访谈、20 万条 Claude Code 内部使用记录,试图回答一个问题:
在一家 AI 公司内部,当工程师人人有一个“AI 同事”之后,工作到底变成了什么样?
这篇文章,我更愿意把它看成是**“AI 时代软件工程职业形态的一次切片”**。下面是 DataLearnerAI 对这篇研究的完整解读与整理。

目录
为什么这次研究值得认真看?
首先需要说明的是这次调查可能不是那么客观,报告中 Anthropic 自己也承认:在一家 AI 公司里研究“AI 对工作的影响”,有点“样本偏好”:工具最新、同事最爱用、行业相对稳定,还自己在造轮子。所以可能不是一个普遍的现状。但也正因为如此,这里有几个特别有价值的点:
- 这是一批最早、最深地拥抱 AI 编程工具的人
- 这些人本身就在做模型、做工具,是典型的 AI-first 工程团队
- 他们不仅“用 Claude”,还围绕 Claude 重构了工程工作流(例如 Claude Code)
换句话说,如果你想看:“3–5 年后大多数工程团队可能长什么样”?那么 Anthropic 现在的内部状态,多少可能就是一种方向。
下图展示了本次调查中,这些人用AI做的事情有哪些:
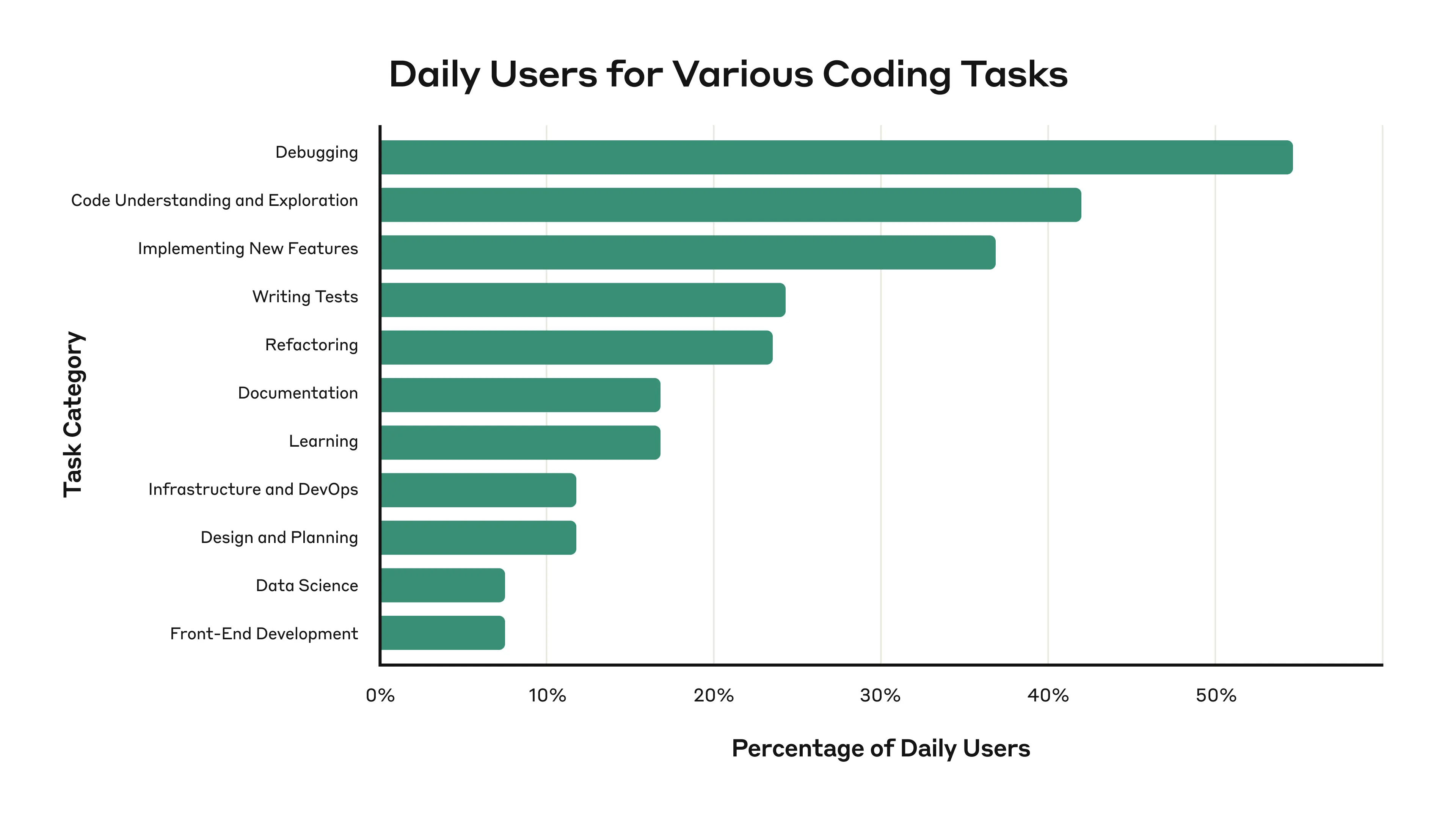
可以看到,相比较代码生成,debugging、代码理解是工程师让AI做的最多的事情,实现新特性也是排行第三的。我们之前认为的AI要取代前端的事情在Anthropic内部的工程师里面似乎占比不高。
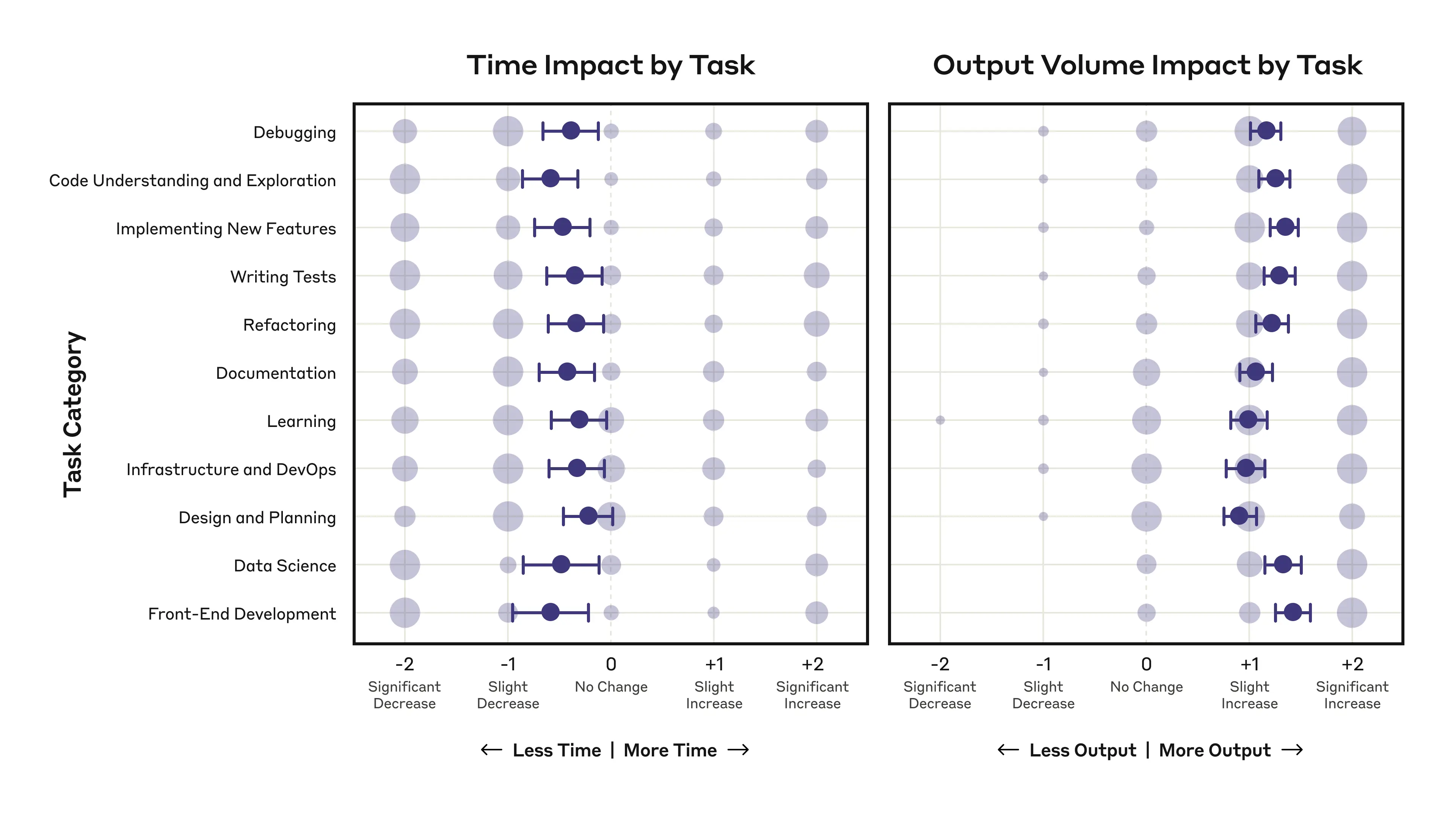
同时,尽管各项任务的完成时间都有减少,但是每个任务输出的内容反而变多了。而且有些人完成任务的时间也变得更久,因为他们需要花费时间来整理Claude Code的代码。下面我们来详细说明一下。
使用大模型之后生产力真的提高了吗?Anthropic 的内部数字证明似乎是的
先说大家最关心的一点:**效率到底涨了多少?**Anthropic 做了一个简单但足够直观的对比:以“12 个月前”和“现在”两个时间点,问工程师两个问题:
- 你在多少比例的工作中使用 Claude?
- 你觉得 Claude 让你的生产力提高了多少?
他们自报的结果大致是这样的:
可以看到,使用比例和效率似乎都有明显提升。这里有几个值得拆开的点:
-
Claude 参与工作从 “边角工具” 变成了 “默认入口” 一年前更多是写点脚本、查查 API,现在已经是“超过一半的工作都要顺手问一下 Claude”。
-
生产力的提升是“体积型”的 自报 +50%,同时 PR 数量大幅增加。研究里也明确指出:时间略降,输出明显增多——你可以把同类任务做得更多、更细,而不是简单地“更快下班”。
-
27% 的 Claude 工作,是“原本不会存在的工作” 这一点很关键。Anthropic 工程师自己估计:所有 Claude 参与过的工作里,有大约 27% 的任务在没有 AI 时根本不会做——比如:
- 做更细致的文档和测试
- 修各种“papercut”(小痛点)
- 构建内部可视化工具、交互式 dashboard
- 做一些“没时间做、但做了肯定更好的尝试性工作”
这意味着:AI 带来的不是原有任务的线性提速,而是整个任务空间的扩张。
工程师如何使用 Claude:从“写代码的人”变成“管理 AI 的人”
问一句非常现实的问题:**在 Anthropic,工程师现在具体怎么用 Claude?**研究的三个视角是对齐的:问卷、访谈与 Claude Code 数据,都给出了一条相似的轮廓。
AI 委托直觉:什么事情该交给 Claude?
工程师对“什么任务适合交给 Claude”已经形成了蛮清晰的一套直觉,总结起来大概是:“低风险、易验证、没太多兴趣自己做、Claude 又不容易搞砸的事情。”
更细一点,大概包括:
-
自己不熟,但问题本身不复杂的事情 例如 Linux 命令、Git 操作、CI 配置等等——“不是很难,但我不熟,Claude 比我更快”。
-
易于验证的事情 “验证成本小于创建成本”的工作:你能一眼看出错不错,而不需要重建整套思维链路。
-
被认为“有点烦”的事情 很多工程师的原话是:“我越兴奋的任务,越不会用 Claude;越抗拒、越拖延的任务,就先找 Claude 聊一聊。”
-
足够独立、边界清晰的子任务 比如一个组件的实现、一段脚本、一段特定逻辑的重构。
-
“冷启动成本过高”的事情 当任务需要把很多上下文讲清楚、整理清晰文档、写长 prompt 时,有些人反而会选择自己做。 你可以理解为:如果把事情讲清楚给 Claude 听比自己做还费劲,那就算了。
这一套委托直觉,和外部研究(比如 METR 的实验结果)结论高度吻合:真正决定 AI 提升生产力的,不是模型本身,而是任务选择策略。
技能版图的变化:更 full-stack,也更担心“生锈”
这次研究里,一个很典型的变化是:**工程师的能力“横向拉长”了,纵向“深度”则变得更模糊。**简单来说就是更多的工程师似乎更加“全栈”。举几个典型场景:
- 后端工程师可以在 Claude 的帮助下实现复杂 UI
- 研究员可以自己做前端可视化、不用再等前端同事排期
- 安全团队成员用 Claude 去读陌生代码、做安全分析
- 非技术同事用 Claude 解 Git 报错、写数据分析脚本
这就是 Anthropic 文里一直强调的:everyone is becoming more full-stack。但与此同时,访谈里出现频率很高的另一个词是:skill atrophy(技能萎缩)。工程师的典型担忧是这样的:
- “我用 Claude 之后,自己 debug 的次数少了很多。”
- “用 AI 的时候,我少了那种‘顺便建立系统心智模型’的过程。”
- “你越不亲手写,就越难判断 Claude 的东西到底好不好。”
这就引出了一个很扎心但很真实的悖论:**你越依赖 AI,越需要有能力审核它;你越让 AI 帮你做事,你审查它的能力就越可能变差。**有些工程师会主动“反向练级”:哪怕知道 Claude 可以一秒写完,会刻意选择自己动手做一遍,以防“废掉自己”。也有人直接表示:“我确实在某些技能上变生疏了,但如果以后真的需要,这些技能还能捡回来。现在这样效率就是更高。”
编程的“乐趣”正在被重写
这一点在原文里其实写得很直白:**有些人真心怀念“自己写代码”的那种爽感。**访谈里有几类典型心声:
- “写代码、重构进入心流,是我 20 多年职业生涯的快乐来源之一。”
- “天天在提示、审核、重试,而不是自己敲代码,没那么有趣。”
但也有另一批人,完全是另一种态度:
- “我发现我喜欢的,其实不是写代码本身,而是代码带来的结果。”
- “如果 AI 能让我更快看到那个结果,我完全可以接受少写一点代码。”
所以,对“AI 编程”的态度,很大程度上取决于你在工程工作里到底珍惜什么:如果你享受的是工艺本身:手写代码、优化细节、重构的节奏感,那 AI 的涌入会让你感觉像是行业进入“后手工时代”;如果你享受的是结果与影响:产品上线、实验结果、用户反馈,那你会更容易拥抱这次转变。
工作场的变化:协作、Mentor 与职业不确定性
当“问问题的第一站”从同事变成 Claude,团队氛围也在改变。
几个很典型的现象:
-
“先问 Claude,再问人”变成默认流程 有人说:自己现在问的技术问题比以前多了很多,但“80–90% 都直接丢给 Claude”。这个结果就导致了同事之间的技术问答变少了, 真正要问人的问题,往往已经是 Claude 搞不定的高复杂度问题
-
Mentor 角色正在被重新定义 很多高级工程师提到:“新人来问我的次数明显变少了”、“他们的问题可能被 Claude 回答得更快更系统”、“我一方面觉得有点失落,一方面也承认他们确实学得更快”等等。
这对“如何在 AI 时代培养新人”其实是个开放问题:如果新人的主要老师是 AI,那资深工程师的经验要以什么形式传递?
-
职业路径的不确定性,几乎是所有人的共识 短期看,几乎所有人的感受是:“工作变得更高效,事情做得更多了。但中长期的感受,更多是:“说不好”。研究里有一句非常典型的话:
“我在短期是乐观的,但长期说不清,会不会有一天 AI 把我整个职业都吃掉。”
也有人选择另一个角度:把自己定位为 “AI agent 的管理者”,认为未来工程师的角色更接近:
- 主要负责设计目标
- 需要管理、协调多个 AI
- 对 AI 的输出负责
这些不确定性不仅是对个人来说如此,对组织来说也是。Anthropic 自己也在文章结尾承认:“我们现在能做的,只是把这些变化观察清楚,然后在组织内部先试着做调整。”
Claude Code 使用数据:AI 已经在悄悄“接管主循环”
前面讲的都是人的感受,接下来这部分完全是行为数据。Anthropic 用内部的隐私保护分析工具,抽样分析了 20 万条 Claude Code 的内部会话记录,做了两个时间点的对比:2025 年 2 月 vs 2025 年 8 月。有几个很关键的变化:
1. 任务复杂度显著上升
他们给每个任务打了一个 1–5 的“复杂度评分”:1代表简单编辑,而最高分5分表示需要专家投入数周甚至数月的大型任务,调查结果发现团队成员反馈的Claude Code解决问题的复杂度的平均值从 3.2 → 3.8。论文里给了一个很形象的对比:
- 3.2:类似于“排查 Python 模块导入错误”
- 3.8:类似于“设计并优化缓存系统”
也就是说:Claude Code 正在从“写小补丁”向“搞系统级工作”迁移。
2. 自主操作的“连续工具调用”翻倍
在 Claude Code 里,“工具调用”可以理解为:**AI 自己对环境动手:编辑文件、运行命令、执行测试……**研究里给出的数字是:
- 6 个月前:一次会话中最长连续工具调用约 9.8 次
- 现在:提升到 21.2 次
也就是说:**Claude 能在更少人工干预的前提下,自主完成一整串工作流程。**这是从“人带 AI 干活”,向“AI 带着自己跑完任务,人只在关键节点插手”的一个明确信号。
3. 人类对话轮数减少约 1/3
另一个比较有趣的数字是人类与 Claude Code 的平均对话轮数:**6.2 → 4.1(下降约 33%)**直白理解就是要完成同样一个任务,现在需要的人类对话更少、提示更短、干预更少。结合前面的复杂度上升与工具调用增加,很容易得出一个结论:在 Anthropic 内部,Claude Code 已经从“写代码助手”升级为“可以独立跑工作流的执行体”。
4. 任务类型的分布在改变:从“修 bug”到“实现新功能”
对比 6 个月前与现在的任务分布,有两个变化最明显:新功能实现占比:从 14.3% 上升到 36.9%,而设计 / 规划类任务占比从 1% 增加到 9.9%。这说明两件事:
- 团队越来越愿意把“真正有业务价值”的工作交给 Claude
- 连“设计方案”这类传统上认为非常依赖人类 judgment 的环节,也开始有一部分被让渡给 AI
5. 8.6% 的任务是“papercut 修复”
研究里还有一个小细节,但非常有意思:**大约 8.6% 的 Claude Code 任务,都是在修“小痛点”。**这些包括:
- 小范围重构,提高可维护性
- 写一个内部小工具、脚本、终端 alias
- 把某些“将就用了很久”的东西改得更顺手
这些事情,过去往往就是那种:“没人愿意专门花半天时间搞,但每个人每天都要被它恶心一遍”的东西。从长期来看,这种“质量生活改善”带来的效率提升,很可能比单点性能优化更有意义。
DataLearnerAI 视角:工程团队接下来几年应该怎么应对?
这篇研究对工程实践和团队管理,其实给出了很多值得提前思考的信号。结合 DataLearnerAI 这段时间在大模型 + Agent 方向上的观察,我更关心的不是“AI 会不会取代工程师?”而是:
“工程团队要用多少年,才会把现在的‘人+AI 协作方式’,沉淀为一个稳定的工程范式?”
如果你现在正在带一个工程团队,或者在公司内部推动 AI 工具落地,可以重点想几件事:
-
不要只盯着“速度”,要盯“任务构成”
- 你的团队是否开始做过去没时间做的事情?
- papercut 有没有被系统性清除?
- 文档、测试、可视化、内部工具,有没有明显改善?
-
要有意识地设计“技能不萎缩的使用方式”
- 哪些阶段刻意让新人不用 AI,先自己做一轮?
- 哪些环节必须由资深工程师给出“审查标准”?
- 如何把“审核 AI 输出”变成一种正式的工程能力?
-
把“如何与 AI 协作”当成一门工程基础课 从这篇研究能看出很明显的一点:**同样的模型,使用方式差异可以带来截然不同的生产力结果。**我们需要做的是下面的判断:什么任务适合丢给 AI?如何拆解任务,降低验证成本?什么时候要停下来,自己重新从头想一遍?
-
重新思考 Mentor 与职业路径
在 AI 辅助的环境下,“高级工程师”意味着什么?他们传递的,不再只是“怎么写这段代码”,而是:
- 怎么设置验收标准
- 怎么设计整体架构
- 怎么审核 AI 的输出
- 新人如何在 AI 时代获得真正的“工程 sense”?
-
接受一个事实:编码本身,正在变成抽象层的下游 从汇编到高级语言,从手写 SQL 到 ORM,再到现在的“英语编程 + AI 执行”,每一波抽象升级都会让一部分手艺淡出日常工作。 关键问题不再是以后还需不需要会写代码?而是当每个人都有一个能写代码的 AI 同事时,你还能提供什么独特价值?
Anthropic 把自己当作“AI 时代工作方式变革的一个实验室”,这篇研究就是他们对外公开的一份阶段性观察记录。从 DataLearnerAI 的视角看,这份数据最大的价值在于:**它不是在给一个“乐观故事”或“悲观故事”,而是把不确定性本身完整展现出来。**如果你也正在搭建自己的 AI 工程体系,这篇研究可以看成一个非常好的参照系——既是别人的“现在”,也很可能是你的“未来进行时”。
