阿里开源Qwen3.6-35B-A3B:3B激活参数,Terminal-Bench 2.0达51.5,Agent编码能力全面超越上代
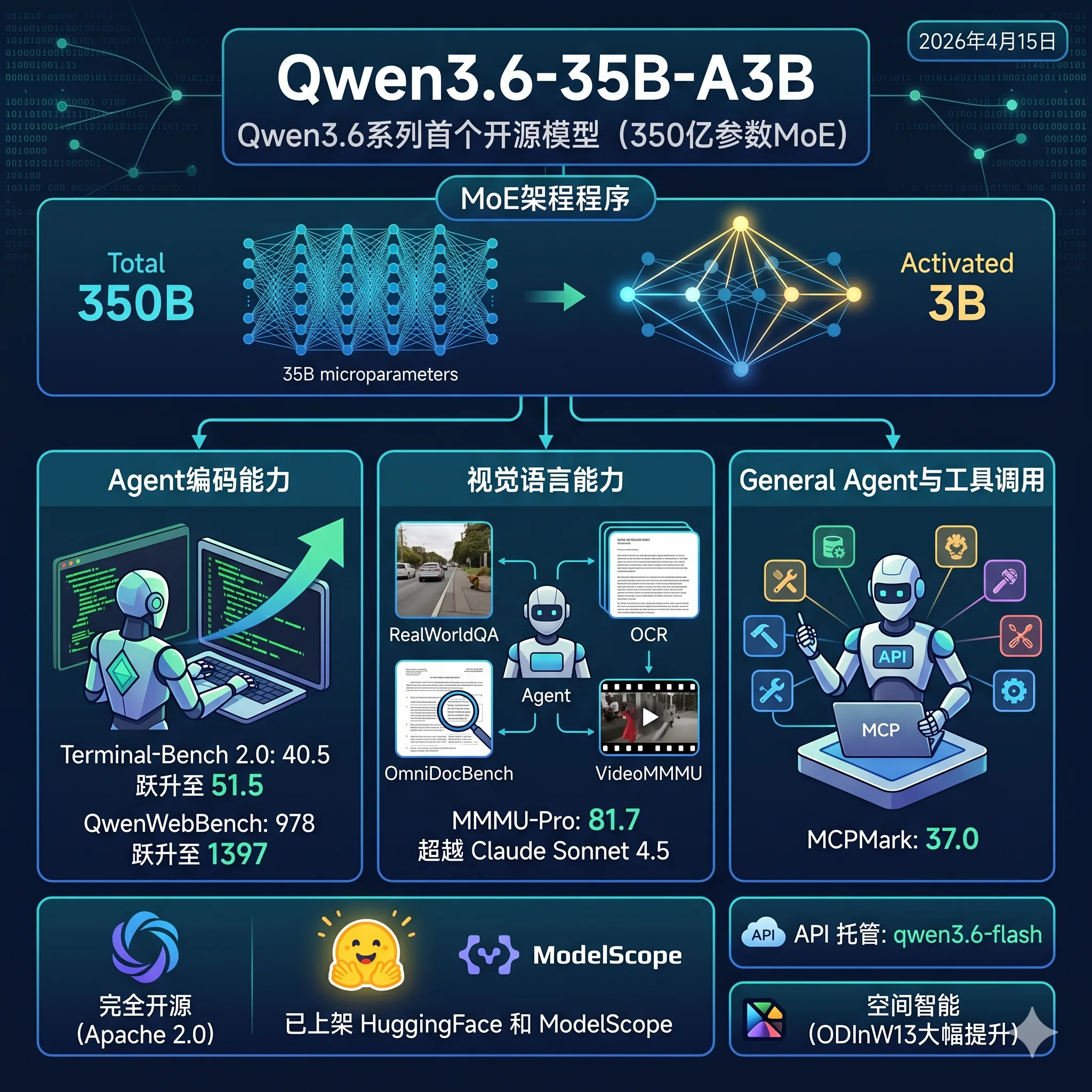
就在刚刚(2026年4月15日),阿里通义千问团队宣布开源 Qwen3.6-35B-A3B。这是继 Qwen3.6-Plus 以 API 形式亮相之后,Qwen3.6 系列的首个开放权重模型。模型总参数规模 350 亿,但每个 token 仅激活约 30 亿参数,在 Agent 编码类任务上大幅超越上代同款 Qwen3.5-35B-A3B,Terminal-Bench 2.0 评测从 40.5 跃升至 51.5,QwenWebBench Elo 评分从 978 跃升至 1397,在 Agent 编码方向已接近甚至超过上一代稠密旗舰 Qwen3.5-27B。模型以 Apache 2.0 协议完全开源,已上架 HuggingFace 和 ModelScope,API 托管版本对应模型名 qwen3.6-flash。
目录
- 背景:林俊旸离开之后,这是千问的首次开源
- Qwen3.6-35B-A3B 的核心特点
- Agent编码与语言能力评测:代码Agent全面提升,知识推理稳步改善
- 视觉语言能力:多项指标超过Claude Sonnet 4.5
- 如何获取与部署
背景:林俊旸离开之后,这是千问的首次开源
通义千问近几个月经历了一次不小的人事变化。主导 Qwen3-Max 和 Qwen3.5 系列开发的核心负责人林俊旸(Lin Junyang),已于 2026 年初正式离开阿里巴巴,同期还有多名 Qwen 高管相继离职。
此前,Qwen3.6-Plus 于 3 月 30 日悄然上线 OpenRouter,上线首日单模型调用量突破 1.4 万亿 token,创下该平台历史纪录,并在 Code Arena 全球排名中居中国模型最高位。但彼时模型权重未对外开放。根据 Qwen3.5 Plus 的命名风格,Qwen3.6-Plus 应该是 Qwen3.6-397B-A17B 规模的模型(因为 Qwen3.5-Plus 就是 Qwen3.5-397B-A17B)。今天的 Qwen3.6-35B-A3B,是 Qwen3.6 系列第一个开源模型。
Qwen3.6-35B-A3B 的核心特点
通常来说,MoE 架构的模型相比同等总参数规模的稠密模型,综合能力是要偏弱的——这是 MoE 设计的固有取舍,以激活参数少换取推理效率,但知识密度上往往不及全参数激活的稠密版本。
Qwen3.6-35B-A3B 这一代的提升是比较明显的,在 Agent 编码方向已经接近甚至超过了上一代同等参数规模的稠密模型 Qwen3.5-27B。Terminal-Bench 2.0 上,Qwen3.6-35B-A3B 得分 51.5,Qwen3.5-27B 为 41.6;SWE-bench Verified 上得分 73.4,与 Qwen3.5-27B 的 75.0 仍有小幅差距,尚未完全追平。相比上代同款 Qwen3.5-35B-A3B,进步幅度同样明显,整体提升主要集中在 Agent 执行层面。
Agent编码与语言能力评测:代码Agent全面提升,知识推理稳步改善
从评测数据来看,Qwen3.6-35B-A3B 的进步主要集中在 Agent 编码方向,知识和推理类指标属于稳步改善,通用 Agent 方向则表现参差。以下分类来看。
Agent 编码
Agent 编码是这次发布最值得关注的方向,也是与上代拉开差距最明显的地方。从下表可以看到,Qwen3.6-35B-A3B 在几乎所有编码 Agent 评测上均超越上代同款 Qwen3.5-35B-A3B,且多项指标已接近甚至超过 Qwen3.5-27B。
SWE-bench Verified 和 Terminal-Bench 2.0 是目前最接近真实 Agent 工作流的编码评测:前者要求模型修复真实 GitHub 仓库中的 issue,后者在真实终端环境中运行完整任务。Qwen3.6-35B-A3B 在这两项上均明显超越上代同款,Terminal-Bench 更是以 51.5 超越了 Qwen3.5-27B(41.6)和 Gemma4-31B(42.9)。SWE-bench Verified 的 73.4 尚未追平 Qwen3.5-27B 的 75.0,差距已缩小到 1.6 个点。
QwenWebBench 涵盖 Web Design、Web Apps、Games、SVG、数据可视化、动画和 3D 七个前端类别,采用自动渲染加视觉评分,Elo 评分从 978 跃升至 1397,是本次发布提升幅度最大的单项指标,体现了模型在生成完整可运行前端代码方面的实质性进步。
General Agent
通用 Agent 方向(客服、规划、工具调用)上,这次的提升不如编码方向集中,整体表现参差不齐,部分指标甚至略低于上代。
TAU3-Bench 上的 67.2 略低于上代的 68.9,MCP-Atlas 则基本与上代持平。MCPMark(MCP 工具调用评测)是这一类别的亮点,以 37.0 不仅大幅超越上代(27.0),也超过了 Qwen3.5-27B(36.3),说明在 MCP 工具调用的准确性上有实质提升。
知识与推理
知识和推理方向属于稳步改善,没有特别大的跃升,但各项指标方向一致向好。
GPQA Diamond 从 84.2 升至 86.0,已超过 Qwen3.5-27B 的 85.5;AIME 2026 从 91.0 升至 92.7;LiveCodeBench v6 从 74.6 大幅升至 80.4,追平了 Qwen3.5-27B 的 80.7。MMLU-Pro 与上代基本持平,C-Eval 中文综合评测 90.0 维持稳定,中文能力没有退步。
视觉语言能力:多项指标超过Claude Sonnet 4.5
Qwen3.6-35B-A3B 是原生多模态模型,官方以 Claude Sonnet 4.5 作为对比基准之一。整体来看,在通用视觉和文档理解方向,Qwen3.6-35B-A3B 相比 Claude Sonnet 4.5 有明显优势;与同系列稠密模型 Qwen3.5-27B 相比,差距进一步收窄,部分方向已经反超。
通用视觉与文档理解
通用视觉和文档理解是 Qwen 系列一贯的优势方向,这一代继续保持。官方选择将 Claude Sonnet 4.5 作为主要参照之一,从数据来看这个选择对 Qwen 相当有利。
RealWorldQA(85.3 对 70.3)、OmniDocBench1.5(89.9 对 85.8)、HallusionBench(69.8 对 59.9)均明显超出 Claude Sonnet 4.5。相比上代 Qwen3.5-35B-A3B,各项也有小幅提升。不过与 Qwen3.5-27B 相比仍有小幅差距,例如 MMMU 81.7 vs 82.3,视觉能力上并非全面超越同系列稠密版本。
空间智能与视频理解
空间智能和视频理解是这次视觉方向的主要进步点,多个指标不仅超越上代,还超过了 Qwen3.5-27B。
RefCOCO 从 89.2 升至 92.0,超过 Qwen3.5-27B 的 90.9;ODInW13 从 42.6 大幅升至 50.8,是空间智能方向提升最显著的单项;VideoMMMU 从 80.4 升至 83.7,同样超过了 Qwen3.5-27B 的 82.3。VideoMME(含字幕)与上代持平,维持在 86.6。
Qwen3.6-35B-A3B目前已经开源可以直接下载
模型已上架 HuggingFace(Qwen/Qwen3.6-35B-A3B)和 ModelScope,Apache 2.0 开源协议,商业使用无限制。
另外,阿里云官方已经上架该模型,模型名为 qwen3.6-flash,同时兼容 OpenAI 和 Anthropic 两套协议。后者意味着可以直接在 Claude Code 里配置使用,官方给出了完整配置脚本。此外模型同样支持接入 OpenClaw 和 Qwen Code 两种 Agent 编码工具。模型也已在 Qwen Studio 上线,可直接在线体验。
关于 Qwen3.6-35B-A3B 的更多基准数据及横向对比,参考 DataLearner 模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/qwen3-6-35b-a3b
