Anthropic发布Claude Opus 4.7:编程能力大幅跃升,视觉分辨率提升超3倍,首个搭载网络安全防护机制的旗舰模型!
就在今天,Anthropic正式发布Claude Opus 4.7,作为Opus 4.6的直接升级版本,本次更新重点集中在三个方向:软件工程能力的大幅提升、视觉理解的显著增强,以及一套全新的网络安全防护机制。值得说明的是,Opus 4.7并非目前Claude系列中能力最强的模型——那个位置属于上周刚刚发布的Claude Mythos Preview——但它是第一个面向大规模开放部署、同时完成完整安全体系验证的新一代旗舰。定价与Opus 4.6保持一致:API输入$5/百万token,输出$25/百万token。

Claude Opus系列背景与演进
Claude Opus是Anthropic旗舰模型系列中定位最高的产品线。此前的Opus 4.6于2026年2月发布,在复杂推理、代码生成、长上下文任务等方面表现突出。
上周,Anthropic发布了Claude Mythos Preview,将能力天花板进一步拉高,但出于安全考虑维持受限发布状态。Opus 4.7的推出,可以理解为Anthropic在"最强能力"和"广泛部署安全性"之间做出的一次工程平衡——比Mythos Preview能力稍弱,但已经过系统性安全验证,可以正式面向所有用户和企业开放。
从DataLearner收录的历代版本数据来看,Opus系列的演进相当稳健:
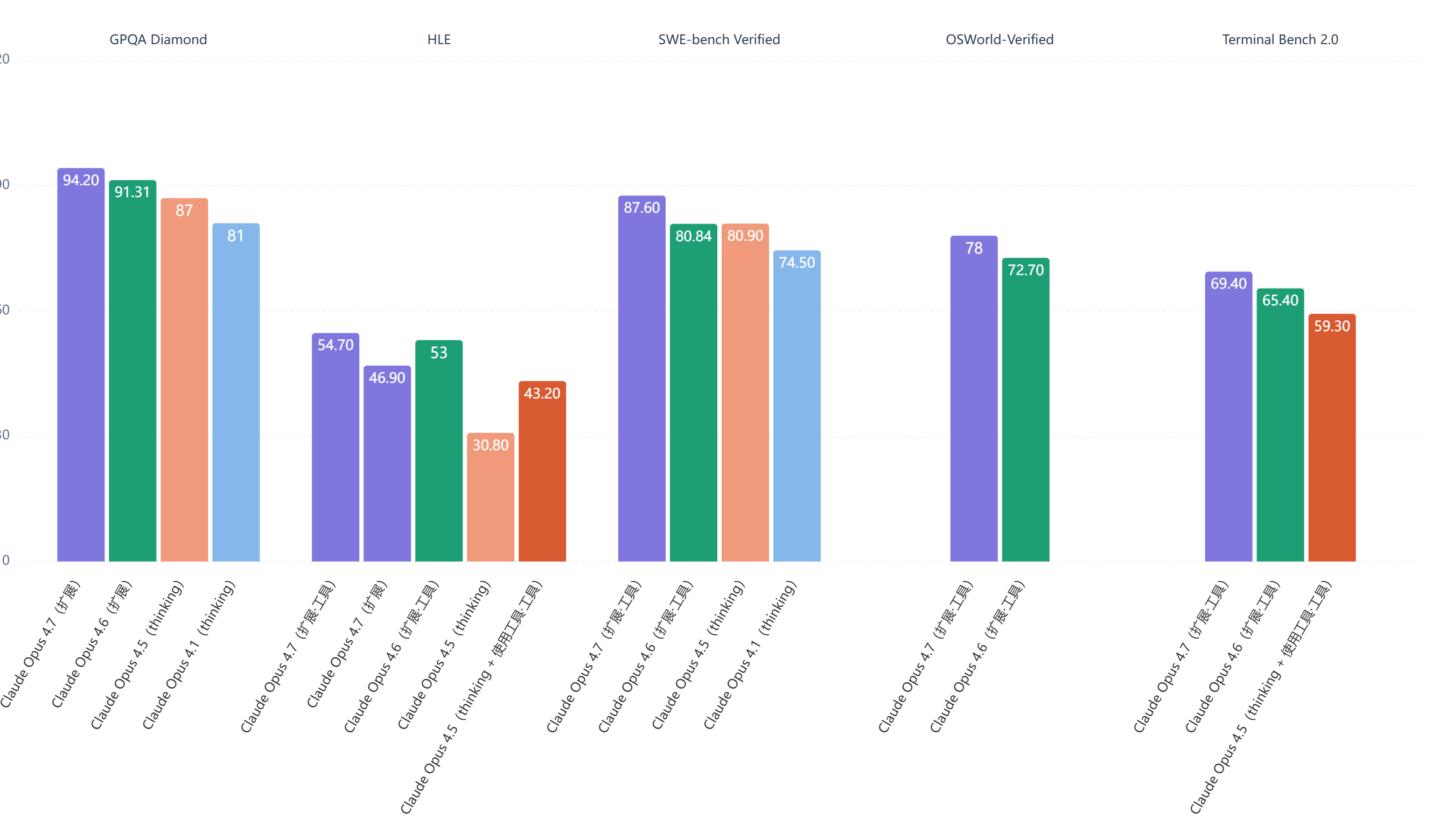
以GPQA Diamond为例,从Opus 4.1的81.00分,到4.5的87.00分,到4.6的91.31分,再到4.7的94.20分,每一代都有实质性提升。SWE-bench Verified的跨越更明显:Opus 4.6和4.5的成绩基本持平(80.84 vs 80.90),而4.7直接跳升至87.60分,这个突破是本次发布最值得关注的信号之一。
Claude Opus 4.7 核心能力:软件工程大幅跃升
这次更新最核心的亮点,是在软件工程任务上的显著提升,尤其是在最复杂的那类任务上。
从早期测试伙伴的反馈来看,提升幅度相当明显:
- Cursor CursorBench通过率达到70%,Opus 4.6为58%;
- Rakuten SWE-Bench内部评测中,解决生产任务数量是Opus 4.6的3倍;
- GitHub Copilot 93任务编程基准中,解决率比Opus 4.6提升13个百分点,其中包括4个此前两个模型都无法解决的任务;
- Notion 多步骤工作流任务准确率比Opus 4.6提升14%,工具调用错误率降至三分之一。
Opus 4.7的一个明显新行为:它会在开始工作前自行进行形式化验证,并在输出结果前主动检查自身逻辑的正确性,而不是等用户发现问题后再修正。简单说,比Opus 4.6更懂得"先想清楚再动手"。
在遵从指令方面同样有显著提升。这里有一个实际影响需要注意:之前针对Opus 4.6调校的提示词,现在可能产生不同结果——旧模型会对指令做宽松解读,Opus 4.7则更字面化地执行。建议开发者在切换模型后重新测试和调整提示词。
视觉能力重大升级:支持高达3.75百万像素
Opus 4.7在视觉理解方面做了一次重要的底层升级:支持的图像分辨率从此前版本的上限,提升至长边2,576像素(约3.75百万像素),是此前Claude模型的超过3倍。
几个典型的实际意义:
- 计算机使用(Computer Use)场景:可以清晰读取高密度截图中的UI元素。XBOW的测试中,Opus 4.7在视觉精度基准上得分达到98.5%,而Opus 4.6仅为54.5%,这个差距直接解锁了一整类此前无法使用的工作场景;
- 科学与工程图表:Solve Intelligence反映,已经可以准确读取化学结构式和复杂技术图表;
- OSWorld-Verified(计算机界面操控基准):Opus 4.7得分78.00,比Opus 4.6的72.70提升超过5个点,在DataLearner收录的12个模型中排名第二。
这是模型级别的变化,不需要调整API参数,发送给模型的图像会自动以更高分辨率处理。需要注意的是,高分辨率图像会消耗更多token,如不需要额外细节,可在发送前对图像降采样。
网络安全能力与首个差异化防护机制
这部分是Opus 4.7发布中一个特别值得关注的背景。
上周,Anthropic在发布Claude Mythos Preview的同时,也发布了Project Glasswing,专门评估AI模型在网络安全领域的风险与价值,并宣布在验证新防护机制之前,Mythos Preview将维持受限发布。Opus 4.7是第一个搭载这套网络安全防护机制的正式发布模型。
具体来说,Anthropic在Opus 4.7的训练过程中专门尝试差异化降低网络安全类能力,同时部署了一套会自动检测并拦截高风险网络安全请求的防护机制。策略逻辑是:先在能力相对较低的模型上验证这套体系,再逐步将经验应用到Mythos级别模型的广泛发布上。
对于有合法需求的安全专业人员(漏洞研究、渗透测试、红队评估),Anthropic开放了 Cyber Verification Program 申请通道。
配套新功能:xhigh推理等级、任务预算、/ultrareview
除了模型本身,这次发布还带来了几个配套功能更新:
新增 xhigh 推理等级:在原有的 high 和 max 之间,新增了 xhigh 等级,让用户在推理深度和响应延迟之间有更细粒度的控制。Claude Code 中,所有计划的默认推理等级已经从 high 提升至 xhigh。测试Opus 4.7做编程或智能体任务时,Anthropic建议从 high 或 xhigh 开始。
任务预算(Task Budgets)公测:Claude Platform API新增任务预算功能,开发者可以为Claude指定token消耗的分配策略,让模型在长时间运行任务中能合理分配资源、优先处理重要工作。
Claude Code新增 /ultrareview 命令:触发一次专项代码审查,逐行阅读代码变更,标记出资深审查者会发现的缺陷和设计问题。Pro和Max用户可以免费获得3次试用。另外,Auto mode(自动权限决策模式)现在也扩展到了Max用户。
DataLearner基准评测数据汇总
DataLearner已收录Opus 4.7的代表性评测成绩如下:

编程和计算机操控方向的排名非常靠前,这与Anthropic这次重点宣传软件工程能力的方向一致。
与GPT-5.4、Gemini 3.1 Pro的横向对比
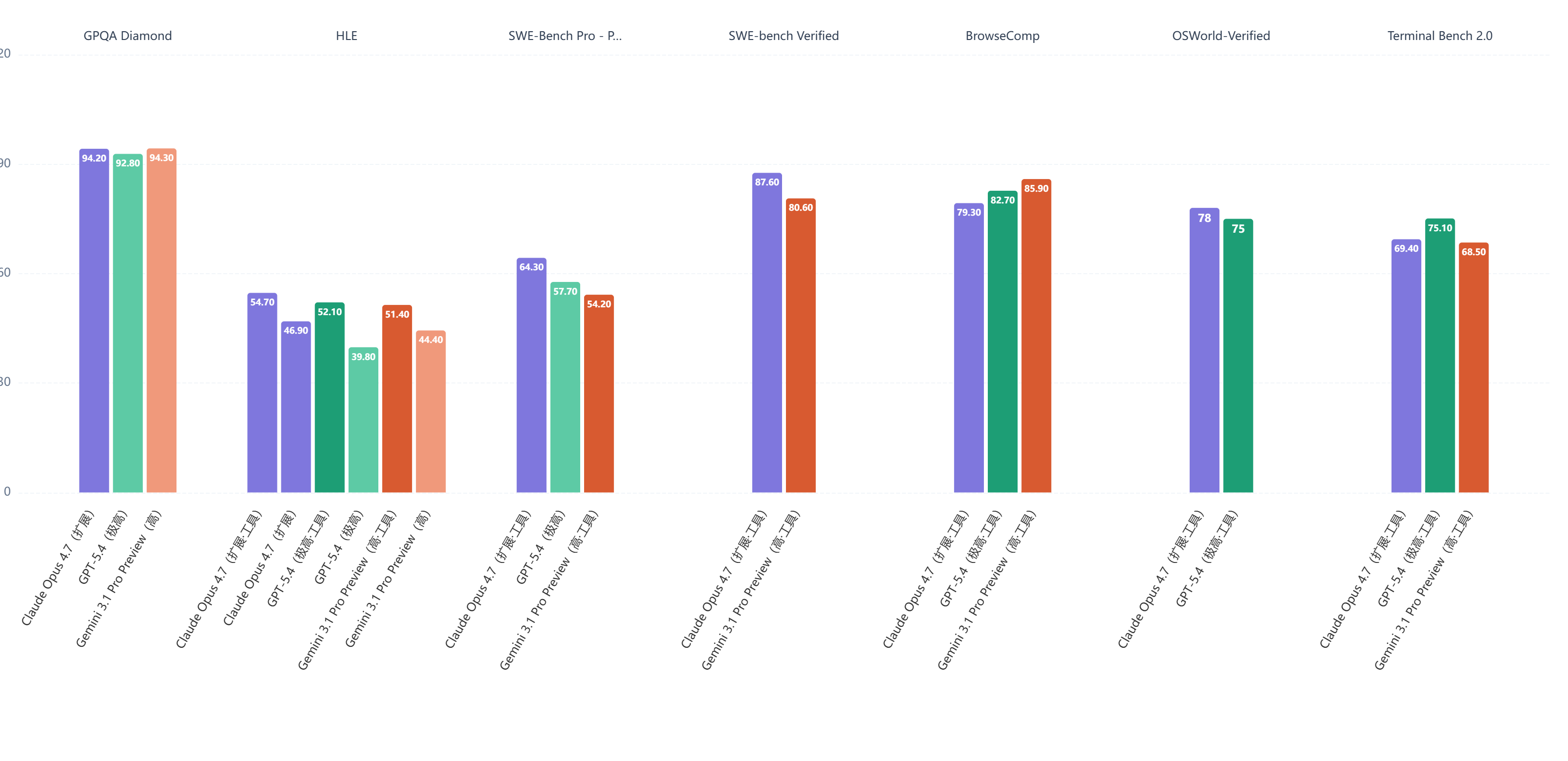
从DataLearner收录的竞品对比数据来看,Opus 4.7的强弱分布比较清晰:
编程方向优势明显:SWE-bench Verified Opus 4.7得87.60分,Gemini 3.1 Pro为80.60分,GPT-5.4暂无可比数据;SWE-Bench Pro中Opus 4.7以64.30分领先GPT-5.4的57.70分和Gemini的54.20分,差距相当显著。这是Opus 4.7最值得称道的方向。
综合推理基本持平:GPQA Diamond三者基本咬在一起(Opus 4.7:94.20,GPT-5.4:92.80,Gemini 3.1 Pro:94.30),HLE方面Opus 4.7以54.70分小幅领先(GPT-5.4:52.10,Gemini:51.40)。
Agent信息收集方向落后:BrowseComp上Opus 4.7得79.30分,而Gemini 3.1 Pro达85.90分、GPT-5.4为82.70分,这是相对薄弱的一块。Terminal Bench 2.0上也是GPT-5.4(75.10)领先Opus 4.7(69.40)。
价格方面需要正视:Opus 4.7的标准API定价($5输入/$25输出)明显高于GPT-5.4($2.5/$15,272K以内)和Gemini 3.1 Pro Preview($2/$12,200K以内)。在编程能力以外的场景,选择哪个模型需要结合具体任务和成本综合判断。
迁移注意事项:tokenizer变更与token用量变化
从Opus 4.6切换到Opus 4.7有两个变化值得提前规划:
Tokenizer更新:新版tokenizer改善了文本处理方式,但相同输入内容可能映射到更多token,测试数据显示大约是1.0–1.35倍,具体取决于内容类型。
更多推理输出:Opus 4.7在较高推理等级下,尤其是智能体任务的后期对话轮次中,会产生更多思考token。
好消息是,根据Anthropic内部编程评测,综合考虑任务完成质量和token消耗,整体效率是改善的——更高的完成率摊薄了token成本。但仍建议在真实业务流量上先做测试再切换。Anthropic提供了完整的 迁移指南。
使用方式与定价
Claude Opus 4.7今日起全面开放,支持以下渠道:
- Claude所有产品(claude.ai网页版、移动端、桌面端)
- Claude API,模型调用字符串:
claude-opus-4-7 - Amazon Bedrock
- Google Cloud Vertex AI
- Microsoft Foundry
定价与Opus 4.6一致:输入 $5/百万token,输出 $25/百万token。
关于Claude Opus 4.7的完整评测数据和竞品对比,可参考DataLearner模型评测详情页:https://www.datalearner.com/ai-models/pretrained-models/claude-opus-4-7/analysis
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
