如何提高大语言模型作为Agent的能力?清华大学与智谱AI推出AgentTuning方案
尽管开源的大语言模型发展非常迅速,但是,在以大语言模型作为核心的新一代AI Agent解决方案上,开源大语言模型比商业模型表现要明显地差。为了提高大语言模型作为AI Agent的表现和能力,清华大学和智谱AI推出了一种新的方案,AgentTuning,可以将有效增强开源大语言模型作为AI Agent的能力。
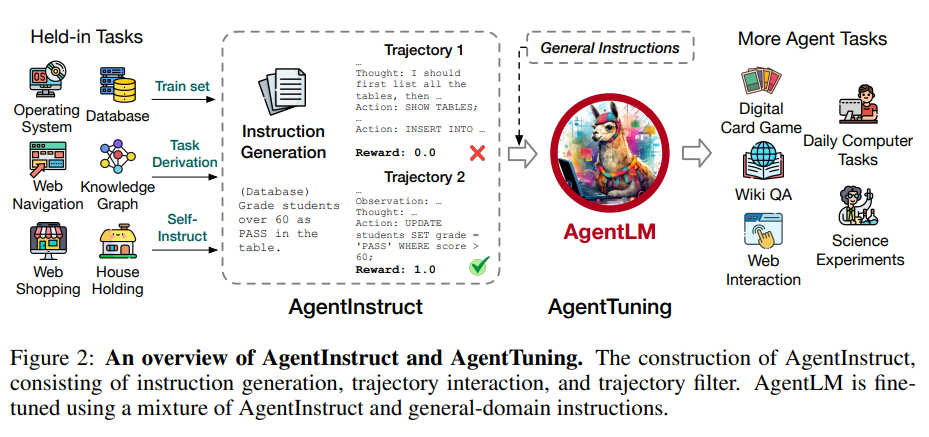
AI Agent简介
AI Agent使用一种可以感知周围环境并作出决策的一种智能系统。这种概念其实很早就提出,但是随着ChatGPT的推出,大家发现大语言模型在意图理解方面已经超越了之前的算法。因此,以大语言模型作为核心控制器来建立一个AI Agent变成一种十分具有前景的方案。

OpenAI的Safety团队的负责人Lilian Weng在2023年6月份发布的一篇博客中就介绍了AI Agent,并认为这将使LLM转为通用问题解决方案的途径之一(参考:大模型驱动的自动代理(AI Agent):将语言模型的能力变成通用能力的一种方式——来自OpenAI安全团队负责人的解释与观点)。
尽管如此,当前开源的大语言模型在这方面表现并不好。
当前开源大语言模型在AI Agent领域表现很差
开源大语言模型发展十分迅速。尽管在2022年11月底发布的ChatGPT引起全球的关注,商业大模型如何Google Bard、Claude AI等发展十分迅速,但是开源领域的大模型的进步也十分地迅速。下图是DataLearner大模型评估排行的一个截图:
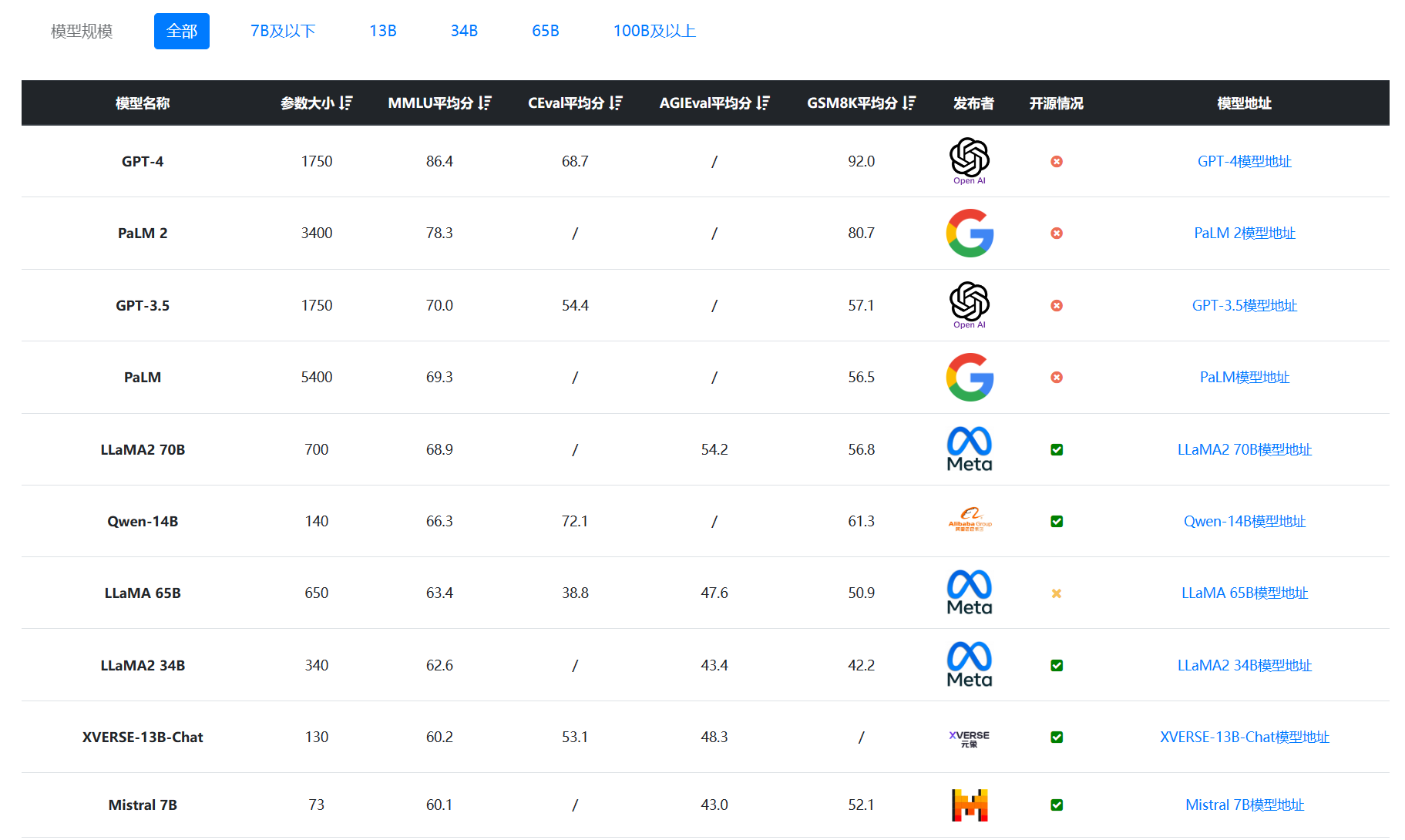
可以看到,在MMLU的理解能力上,开源大模型的得分非常高。但是,即便开源大语言模型发展速度很快,在AI Agent领域依然无法与闭源大模型比较。例如,MetaGPT、AutoGPT等都是默认使用GPT-4作为控制中心。
这个原因主要是,AI Agent代理任务要求LLMs扮演中心控制器的角色,负责计划、记忆和工具使用,这既需要细粒度的提示方法,又需要强大的LLMs来获得满意的性能。开源大型语言模型在作为AI代理处理复杂任务时面临的主要挑战是它们需要在细粒度的提示和强大的模型之间达到平衡,同时还要保持其广泛的应用能力。这是非常困难的。
现有针对LLM代理能力的研究主要关注设计提示或构建框架来完成某一特定代理任务,而没有从根本上提升LLM自身的通用代理能力。许多相关工作专注于提升LLM在特定方面的能力,这通常以牺牲其通用能力为代价,也降低了其泛化能力。针对上述问题,清华大学与智谱AI提出了AgentTuning方法。
AgentTuning方案详解
如前所述,研究人员认为当前LLM作为AI Agent控制器的解决方案几乎都是从prompt工程操作。而实际上采用指令调优的方式更加合适。
AgentTuning方案主要包含以下两个部分:
- AgentInstruct数据集构建
-
从6种不同的代理任务中收集高质量的交互轨迹,包含完整的指令、环境反馈、模型思考和行动等信息。
-
对GPT-4生成的轨迹进行过滤,只保留完全正确的轨迹。
-
最终获得了1866条交互轨迹。
Agent Instruct数据集的具体内容如下:
其中:
- 指令来源:指令的获取方式。
- 指令数目:获取的初始指令总数。
- 过滤轨迹数:根据奖励进行过滤后的轨迹数目。
- 平均过滤轨迹回合数:过滤轨迹的平均对话回合数。
- 比例:过滤轨迹数占初始指令数目的比例。
- 混合指令调优策略
-
利用ShareGPT数据集中用户与GPT-3.5和GPT-4的对话,获取通用领域的指令语料。
-
将AgentInstruct和通用语料按一定比例混合,进行监督微调。
-
比例的设置通过在7B模型上扫描确定,最终选择0.2的AgentInstruct比例。
-
在Llama 2聊天机器人系列模型的基础上微调,得到AgentLM。
-
AgentInstruct提供了代理任务方面的指导,通用语料提供了通用能力。两者的结合可以在提升代理能力的同时保持模型的泛化能力。
整个方案相对简单,但通过高质量和不同任务领域的指令语料,以及控制比例的混合调优策略,可以有效提升LLM在复杂代理任务中的泛化能力,使其成为真正意义上的通用智能代理。
AgentTuning效果评估
根据前面的分析其实也可以看处理,AgentTuning的核心是微调了一个大模型LLaMA2,使用的是AgentInstruct数据集,而比较不同模型作为核心控制器之后,我们可以看到如下对比结果:
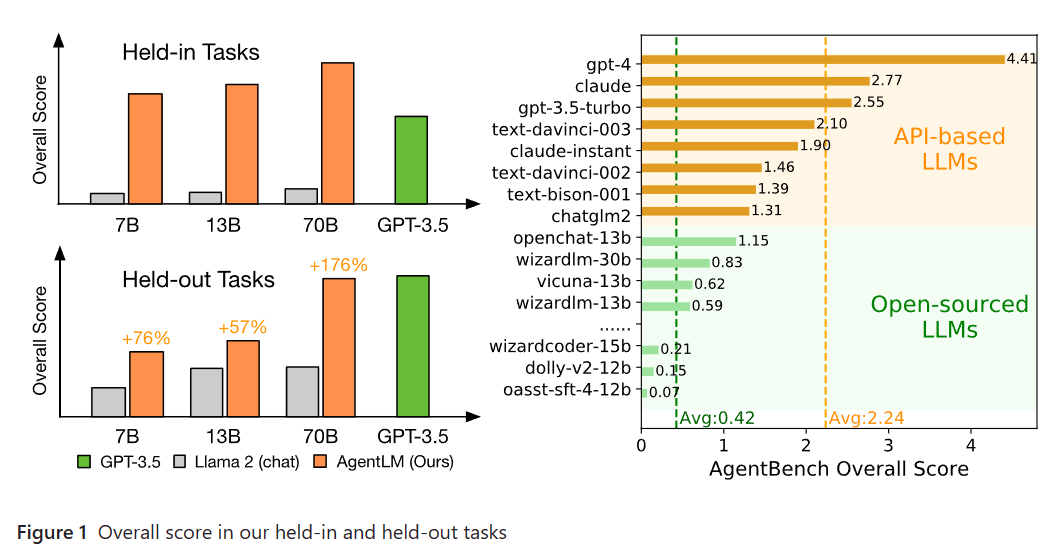
相比较基础模型LLaMA2,微调后的AgentLM模型在各个方面的任务评分上都有非常大的提高。尽管70B版本的模型不如GPT-4,比GPT-3.5略差,但是已经提高很多了!
AgentTuning总结
-
增强的代理能力:AgentTuning是设计用来增强大型语言模型(LLMs)的代理能力的方法,同时尽量保持其通用的LLM能力。这意味着,通过使用AgentTuning,LLMs不仅在特定的代理任务上表现得更好,而且在其他通用任务上仍然有效。
-
错误减少:使用AgentTuning可以显著减少基本错误,如格式错误、重复生成和拒绝回答。这表明AgentTuning能够提高模型的稳定性和可靠性。
-
广泛的应用:AgentTuning旨在为代理任务提供一个既开放又强大的替代方案,与商业LLMs相比。
-
结构和组件:AgentTuning包括两个主要组件:一个轻量级的指导调优数据集AgentInstruct,和一个混合的指导调优策略,该策略旨在增强代理的能力,同时保持其泛化能力。
综上所述,AgentTuning的评估结果显示,它有效地增强了LLMs的代理能力,同时保持了其在通用任务上的性能。它还成功地减少了模型在执行任务时的基本错误。
AgentTuning开源资源
此次,清华大学与智谱AI也完全开源了相关工作的结果。包括AgentInstruct数据集和微调后的AgentLM。
其中,AgentInstruct数据集开源地址:https://huggingface.co/datasets/THUDM/AgentInstruct
三个AgentLM模型的地址参考DataLearner模型信息卡:
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
