DataLearnerAI-GPT:可以回答关于大模型评测结果的GPT
最近自定义GPTs非常火热,出现了大量的自定义GPT,可以完成各种各样的有趣的任务。DataLearnerAI目前也创建了一个DataLearnerAI-GPT,目前可以回答大模型在不同评测任务上的得分结果。这些回答是基于OpenLLMLeaderboard数据回答的。未来会考虑增加更多信息,包括DataLearner网站上所有的大模型博客和技术介绍。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
最近自定义GPTs非常火热,出现了大量的自定义GPT,可以完成各种各样的有趣的任务。DataLearnerAI目前也创建了一个DataLearnerAI-GPT,目前可以回答大模型在不同评测任务上的得分结果。这些回答是基于OpenLLMLeaderboard数据回答的。未来会考虑增加更多信息,包括DataLearner网站上所有的大模型博客和技术介绍。

随着大型语言模型(LLM)如 GPT-3 和 BERT 在 AI 领域的崛起,如何在实际应用中高效地进行模型推断成为了一个关键问题。为此,英伟达推出了全新的大模型推理提速框架TensorRT-LM,可以将现有的大模型推理速度提升4倍!

当谈及人工智能的巨大进步,大模型的崛起无疑是其中的一个重要里程碑。这些大模型,如GPT-3,已经展现出令人惊叹的语言生成和理解能力,但是为了让它们在特定任务上发挥最佳性能,大模型微调(Fine-tuning)是一种非常优秀的方法。微调是一种将预训练的大型模型进一步优化,以适应特定任务或领域的过程。但微调并不是很简单,今天吴恩达联合Lamini推出了全新的大模型微调短课《Finetuning Large Language Models》。

刚刚,吴恩达宣布deeplearning.ai 与 Cohere 合作推出了一个新课程:“Large Language Models with Semantic Search”。这个课程主要教授大家如何使用LLMs进行语义搜索,还提供了大量实践经验,来克服搜索结果和准确性等挑战。

XVERSE-13B是元象开源的一个大语言模型,发布一周后就登顶HuggingFace流行趋势榜。该模型最大的特点是支持多语言,其中文和英文水平都十分优异,在评测结果上超过了Baichuan-13B,与ChatGLM2-12B差不多,不过ChatGLM2-12B是收费模型,而XVERSE-13B是免费商用授权!
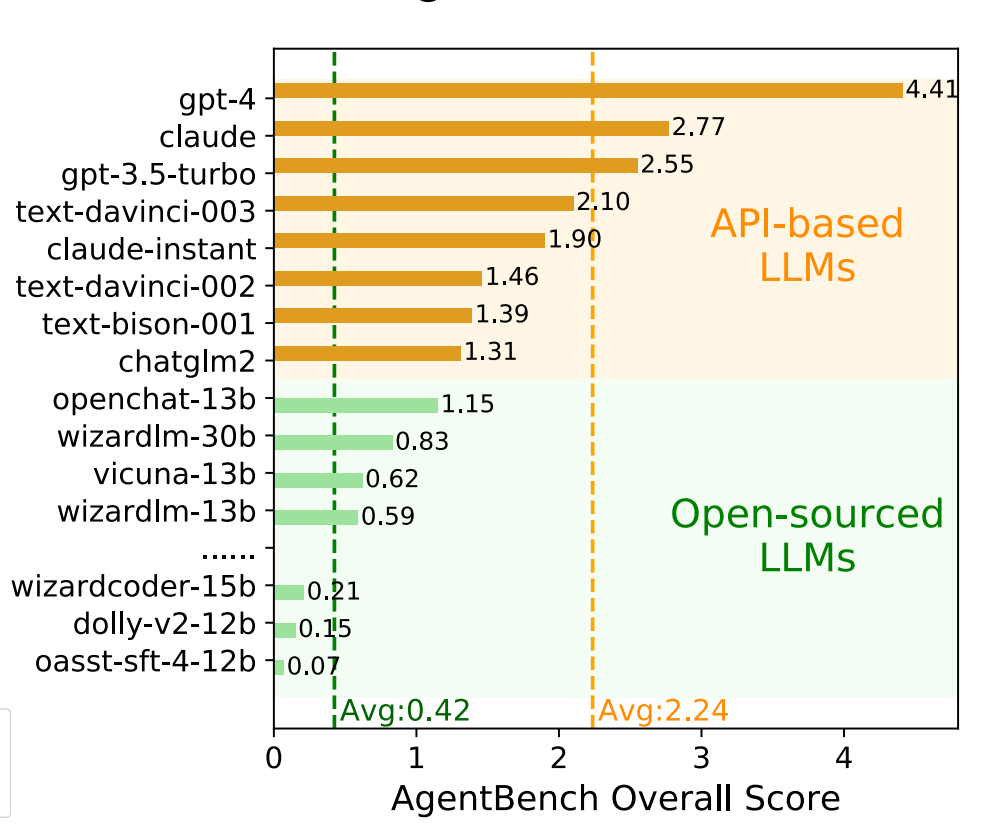
所谓AI Agent就是一个以LLM为核心控制器的一个代理系统。业界开源的项目如AutoGPT、GPT-Engineer和BabyAGI等,都是类似的例子。然而,并不是所有的AI Agent都有很好的表现,其核心还是取决于LLM的水平。尽管LLM已经在许多NLP任务上取得进步,但它们作为代理完成实际任务的能力缺乏系统的评估。清华大学KEG与数据挖掘小组(就是发布ChatGLM模型)发布了一个最新大模型AI Agent能力评测数据集,对当前大模型作为AI Agent的能力做了综合测评,结果十分有趣。
今天发现另一个可以替代官方API的接口网站,OpenRouter。尽管OpenAI和Anthropic的模型非常好,但是开发者使用需要申请API,但是,这两个服务的API申请非常麻烦。而OpenRouter目前提供了这些接口的付费调用,价格与官网完全一致,十分良心!

ChatGPT是属于生成式AI的一种应用。由于其强大的效果已经变成了当前最主流的一种AI方案。而构建生成式AI应用的一个重要方向是构建友好的web形态的demo让用户能快速体验。Gradio就是这样一种开源方案,也是当前最流行的一种快速构建AI Web应用的方案。昨天吴恩达的DeepLearningAI与HuggingFace共同推出了最新的一期短课程《Building Generative AI Applications with Gradio》,教大家如何使用Gradio快速构建生成式AI的应用。
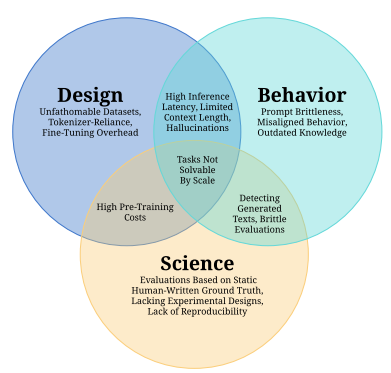
前天,EleutherAI、MetaAI、StabilityAI、伦敦大学等研究人员合作提交了一个关于大语言模型(Large Language Model,LLM)的挑战和应用的论文综述,引用了688篇参考文献总结了当前LLM的主要挑战和应用方向。

当前大模型本质是一种大语言模型(Large Language Models, LLM),其核心能力是对语言的处理。良好的意图识别和文本生成能力让LLM超越了之前的模型,有了巨大的实用价值。但是,现实问题涉及了很多超越语言模型之外的能力,如基于最新数据的文本摘要、向用户提供实时数据分析和可视化结果、为代码提供debugging等。目前,让LLM解决这些问题的一个最有前景的方向就是建立大模型驱动的自动代理。也就是让LLM作为核心控制者来学会使用不同工具,进而完成最终任务。

LangChain是当前大模型应用开发领域里面最火热的框架。由于其提供了丰富的数据访问接口、各种大模型的交互接口以及很多构造大模型应用所需要的方法与实践工具,受到了很多人的关注。然而,今天Hacker News上的一位开发者直接提出LangChain是一个无用的框架,引起了很多人的共鸣。很多人都表示,在实际开发中,LangChain有很多问题,可能并不适合用来做大模型应用开发。

吴恩达的DeepLearningAI在今天和LangChain的创始人一起合作发布了一个最新的基于LangChain使用LLM构建私有数据的问答系统和聊天机器人的课程(课程名:《LangChain: Chat with Your Data》)。LangChain是大语言模型应用开发领域目前最火的开源库。集成十分多的优秀特性,可以帮助我们非常简单构建LLM的应用。

目前开源领域已经有一些模型宣称支持了8K甚至是更长的上下文。那么这些模型在长上下文的支持上表现到底如何?最近LM-SYS发布了LongChat-7B和LangChat-13B模型,最高支持16K的上下文输入。为了评估这两个模型在长上下文的表现,他们对很多模型在长上下文的表现做了评测,让我们看看这些模型的表现到底怎么样。
Salesforce是全球最大的CRM企业,但是在开源大模型领域,它也是一个不可忽视的力量。今天,Salesforce宣布开源全新的XGen-7B模型,是一个同时在文本理解和代码补全任务上都表现很好的模型,在MMLU任务和代码生成任务上都表现十分优秀。最重要的是,它的2个基座模型XGen-7B-4K-Base和XGen-7B-8K-Base都是完全开源可商用的大模型。
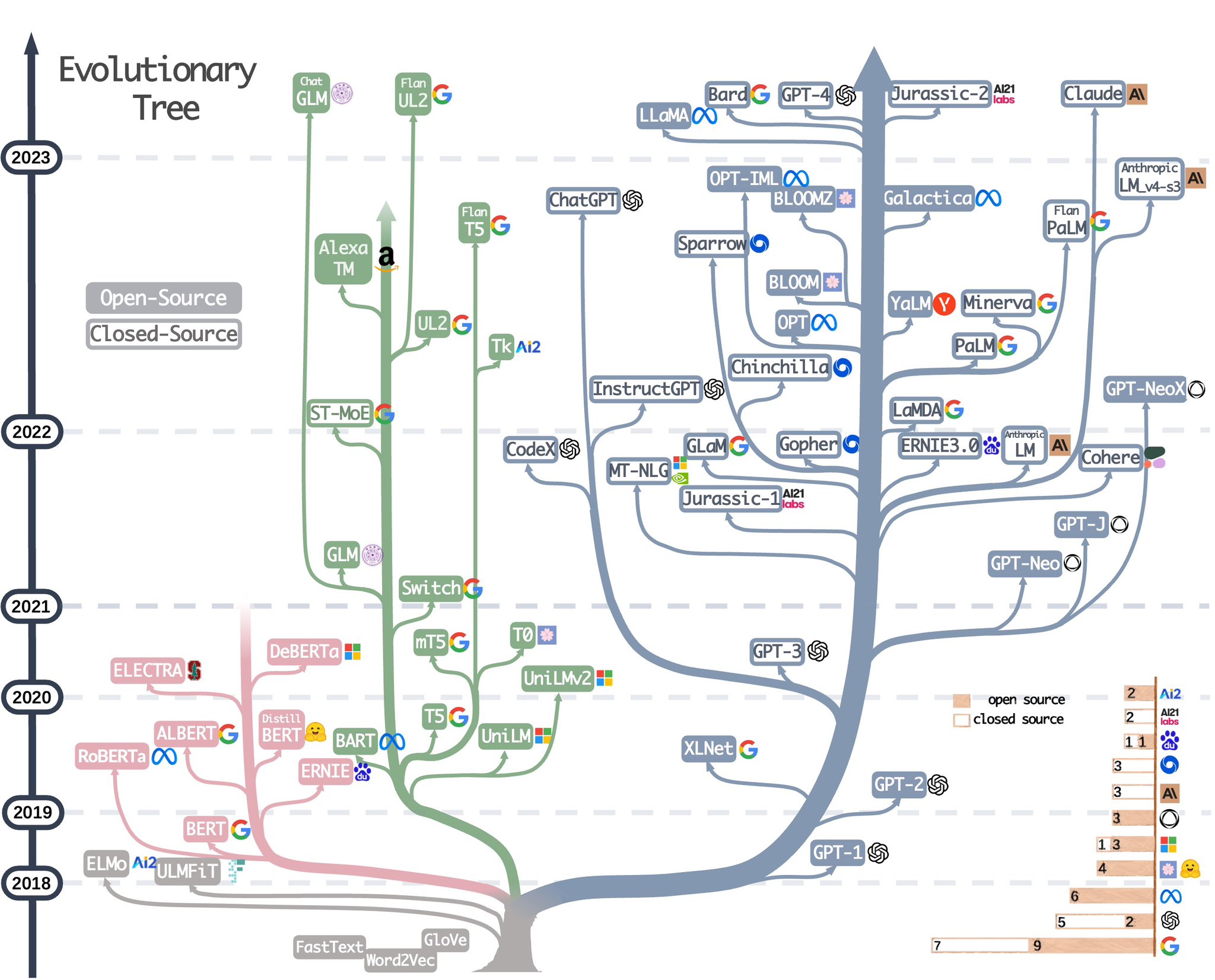
4月26日,亚马逊联合其它高校科研人员发表了一篇关于如何使用ChatGPT完成下游论文。里面使用了一个非常直观明了的大语言模型进化图总结了目前当前大语言模型的技术架构分类和开源现状,十分受欢迎。因此,4月30日,作者再次更新这幅图,增加了更多的大语言模型。

在今年的Microsoft Build 2023大会上,来自OpenAI的研究员Andrej Karpathy在5月24日的一场汇报中用了40分钟讲解了ChatGPT是如何被训练的,其中包含了训练一个能支持与用户对话的GPT的全流程以及涉及到的一些技术。信息含量丰富,本文根据这份演讲总结。

昨天,HuggingFace的大语言模型排行榜上突然出现了一个评分超过LLaMA-65B的大语言模型:Falcon-40B,引起了广泛的关注。本文将简要的介绍一下这个模型。截止2023年5月27日,Falcon-40B模型(400亿参数)在推理、理解等4项Open LLM Leaderloard任务上评价得分第一,超过了之前最强大的LLaMA-65B模型。

虽然LLM在很多任务上很好用,但是实际应用中我们常见的文本分类、文本标注等工作目前却依然缺少一个可以利用LLM能力的好方法。LLM的强大并没有在工程落地上比肩传统的机器学习处理框架。上周,一个叫Scikit-LLM新的开源项目发布,将传统优秀的Scikit-learn框架与LLM结合,带来了LLM落地的新方法。
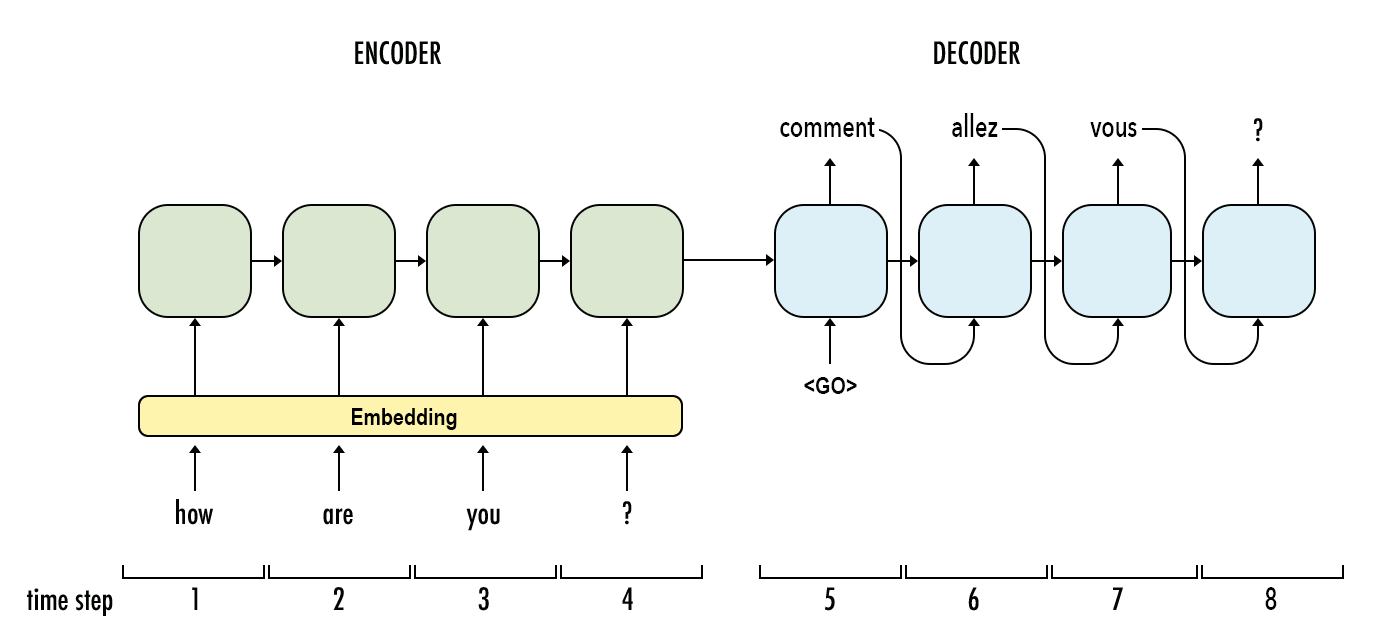
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。

随着ChatGPT的火爆以及MetaAI开源了LLaMA,各家公司好像一夜之间都有了各种ChatGPT模型的研发实力。而针对不同任务和应用构建的LLM更是层出不穷。那么,如何选择合适的模型完成特定的任务,甚至是使用多个模型完成一个复杂的任务似乎仍然很困难。为此,浙江大学与微软亚洲研究院联合发布了一个大模型写作系统HuggingGPT,可以根据输入的任务帮我们选择合适的大模型解决!

这是OpenAI官方的cookebook最新更新的一篇技术博客,里面说明了为什么我们需要使用embeddings-based的搜索技术来完成问答任务。

本文是Replit工程师发表的训练自己的大语言模型的过程的经验和步骤总结。Replit是一家IDE提供商,它们训练LLM的主要目的是解决编程过程的问题。Replit在训练自己的大语言模型时候使用了Databricks、Hugging Face和MosaicML等提供的技术栈。这篇文章提供的都是一线的实际经验,适合ML/AI架构师以及算法工程师学习。