“GPT”的模型太多无法选择?让大模型帮你选择大模型!浙江大学发布HuggingGPT!
随着ChatGPT的火爆以及MetaAI开源了LLaMA,各家公司好像一夜之间都有了各种ChatGPT模型的研发实力。而针对不同任务和应用构建的LLM更是层出不穷。那么,如何选择合适的模型完成特定的任务,甚至是使用多个模型完成一个复杂的任务似乎仍然很困难。为此,浙江大学与微软亚洲研究院联合发布了一个大模型写作系统HuggingGPT,可以根据输入的任务帮我们选择合适的大模型解决!
HuggingGPT利用ChatGPT读取HuggingFace上所有的模型接口,然后根据你的输入分解成不同任务交给不同的模型执行。这意味着你可以毫不费力的拥有完整的多模态能力,图片、文本、视频、语音甚至是3D任务等,都可以完全由文本输入后与各种模型交互产生最终结果,也就是可以做出任意的text-to-image-to-video-to-text-to-speech!绝对的好idea啊!
本文主要介绍一下这个HuggingGPT!
一、当前LLMs的缺陷
尽管大模型取得了如此巨大的成功,但当前的LLM技术仍然存在缺陷,面临着建立AGI系统的一些紧迫挑战。
- 受限于文本生成的输入和输出形式,当前LLMs缺乏处理复杂信息(如视觉和语音)的能力;
- 在实际应用场景中,一些复杂任务通常由多个子任务组成,因此需要多个模型的调度和协作,这也超出了语言模型的能力范围;
- 对于一些具有挑战性的任务,LLMs在零样本或少样本设置下表现出优异的结果,但它们仍然不如一些专家(如微调模型)强
为了处理复杂的人工智能任务,LLMs应该能够与外部模型协调以利用它们的能力。因此,关键点在于如何选择合适的中间件来桥接LLMs和人工智能模型之间的连接。
二、HuggingGPT简介
准确来说HuggingGPT是一个协作系统,而不是一个大模型。它用于连接LLMs(即ChatGPT)和ML社区(即HuggingFace),可以处理来自不同模态的输入并解决众多复杂的人工智能任务。具体而言,对于HuggingFace中的每个人工智能模型,HuggingGPT使用库中的相应模型描述,并将其融合到提示中以建立与ChatGPT的连接。随后,HuggingGPT将LLMs(即ChatGPT)将作为大脑来确定用户问题的答案。
下图就是这个方案的主要思想:
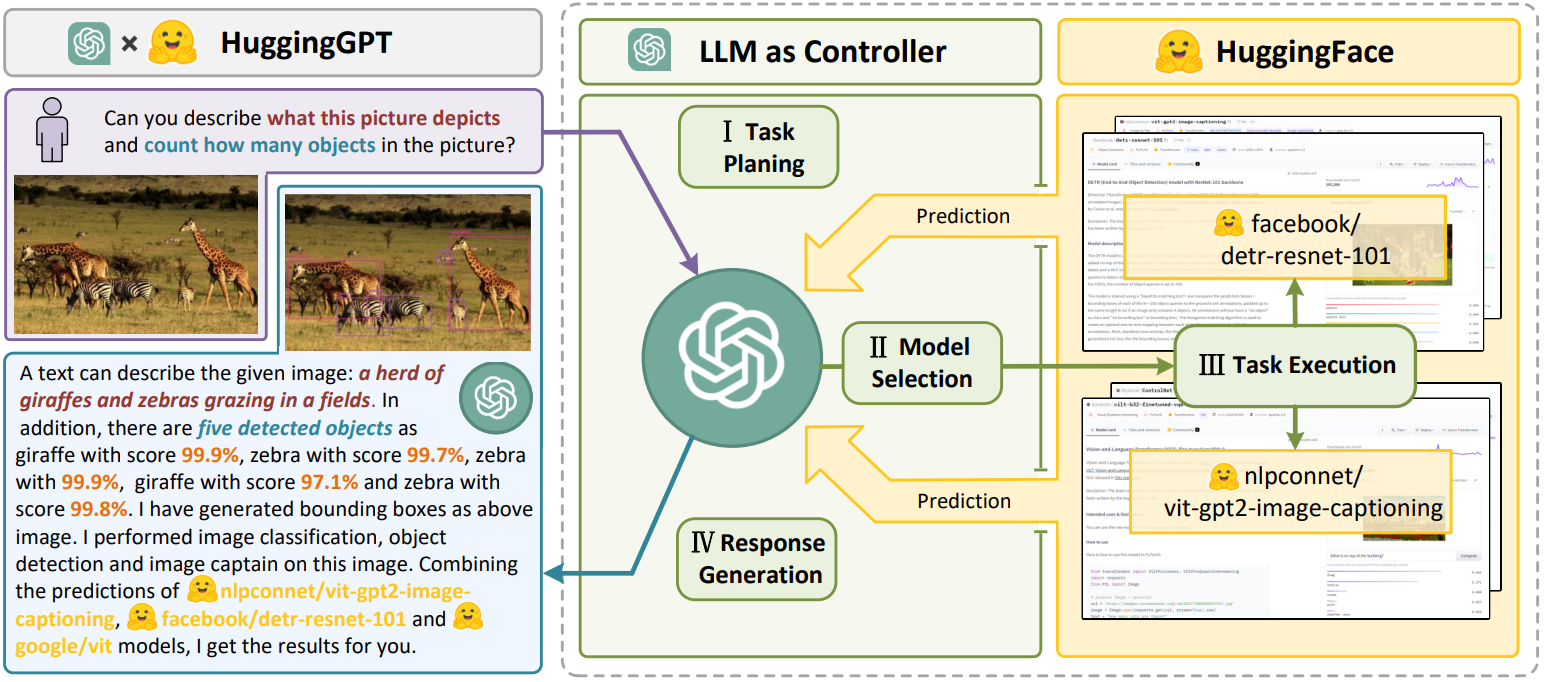
简单来说,就是HuggingGPT将HuggingFace社区上所有的模型简介作为输入,放到模型上。然后根据用户输入的问题去解析匹配,然后决定使用哪个模型来解决。
HuggingGPT是一个协作系统,由大型语言模型(LLM)作为控制器和众多专家模型作为协作执行者组成。HuggingGPT的工作流程包括四个阶段:任务规划、模型选择、任务执行和响应生成。
下图是具体的工作流程:

具体来说就是:
- LLM(如ChatGPT)首先解析用户请求,将其分解为多个任务,并根据其知识规划任务顺序和依赖关系;
- LLM根据HuggingFace中的模型描述将解析后的任务分配给专家模型;
- 专家模型在推理端点上执行分配的任务,并将执行信息和推理结果记录到LLM中;
- 最后,LLM总结执行过程日志和推理结果,并将摘要返回给用户。
三、HuggingGPT用法总结
这个真的是非常赞的想法。文中给出一个例子:让HuggingGPT生成一个视频,其标题是"An astronaut is walking in space",并且为其配音。
HuggingGPT的工作过程是: 任务规划,将上述任务分成2个,一个是text-to-video,一个是text-to-speech。然后分别为二者挑选合适的模型生成即可。
还有个例子是读取图片中的文本,显然这个任务可以分为image-to-text和text-to-speech。当然,HuggingGPT也能分辨出每个任务的输入参数是啥。
四、HuggingGPT的开源使用
好消息是这个系统已经由微软开源在GitHub上了~并且命名为Jarvis!(钢铁侠虎躯一震!哈哈哈!)
不过这个系统给的使用依赖OpenAI的账户,所以你们懂的。有了OpenAI的APIkey之后就可以使用。
HuggingGPT的使用步骤:
下载官方项目并启动服务端:
# setup env
cd server
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch
pip install git+https://github.com/huggingface/diffusers.git
pip install git+https://github.com/huggingface/transformers
pip install -r requirements.txt
# download models
cd models
sh download.sh
# run server
cd..
python bot_server.py
python model_server.py
然后安装并打开web服务
cd web
npm install
npm run dev
接下来就可以直接使用了。

好像一下子就有了模型的多模态的能力。而且随着HuggingFace上模型的丰富,未来几乎所有HuggingFace的模型可能都可以被直接使用了,实在是太酷了!
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
