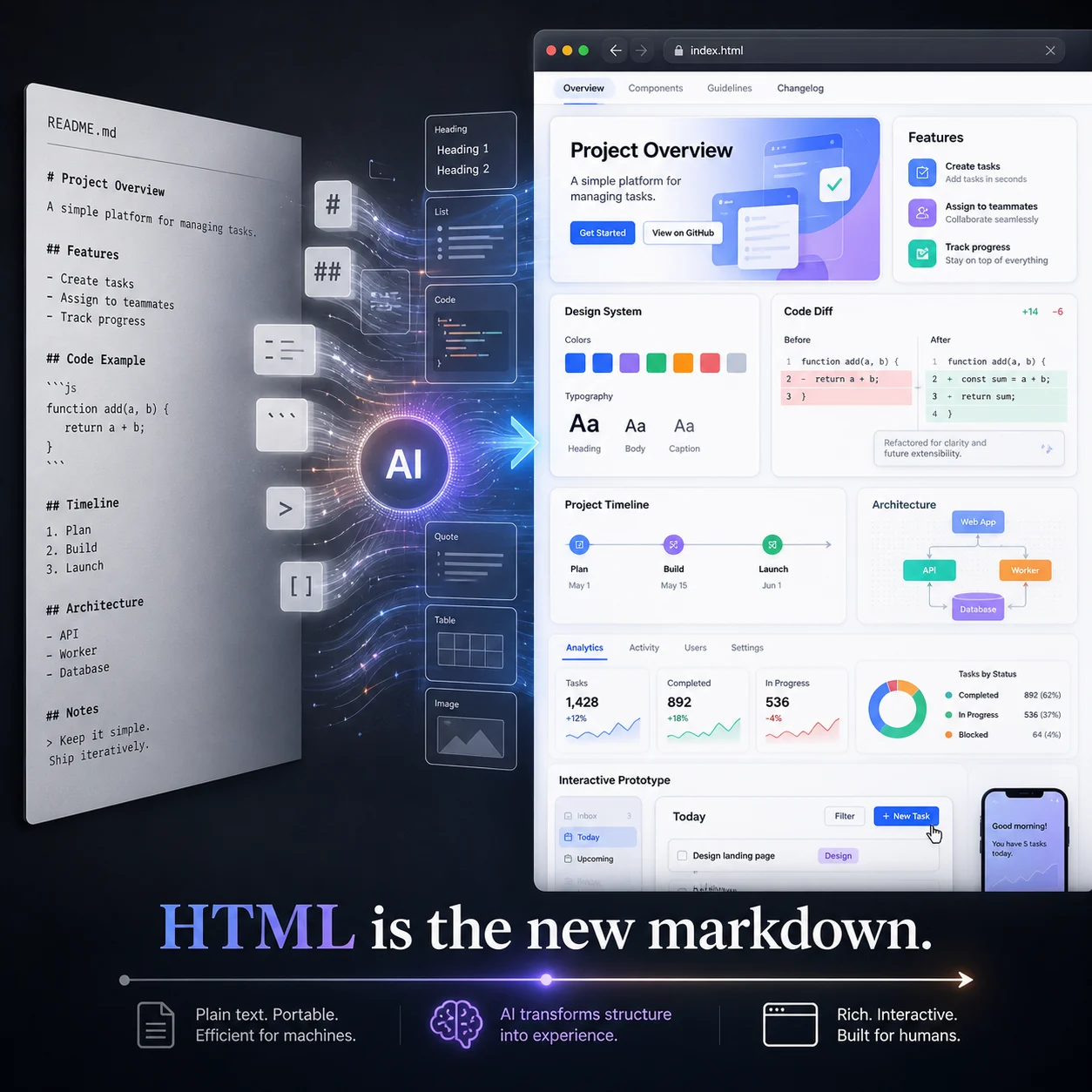
HTML是AI输出的新标准吗?一个来自Anthropic工程师的挑衅性论断
Anthropic Claude Code工程师Thariq发文称HTML应取代Markdown成为AI输出的新标准,并提供了20个HTML示例覆盖代码审查、设计系统、原型交互等9类场景。本文分析了HTML胜出的三类结构性原因——空间信息降维损失、交互体验不可替代、HTML作为原生交付介质,同时指出该论断在token成本和生成速度约束下过于绝对。文章进一步探讨了AI文档格式的终局:结构化数据+渲染分离、模板填充、AI-native语义格式等可能方向。