大语言模型的技术总结系列一:RNN与Transformer架构的区别以及为什么Transformer更好
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
汇总「RNN」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
大语言模型(Large Language Model,LLM)是近几年进展最大的AI模型。早期的深度学习架构语言模型以RNN为主,现在则基本上转成了Transformer的架构。尽管如此,Transformer本身也是有着不同的区别。而本文是大语言模型系列中的一篇,主要介绍RNN模型与Transformer之间的区别。
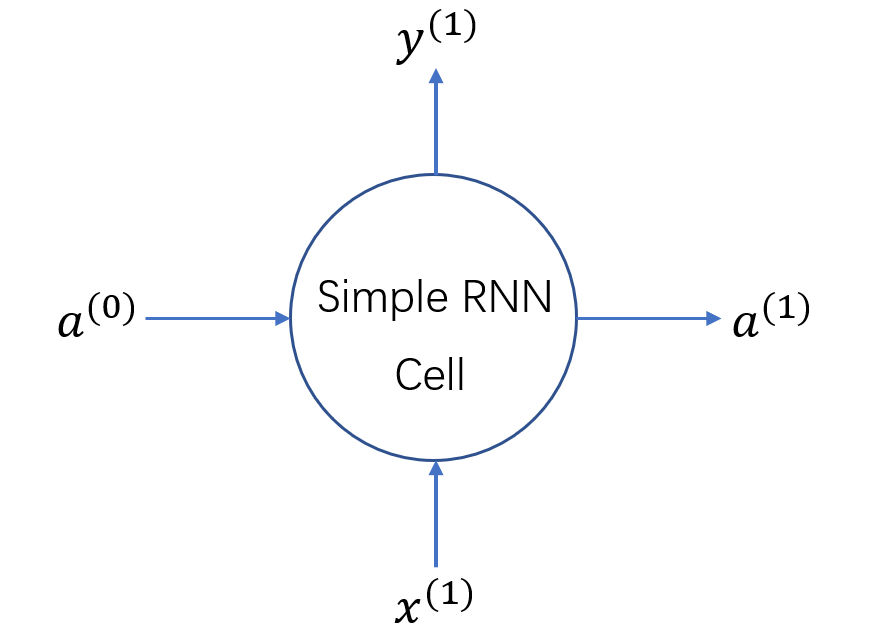
RNN的应用有很多,尤其是两个RNN组成的Seq2Seq结构,在时序预测、自然语言处理等方面有很大的用处,而每个RNN中一个节点是一个Cell,它是RNN中的基本结构。本文从如何使用RNN建模数据开始,重点解释RNN中Cell的结构,以及Keras中Cell相关的输入输出及其维度。我已经尽量解释了每个变量,但可能也有忽略,因此可能对RNN之前有一定了解的人会更友好,本文最主要的目的是描述Keras中RNNcell的参数以及输入输出的两个注意点。如有问题也欢迎指出,我会进行修改。
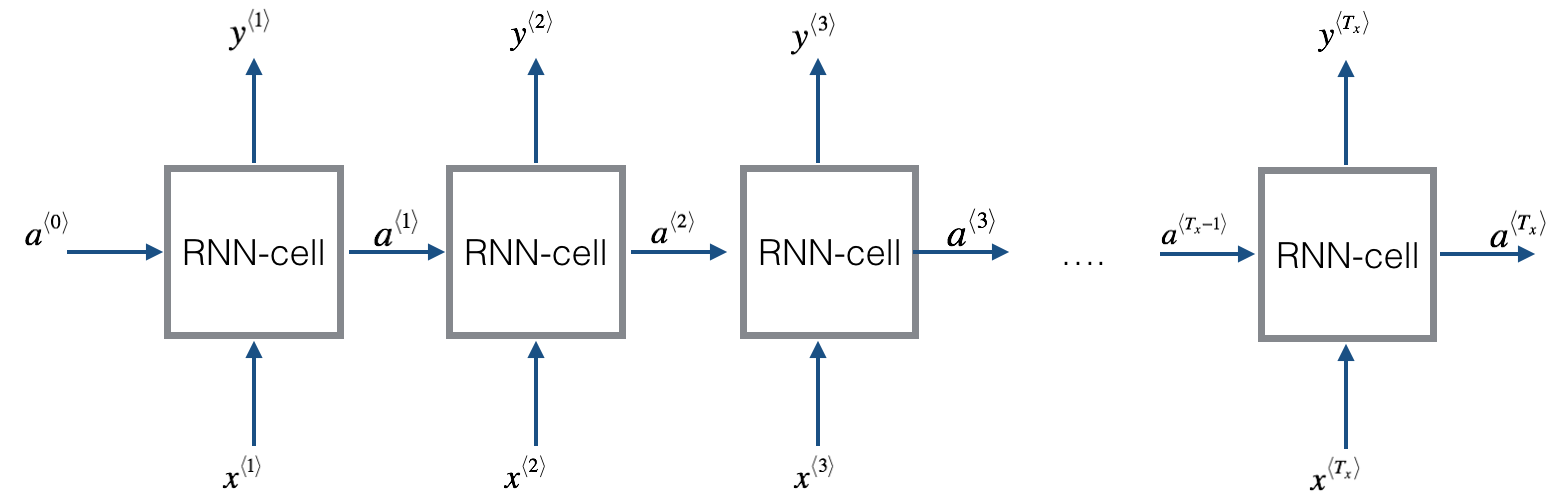
之前面的博客中,我们已经描述了基本的RNN模型。但是基本的RNN模型有一些缺点难以克服。其中梯度消失问题(Vanishing Gradients)最难以解决。为了解决这个问题,GRU(Gated Recurrent Unit)神经网络应运而生。本篇博客将描述GRU神经网络的工作原理。GRU主要思想来自下面两篇论文:
在前面的博客中,我们已经介绍了基本的RNN模型和GRU深度学习网络,在这篇博客中,我们将介绍LSTM模型,LSTM全称是Long Short-Time Memory,也是RNN模型的一种。
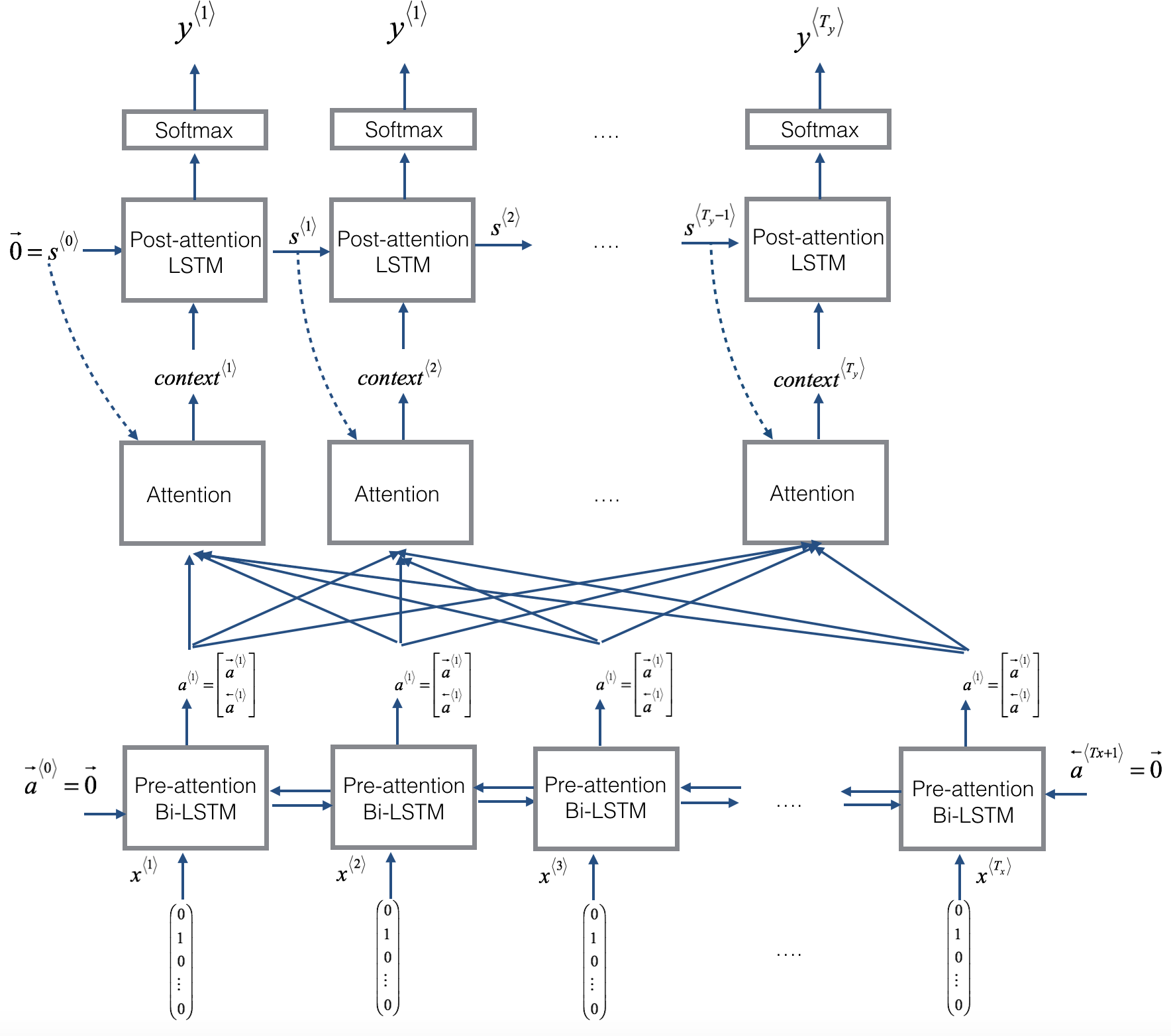
Encoder-Decoder的深度学习架构是目前非常流行的神经网络架构,在许多的任务上都取得了很好的成绩。在之前的博客中,我们也详细介绍了该架构(参见深度学习之Encoder-Decoder架构)。本篇博客将详细讲述Attention机制。

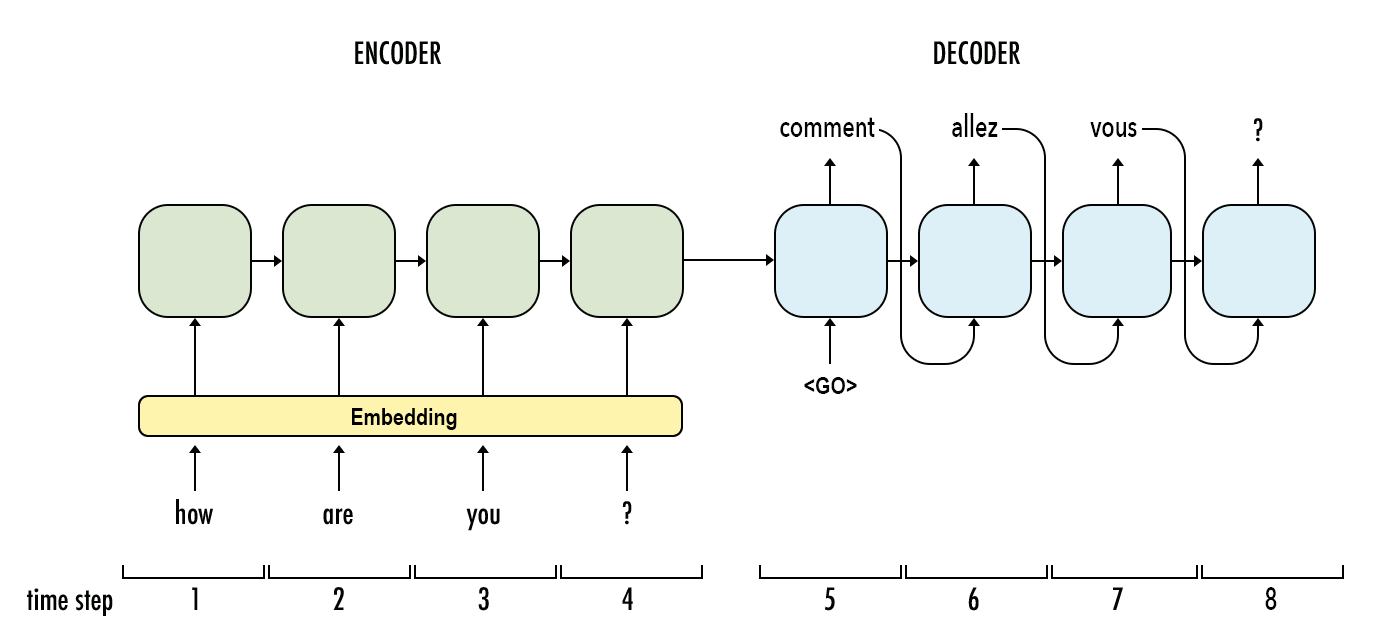
深度学习中Sequence to Sequence (Seq2Seq) 模型的目标是将一个序列转换成另一个序列。包括机器翻译(machine translate)、会话识别(speech recognition)和时间序列预测(time series forcasting)等任务都可以理解成是Seq2Seq任务。RNN(Recurrent Neural Networks)是深度学习中最基本的序列模型。
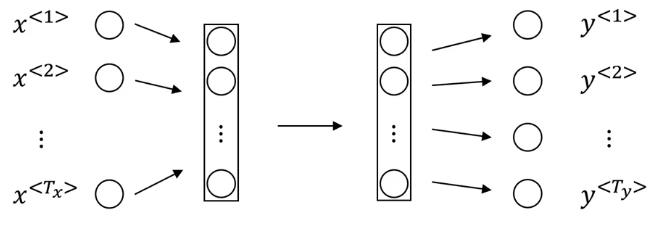
序列数据是生活中很常见的一种数据,如一句话、一段时间某个广告位的流量、一连串运动视频的截图等。在这些数据中也有着很多数据挖掘的需求。RNN就是解决这类问题的一种深度学习方法。其全称是Recurrent Neural Networks,中文是递归神经网络。主要解决序列数据的数据挖掘问题。
![[翻译]应用到文本领域的卷积方法](https://www.datalearner.com/resources/blog_images/datalearner_blog_default_img.jpg)
本文介绍了文本领域的相关任务和技术,探讨了循环神经网络在文本领域的优势,并进一步研究了应用在文本领域的卷积网络方法,原文地址:https://medium.com/@TalPerry/convolutional-methods-for-text-d5260fd5675f