重磅!第二代通义千问大模型开源,阿里巴巴一口气开源了30个不同参数规模的模型,其中Qwen1.5-72B仅次于GPT-4.
Qwen大语言模型是由阿里巴巴训练并开源的一系列大语言模型。最早是在2023年8月份开源70亿参数规模,随后几个月时间内陆续开源了4个不同规模版本的模型,最低参数18亿,最高参数720亿。而今天阿里巴巴开源了他们家第二代的Qwen系列大语言模型(准确说是1.5代),从官方给出的测评结果看,Qwen1.5系列大模型相比较第一代有非常明显的进步,其中720亿参数规模版本的Qwen1.5-72B-Chat在各项评测结果中都非常接近GPT-4的模型,在MT-Bench的得分中甚至超过了此前最为神秘但最接近GPT-4水平的Mistral-Medium模型。
Qwen2大语言模型简介
此次阿里巴巴开源的Qwen2系列大模型包含6个不同参数规模的版本,分别是5亿、18亿、40亿、70亿、140亿和720亿。相比较第一代,增加了5亿规模版本和40亿参数规模版本。
而这6个不同参数规模版本的模型,每一个都开源了基础预训练版本、聊天优化版本、Int4量化、Int8量化以及AWQ版本,所以相当于每一个参数规模的模型都有5个版本,因此一共发布了30个版本的模型!
在此前的各种泄露的信息中,官方都称这些模型为Qwen2-beta版本,可能是考虑到升级,本次发布的时候所有的Qwen2名称改为了Qwen1.5。
Qwen1.5系列模型的特点总结如下:
- 有6个不同参数模型版本(0.5B, 1.8B, 4B, 7B, 14B 和 72B),最小的仅5亿参数,最大的有720亿参数;
- 聊天优化版本的模型相比较第一代模型有明显的进步,其中720亿参数的Qwen1.5-72B在MT-Bench得分仅次于GPT-4;
- 基座版本和聊天版本在多语言方面的能力得到增强,包括中英文在内,共支持12种语言(如日语、俄语、法语西班牙语等);
- 所有版本模型最高支持32K的长上下文输入;
- 支持系统提示,可以完成Roleplay;
- 生态完善,发布即支持vLLM、SGLang等推理加速框架;
- 支持不同的量化框架;
- 月活1亿以下直接商用授权,月活1亿以上商用需要获取授权;
Qwen1.5大语言模型的评测结果
Qwen1.5的综合评分
官方公布了Qwen1.5系列模型在不同评测结果上的得分情况。如下图所示:
从这个评测结果看,Qwen1.5模型十分有竞争力,就英文理解和通识能力(MMLU)来说,Qwen1.5-72B版本几乎各项得分都超过了Llama2系列以及此前大火的MoE模型Mixtral-8x7B。
在DataLearnerAI的模型评测数据收集上,Qwen1.5-72B的表现也是全球靠前的结果:
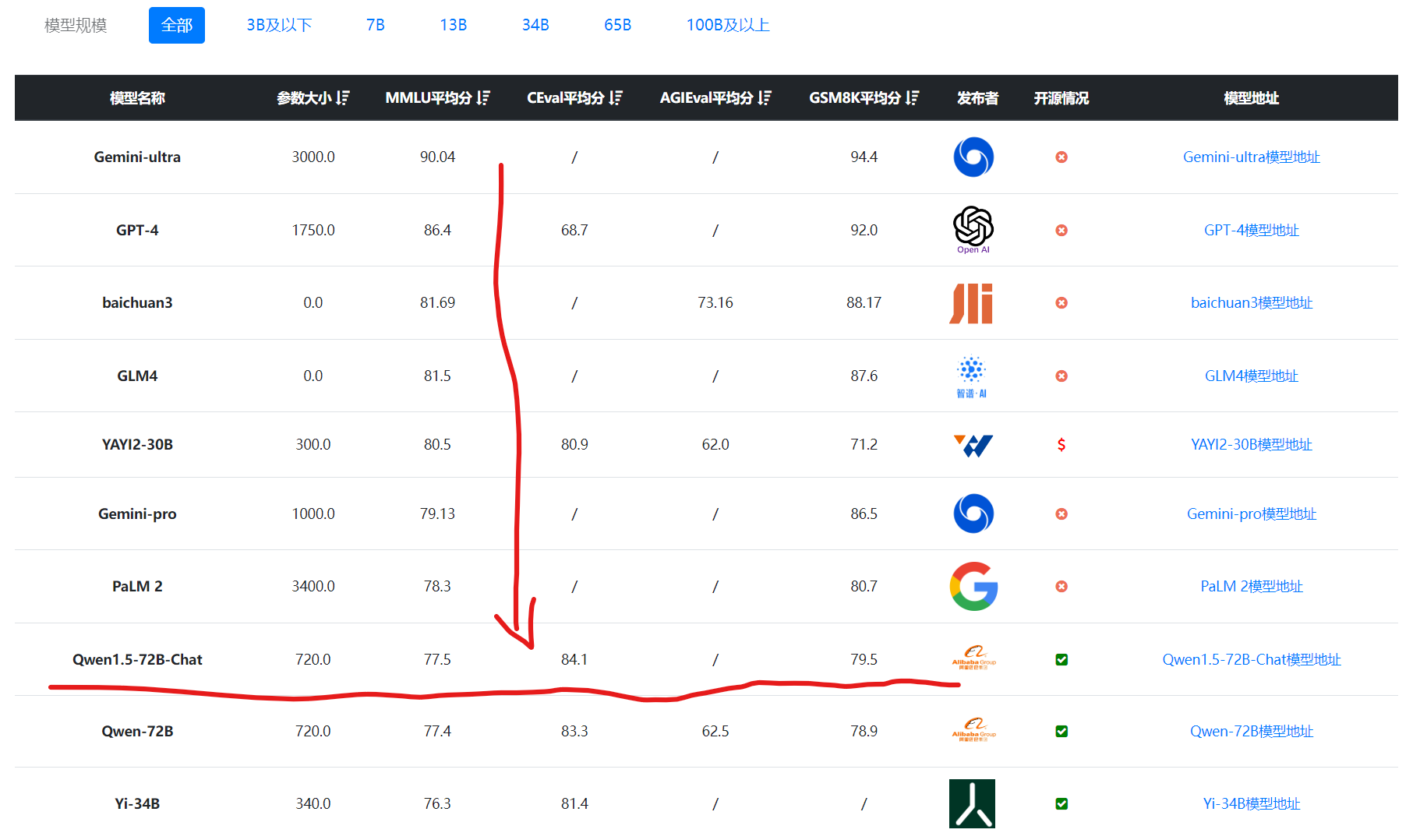
Qwen1.5与第一代Qwen大模型对比
不过,如果我们把Qwen1.5系列模型与第一代相比会发现72B模型的提升并不高,如下表所示:
可以看到Qwen1.5-72B模型只有在HumanEval评分有接近20%的提升,其他方面提升很微弱。
Qwen1.5在小规模参数的评测
官方还公布了小规模版本的模型对比,如下表所示:
这些模型都是40亿以下的模型,除了Qwen1.5-4B外,其它模型多数都在30亿以下。这个结果看,40亿参数规模的Qwen1.5-4B最强,但是它的参数规模也是高了不少。这里也可以看到MiniCPM-2B模型的强大(关于MiniCPM-2B模型介绍参考:https://www.datalearner.com/ai-models/pretrained-models/MiniCPM-2B-SFT )。
Qwen1.5在MT-Bench的得分
除了上述常规的评测外,Qwen1.5最亮眼的是Qwen1.5-72B在MT-Bench的表现。MT-Bench是UC伯克利联合其它研究机构发布的一个大模型指令遵从偏好的评估方法。与前面的评估方法不同的是,前面常规的评估方法大多数是选择题,而这个评估方法则是利用大模型与人类偏好一致的方式,对模型输出的结果仅需对比打分,很多时候更加接近人类的偏好。
|Models|MT-Bench|AlpacaEval 2.0|AlpacaEval 2.0|| |:----|:----|:----| ||Avg. Score|Win Rate|Length| |Qwen1.5-72B-Chat|8.61 (8.67/8.61/8.56)|27.18|1600| |Qwen1.5-14B-Chat|7.91 (7.99/7.99/7.77)|19.7|1608| |Qwen1.5-7B-Chat|7.60 (7.58/7.55/7.66)|13.20|1606|
该得分结果显示Qwen1.5-72B模型的MT-Bench得分8.61,是仅次于GPT-4模型的得分结果。
Qwen1.5大语言模型的实测结果
我们在Qwen1.5-72B模型做了一些测试,结果如下:
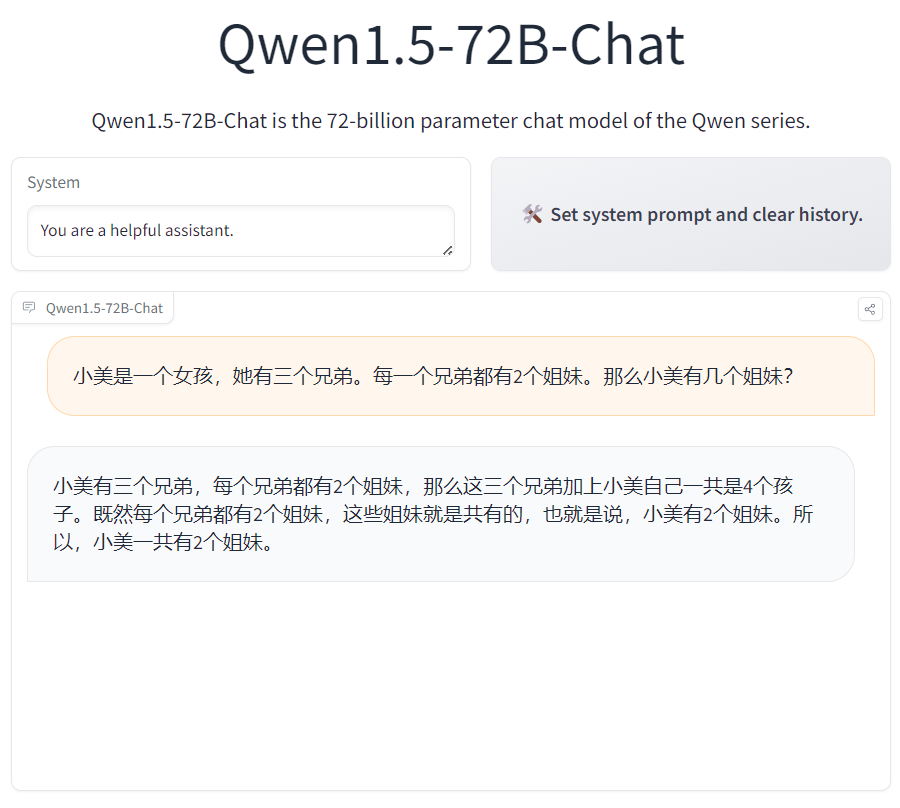
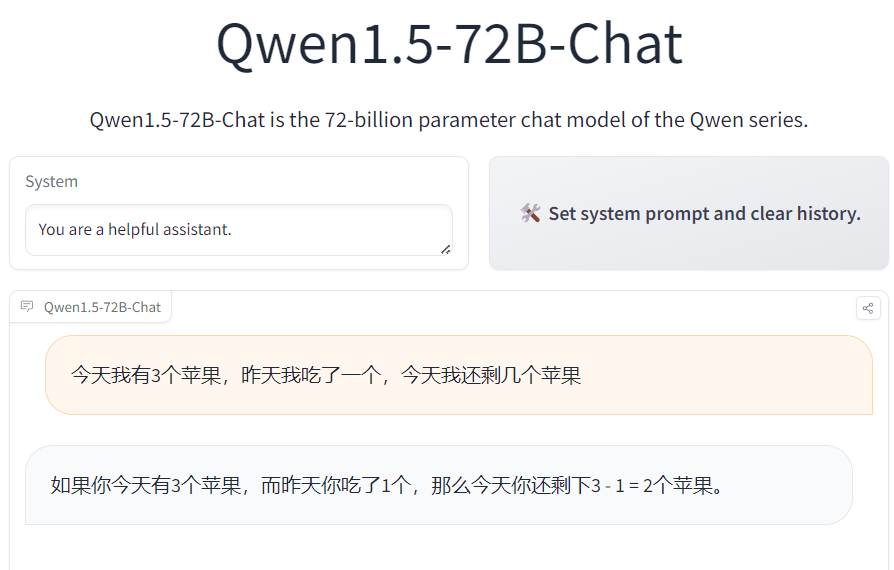
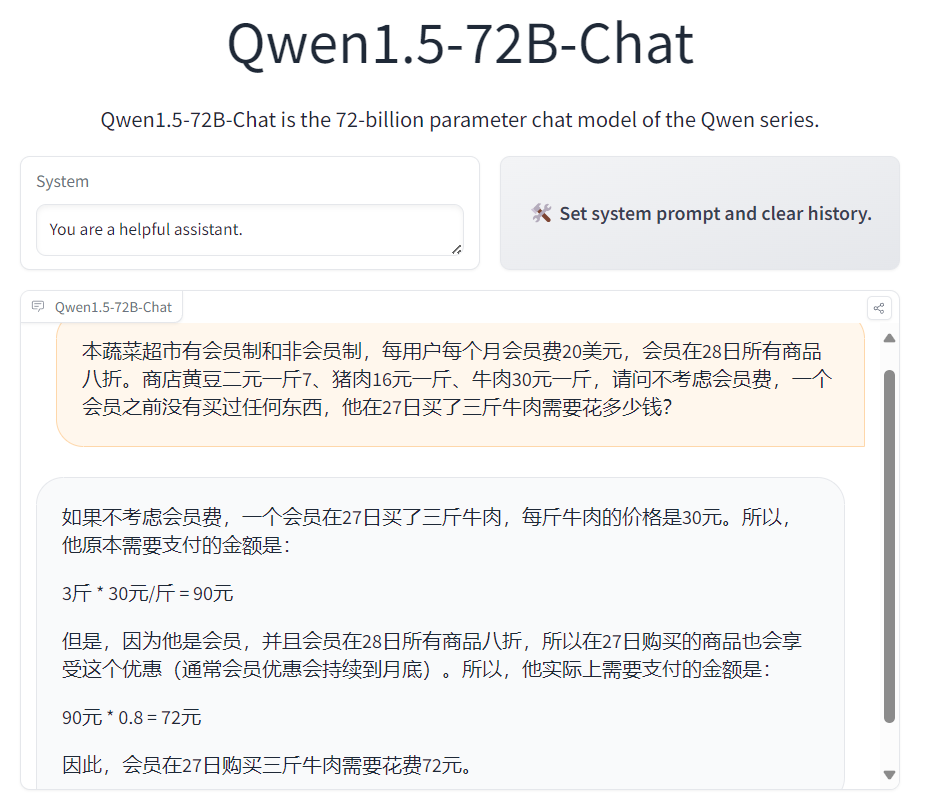
这几个问题回答得实在是有点不太好,不过,这些问题本身也很有难度,GPT-4的回答效果也一般。
下图是一个常规的json提取,效果还可以:

大家目前可以在线测试:https://huggingface.co/spaces/Qwen/Qwen1.5-72B-Chat
Qwen2系列模型开源地址
Qwen2系列模型的是自定义开源协议,如果你的月活不超过1亿,可以直接使用他们的开源模型商用。月活超过1亿则需要申请授权。具体的模型情况和演示地址参考DataLearnerAI模型信息卡:
