
重磅!阿里开源325亿参数规模的推理大模型QwQ-32B:性能接近DeepSeek R1满血版,参数更低,免费商用授权!
就在几个小时前,阿里巴巴开源了最新的一个推理大模型,QwQ-32B,该模型拥有类似o1、DeepSeek R1模型那样的推理能力,但是参数仅325亿,以Apache 2.0开源协议开源,这意味着大家可以完全免费商用。
汇总「通义千问」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
就在几个小时前,阿里巴巴开源了最新的一个推理大模型,QwQ-32B,该模型拥有类似o1、DeepSeek R1模型那样的推理能力,但是参数仅325亿,以Apache 2.0开源协议开源,这意味着大家可以完全免费商用。
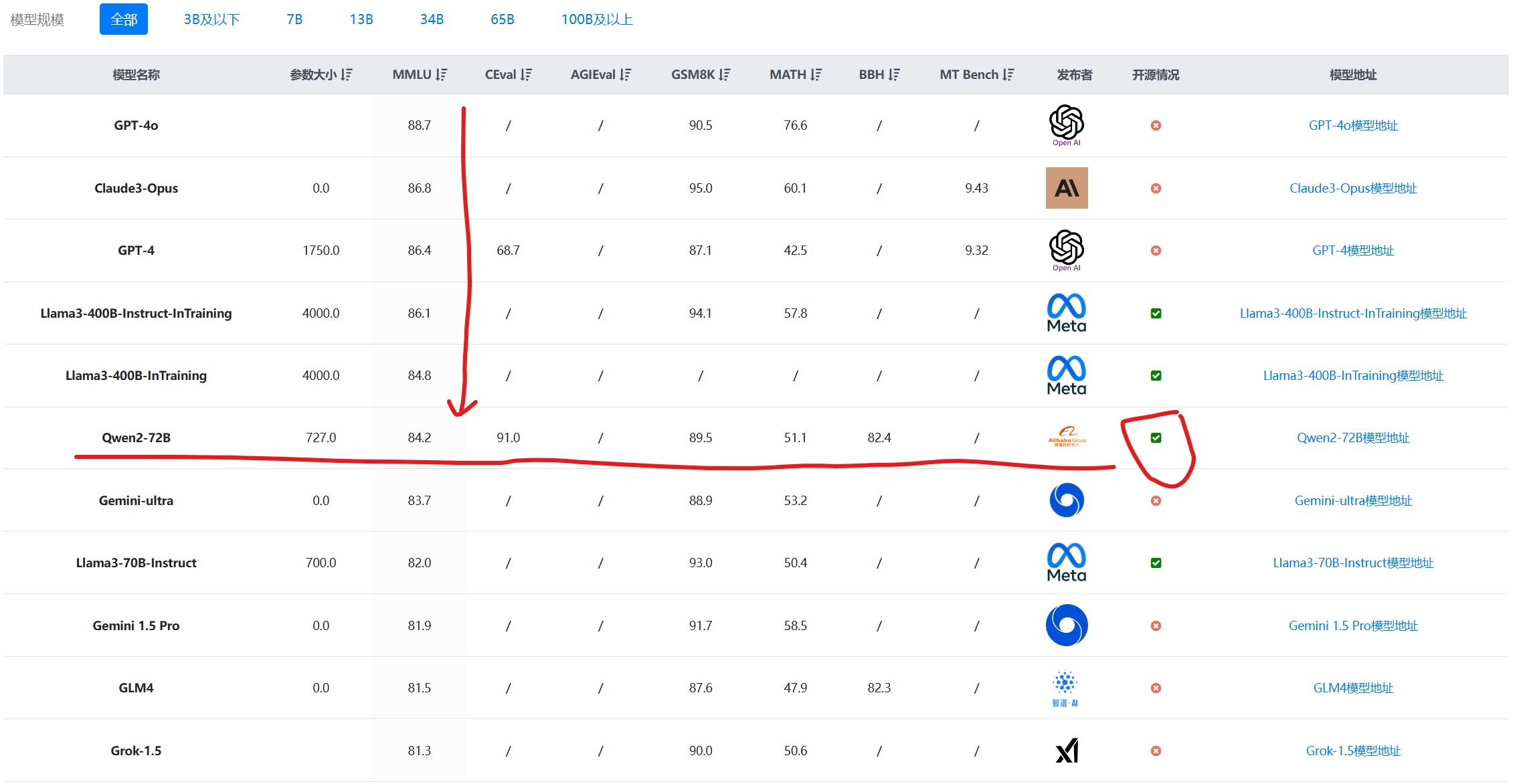
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。
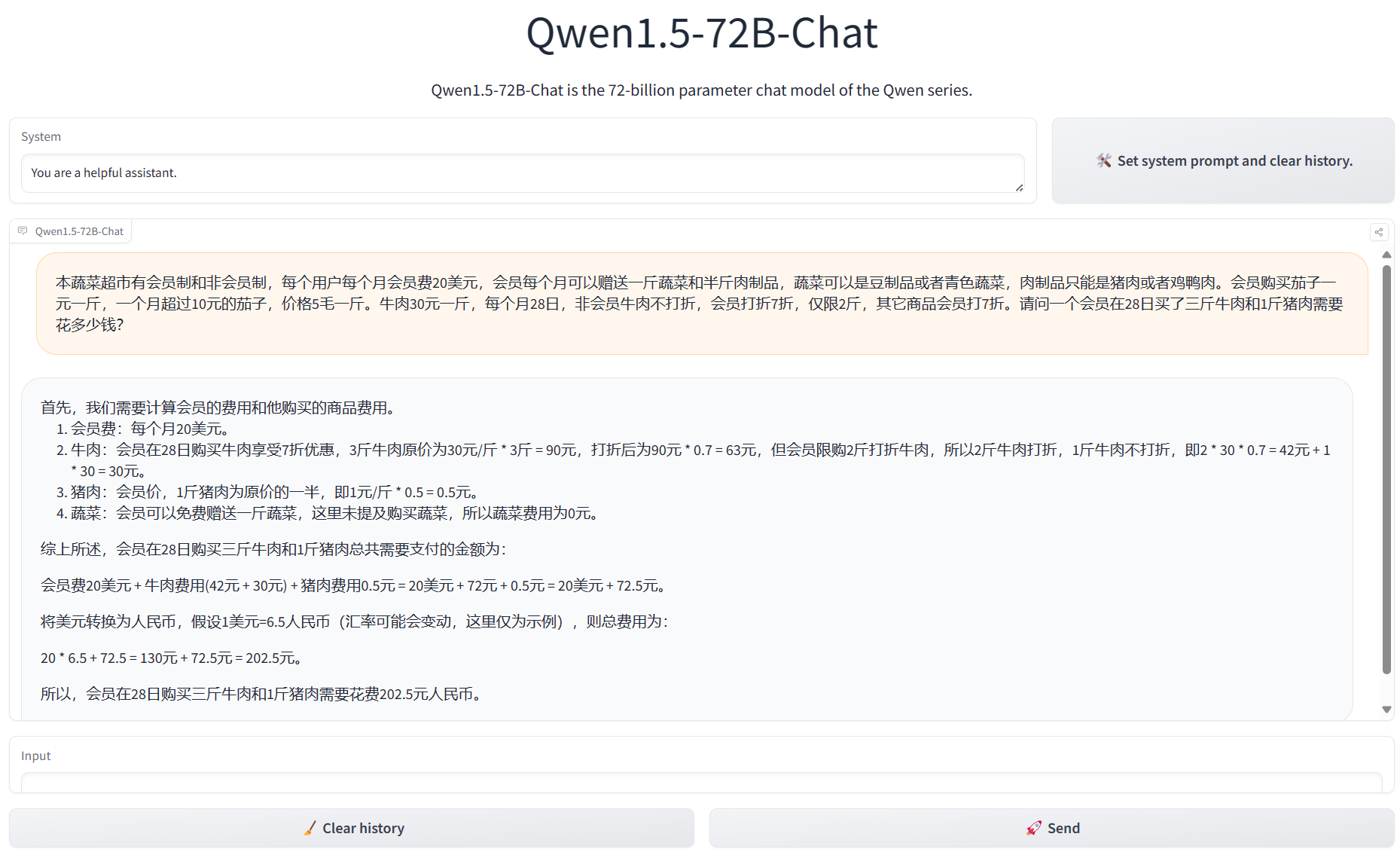
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!
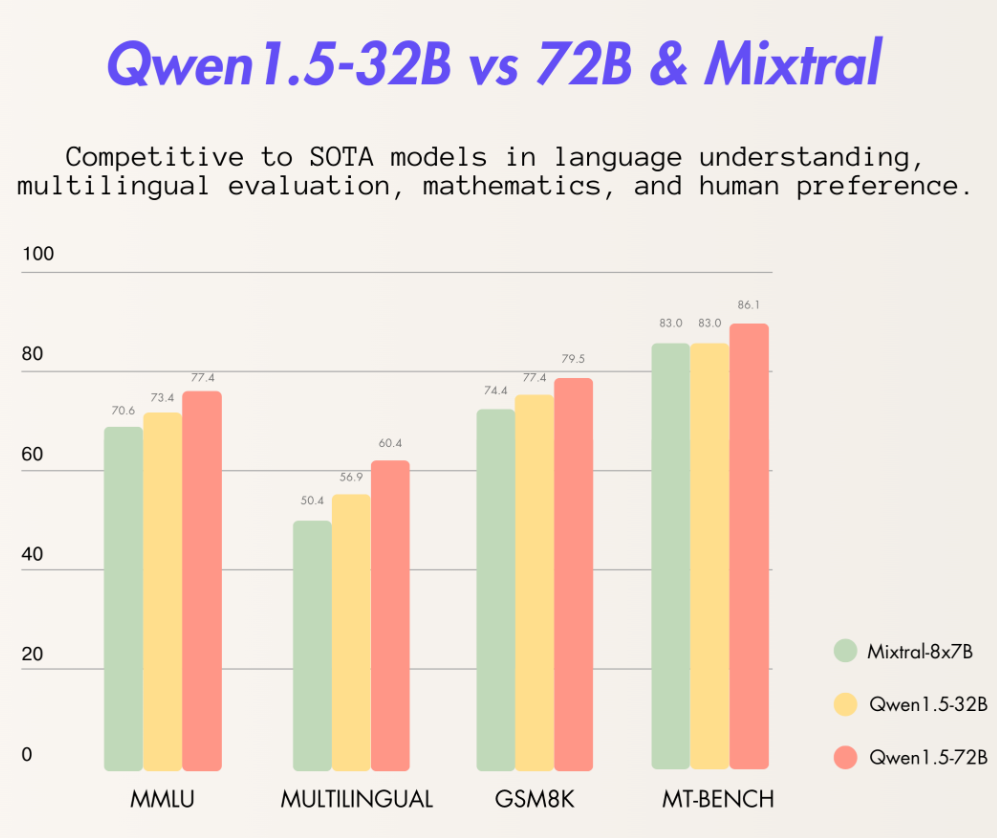
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。
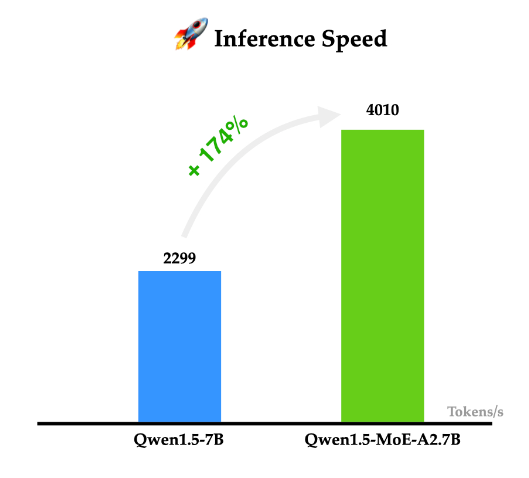
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
今天阿里巴巴开源了他们家第二代的Qwen系列大语言模型(准确说是1.5代),从官方给出的测评结果看,Qwen1.5系列大模型相比较第一代有非常明显的进步,其中720亿参数规模版本的Qwen1.5-72B-Chat在各项评测结果中都非常接近GPT-4的模型,在MT-Bench的得分中甚至超过了此前最为神秘但最接近GPT-4水平的Mistral-Medium模型。
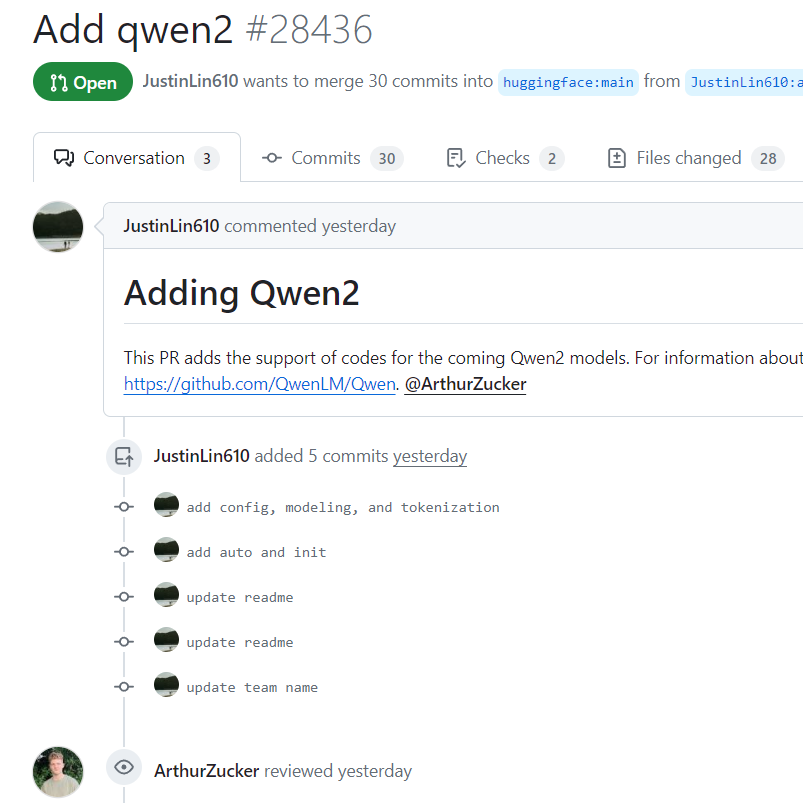
通义千问是阿里巴巴开源的一系列大语言模型。Qwen系列大模型最高参数量720亿,最低18亿,覆盖了非常多的范围,其各项评测效果也非常好。而昨天,Qwen团队的开发人员向HuggingFace的transformers库上提交了一段代码,包含了Qwen2的相关信息,这意味着Qwen2模型即将到来。
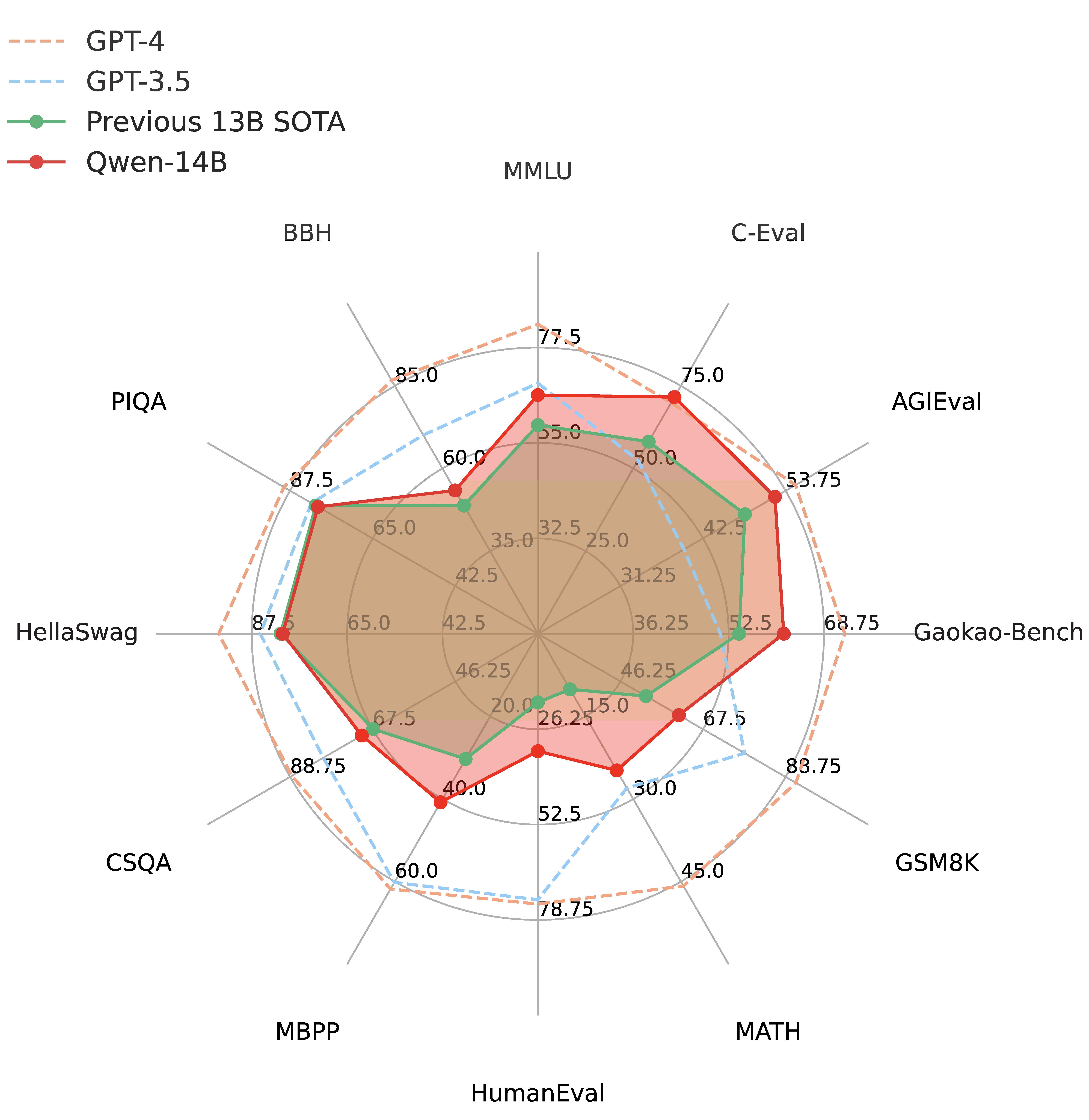
通义千问是阿里巴巴推出的一个大语言模型,此前开源的Qwen-7B引起了广泛的关注,因为他的理解能力很强但是参数规模很小,因此受到了很多人的欢迎。而目前再次开源全新的Qwen-14B的模型,参数规模142亿,但是它的理解能力接近700亿参数规模的LLaMA2-70B,数学推理能力超过GPT-3.5。