
大模型的发展速度很快,对于需要学习部署使用大模型的人来说,显卡是一个必不可少的资源。使用公有云租用显卡对于初学者和技术验证来说成本很划算。DataLearnerAI在此推荐一个国内的合法的按分钟计费的4090显卡公有云服务提供商仙宫云,可以按分钟租用24GB显存的4090显卡公有云实例,非常具有吸引力~



Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!
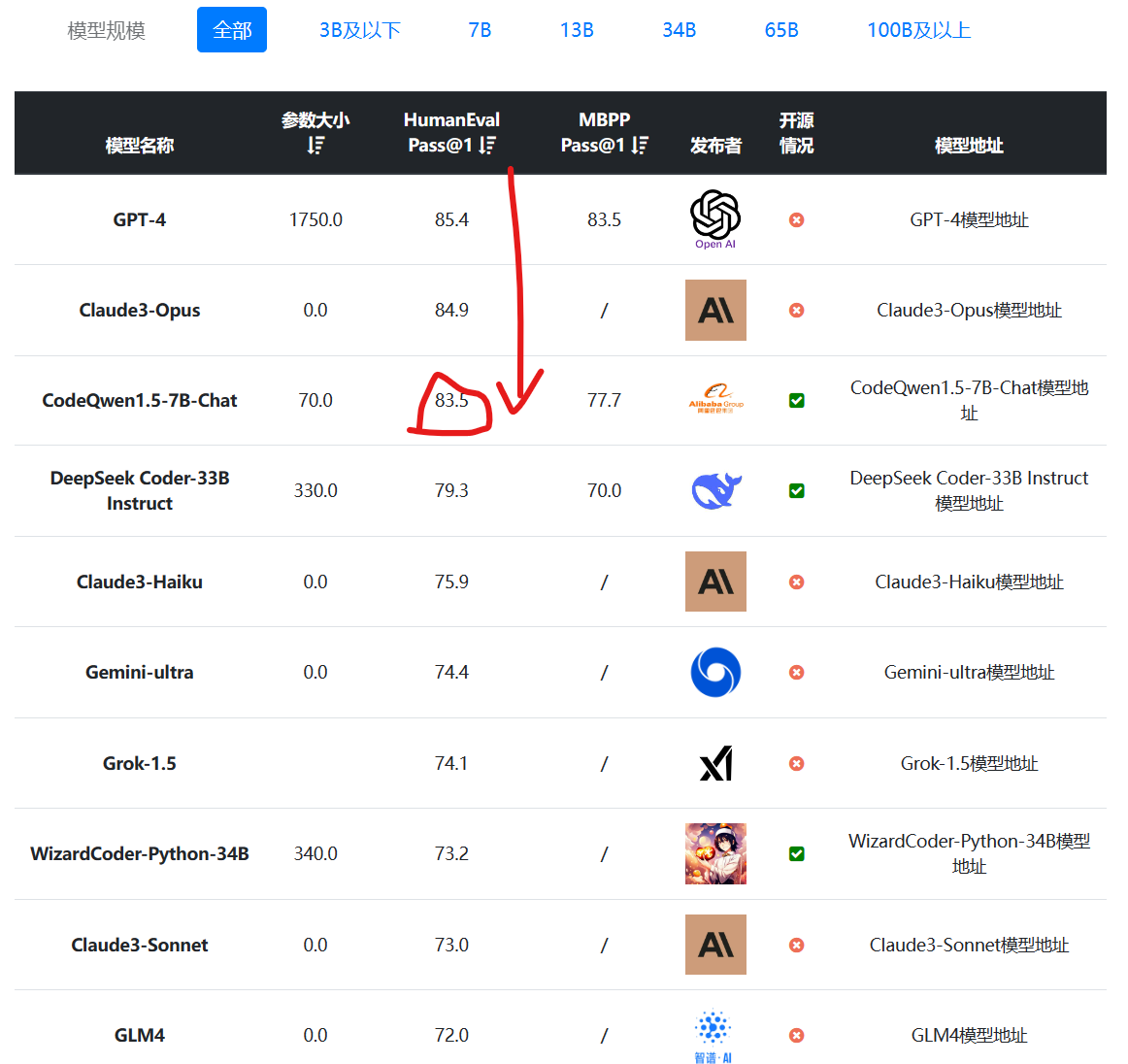
编程大模型是当前大语言模型里面最重要的一类。一般是基础大模型在预训练之后,加入代码数据集继续训练得到。在代码补全、代码生成方面一般强于常规的大语言模型。阿里最新开源的70亿参数大模型CodeQwen1.5-7B在HumanEval评测结果上超过了GPT-4早期版本,表现异常地好!
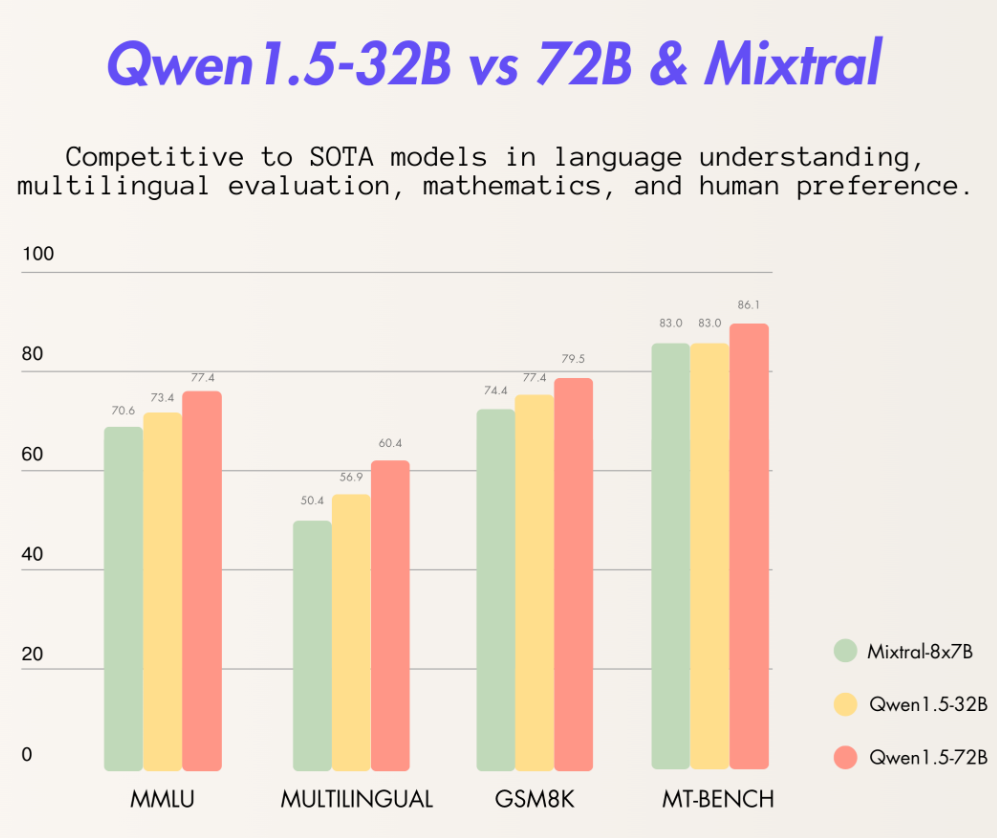
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。
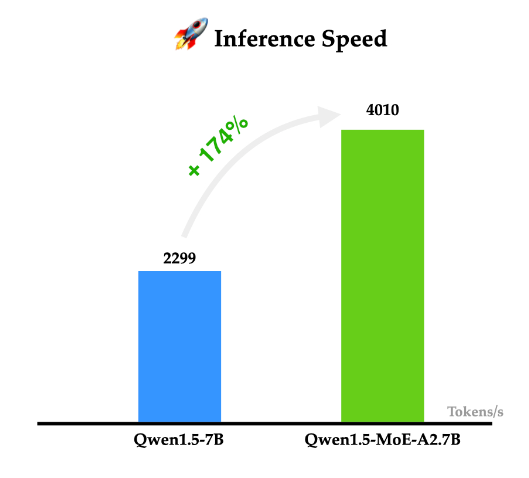
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
今天阿里巴巴开源了他们家第二代的Qwen系列大语言模型(准确说是1.5代),从官方给出的测评结果看,Qwen1.5系列大模型相比较第一代有非常明显的进步,其中720亿参数规模版本的Qwen1.5-72B-Chat在各项评测结果中都非常接近GPT-4的模型,在MT-Bench的得分中甚至超过了此前最为神秘但最接近GPT-4水平的Mistral-Medium模型。
今日推荐
正则化和数据增强对模型的影响并不总是好的:The Effects of Regularization and Data Augmentation are Class Dependent
英伟达在GTC2024大会发布新AI算力芯片:NVIDIA新AI芯片B200的升级是什么?B200与H200对比,它对GPT-4训练和推理的影响是什么?
AI大模型领域的热门技术——Embedding入门介绍以及为什么Embedding在大语言模型中很重要
重磅!阿里开源第三代千问大模型:Qwen3系列,最小仅6亿参数规模,最大2350亿参数规模大模型!可以根据问题难度自动选择是否带思考过程的大模型,评测超DeepSeek-R1和OpenAI o3
Mixtral-8×7B-MoE模型升级新版本,MistralAI开源全球最大混合专家模型Mixtral-8×22B-MoE