Mixtral-8×7B-MoE模型升级新版本,MistralAI开源全球最大混合专家模型Mixtral-8×22B-MoE
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。
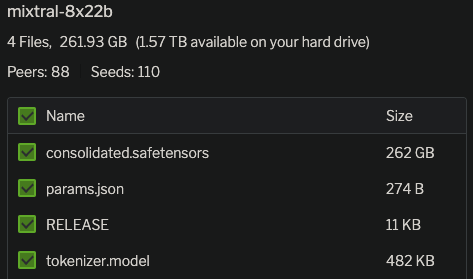
目前该模型依然是以磁力链接让大家下载,没有提供任何新的消息,不过根据磁链文件信息,有几个简单的信息:
- Mixtral-8×22B-MoE依然是8个专家组成的混合专家大模型;
- 每个专家参数规模220亿,是原来70亿参数的3倍,因此总的参数量达到了1760亿!
- 如果依然是每次激活2个专家,这意味着每次推理的参数规模是440亿,比此前120亿参数规模大幅增加,有理由相信模型能力更强!
- Mixtral-8×7B-MoE模型的输入是32K,而这个模型的配置文件显示,上下文输入达到了64K!上下文长度翻倍!
- 根据这个参数估计,Mixtral-8×22B-MoE模型推理半精度的显存需要350GB!成本非常高!但是按照下载链接的物理文件达到262GB的话,应该是不到300G显存即可!
关于Mixtral-8×22B-MoE信息关注DataLearnerAI的模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/Mixtral-8%C3%9722B-MoE
也有网友猜测,目前MistralAI提供的收费模型与开源模型有如下对应关系: Mistral Tiny - Mistral 7B Mistral Small - Mixtral-8×7B-MoE Mistral Medium - Mixtral-8×22B-MoE Mistral Large -?
Mistral Large是MistralAI提供的闭源模型,在各大评测效果都很好。如果按照这个趋势,希望未来能有Mistral Large模型开源!
关于Mixtral-8×22B-MoE其它信息我们保持关注,Mixtral-8×7B-MoE已经是开源领域最强模型之一,那么有理由相信Mixtral-8×22B-MoE应该会达到开源模型的新高度!与当前最强开源模型Command R+相比,希望能有突破,毕竟虽然Command R+虽然不错,但是不可商用。而Mixtral-8×22B-MoE应该是可以免费商用授权的。
关于Mixtral-8×7B-MoE参考:除了Mistral-7B-MoE外,MistralAI还有更强大的模型,未宣布的Mistral-medium比混合专家模型更强!
关于Command R+模型介绍参考:开源模型进展迅猛!最新开源不可商用模型Command R+在大模型匿名投票得分上已经超过GPT-4-Turbo!
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
