重磅!阿里开源第三代千问大模型:Qwen3系列,最小仅6亿参数规模,最大2350亿参数规模大模型!可以根据问题难度自动选择是否带思考过程的大模型,评测超DeepSeek-R1和OpenAI o3
阿里巴巴刚刚开源了第三代千问大模型,Qwen3系列包含了8个不同参数规模的大模型,最大达到2350亿参数规模,最小仅6亿参数规模。本次发布的Qwen3系列是推理大模型和常规的大模型混合版本,即Qwen3可以根据输入问题的情况自动选择是否进行推理。
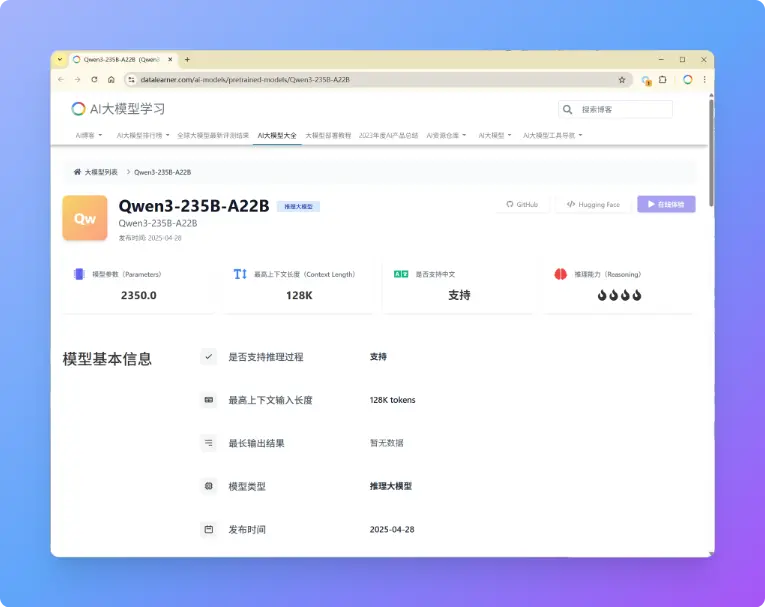
Qwen3系列大模型介绍
本次阿里开源的Qwen3系列大模型共包含8个不同参数规模的大模型,其中有6个是dense(稠密)模型,还有2个混合专家架构(MoE)大模型。
Qwen3系列大模型最大的特点是一个模型支持推理和非推理2种模式进行使用。可以通过enable_thinking参数进行控制(Hugging Face transformers框架)。也就是说,对于数学、编程等需要强逻辑推理的问题来说,我们可以启用思考模式,对于总结摘要等不需要思维链的推理可以使用非推理模式加快推理速度。
此外,Qwen3系列模型在100多种语言上进行了预训练,因此支持全球100+语种,可以说非常强大。
稠密模型最小的是6亿参数的Qwen3-0.6B,非常小巧,量化后0.6G显存即可运行,还有一个1.7亿参数规模的Qwen3-1.7B和4亿参数的Qwen3-4B模型,这三个模型都是可以在移动端运行的,上下文长度32K。
此外,还有Qwen3-8B、Qwen3-14B和Qwen3-32B三个稠密模型,上下文长度是128K,这三个模型都是延续了此前Qwen系列的参数规模。
除了上述6个稠密模型外,本次阿里还开源了2个MoE架构的大模型,分别是总参数规模300亿,每次推理激活30亿的Qwen3-30B-A3B以及总参数规模2350亿,每次推理激活220亿的Qwen3-235B-A22B模型,后者是本次开源的Qwen3系列大模型中参数规模最大的一个,其表现也非常不错,各项评测也超过了OpenAI-o1以及DeepSeek-R1等全球最强模型。
Qwen3系列大模型的评测结果
Qwen3系列改进了模型架构、增加了训练数据集,各方面的改进使得该系列的模型相比较此前的Qwen2.5系列模型都有了大幅的能力提升。其中,最大参数规模的Qwen3-235B-A22B模型在不同评测数据集上的表现甚至超过了OpenAI-o1、DeepSeek-R1、Grok-3系列。

从上图可以看到,Qwen3-235B-A22B在编程(LiveCodeBench)上的得分达到70.7分,甚至超过了Gemini2.5-Pro模型,也是远超OpenAI的o1和DeepSeek-R1,而在数学竞赛方面(AIME)表现也很不错,大幅领先对手(除了Gemini2.5-Pro这个变态)。
而根据DataLearnerAI搜集的大模型评测数据来看,LiveCodeBench评测上,Qwen3-235B-A32B是目前开源大模型中得分最高的:
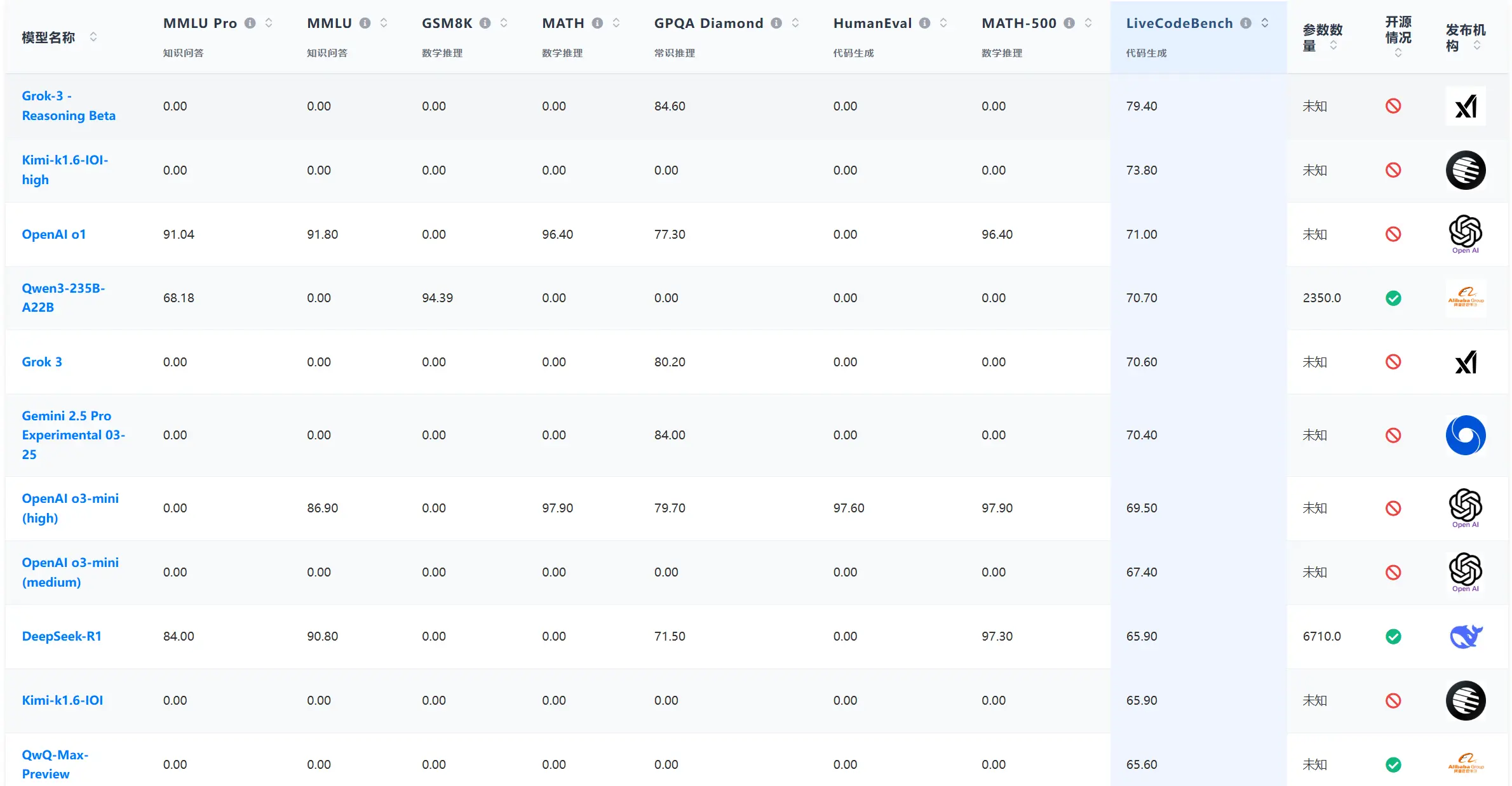
可以看到,Qwen3-235B-A22B模型的编程水平很好,不过MMLU-Pro评分就很一般了。
Qwen3的训练细节和开源情况
Qwen3系列模型的架构和训练都有了比较大的变化。首先是Qwen3的预训练阶段的数据集规模就比Qwen2.5系列增加了一倍。Qwen2.5系列模型的预训练tokens数是18万亿,而Qwen3系列则在36万亿tokens上预训练。除了网上的公开文本数据集,阿里还使用Qwen2.5-VL提取了大量的PDF格式数据,同时用Qwen2.5-Math和Qwen2.5-Coder合成了许多数学和编程数据集,来增加Qwen3预训练数据。
预训练阶段,Qwen3先是在4K上下文上预训练30万亿数据,获得基本的能力,然后引入了5万亿高质量数学、编程数据集,增强模型的STEM能力,最后在32K高质量的长上下文数据集上做了预训练,获得了最终的效果。同时为了获得模型的思考能力,Qwen3也做了思维链数据预训练以及基于推理的强化学习过程。
更为重要的是,Qwen3全系列都是Apache2.0协议开源,完全免费商用。在此前的版本中,手机端运行较小的Qwen系列以及最大的Qwen2.5-72B系列都不是完全免费开源的,有一些商用限制,此次完全解除,真是开源榜样!
关于Qwen3系列的其它信息,参考DataLearnerAI的模型信息卡(内包含代码示例以及开源地址) Qwen3-0.6B:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-0_6B Qwen3-1.7B:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-1_7B Qwen3-4B:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-4B Qwen3-8B:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-8B Qwen3-14B:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-14B Qwen3-30B-A3B:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-30B-A3B Qwen3-235B:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-235B
