阿里开源全新编程大模型Qwen3-Coder-480B-A35B,官方宣称其编程水平接近Claude Sonnet 4,免费开源可商用,同时开源Claude Code免费平替选择Qwen Code
阿里宣布开源第三代编程大模型Qwen3-Coder-480B-A35B,该模型是Qwen3编程大模型中第一个开源的版本,同时官方还基于Google的Gemini CLI改造并开源了阿里自己的命令行编程工具Qwen Code,完全免费使用。

Qwen3-Coder-480B-A35B介绍及其特点
阿里宣称本次开源的Qwen3-Coder-480B-A35B模型是一个Agentic Code模型,也就是说不单纯的是认为用来生成代码的,而是支持工具调用的编程Agent模型。
本次开源的Qwen3-Coder-480B-A35B是一个混合专家架构(MoE)模型,其总参数4800亿,每次推理激活350亿参数。而且是一个由很多数量的小专家组成的模型,共160个专家,每次推理激活其中的8个。
Qwen3-Coder-480B-A35B原生支持256K上下文输入,利用YaRN技术可以扩展到最高100万,这样长度的上下文非常适合用力对整个代码仓级别的内容进行理解,大大拓展了模型的实际应用价值。
不过,需要注意的是,首先Qwen3-Coder-480B-A35B的语言基座模型在此前的Qwen3的开源中并没发现,且该模型仅支持非推理模式(non-thinking)。即其输出不生成<think></think>块。因此,在使用时不再需要明确指定enable_thinking=False。
Qwen3-Coder-480B-A35B评测结果与Claude Sonnet 4相当
阿里官方对于该模型十分自信,认为这是开源模型中顶尖的一类,特别是在Agentic Coding, Agentic Browser-Use, 和Agentic Tool-Use方面,水平与Claude Sonnet 4相当。也就说,这个模型是为Agentic编程而生。
以SWE-Bench Verified为例(OpenAI基于公开的SWE-Bench人工选择的一个来自GitHub真实项目案例的评测基准),Qwen3-Coder-480B-A35B获得了67.0%的得分,如果允许Qwen3-Coder-480B-A35B对话到500次,它的准确性可以达到69.6%。
下图展示了SWE-Bench Verified模型在SWE-Bench Verified排名情况:
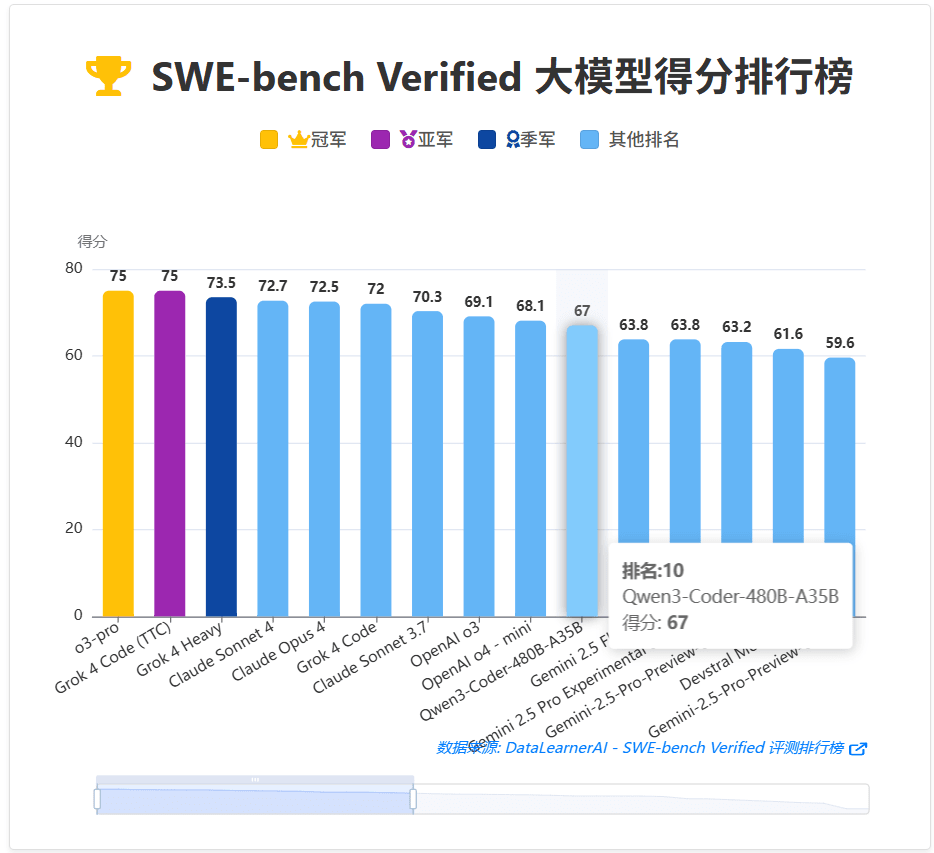
可以看到,尽管Qwen3-Coder-480B-A35B排名第十,但是这已经是开源模型中的第一,前面的模型都是OpenAI、Claude和Grok模型,且都是当前全球最强的模型,同时都是带推理模式的大模型,此外,还有使用外部工具或者增加推理时长得到。
即使单看67分的结果,与OpenAI o3的分数差距也不大。
以下表格展示了不同模型在Agentic编程、浏览器使用和工具使用方面的基准测试结果。
Agentic Coding
Agentic Browser Use
Agentic Tool Use
Claude Code平替:阿里开源Qwen Code
随着Anthropic发布Claude Code,越来越多的人发现使用命令行对整个代码仓进行自然语言交互式的编程很方便很强大。它可以无需关注单个文件,只需要输入你的需求,就能让模型理解代码仓的基础上进行跨文件的编程。
但是Claude Code是闭源的,需要月付费至少100美元才能比较好的体验使用。Google虽然发布了的Gemini CLI,但是目前国内以及体验方面还是较弱。本次阿里也是顺应趋势,fork了Gemini CLI项目,然后改造成可以直接对接Qwen3-Coder模型的命令行Agentic编程工具。
Qwen Code开源地址:https://github.com/QwenLM/qwen-code
这意味着,如果你可以本地化部署一个Qwen3-Coder-480B-A35B,那么你可以无限制免费使用Agentic编程了。不过这个成本也不低,即使使用FP8量化版本,也需要500GB+显存才体验好。不过不用担心,Qwen团队官方说Qwen3-Coder是一个系列,会有更小的版本发布!
同时,Qwen团队也在积极适配 Claude Code、提供 Cline 插件等,可以说在生态集成方面是要促进Qwen3-Coder的加速落地。
Qwen3-Coder开源情况和其它信息
Qwen系列一直在业界有很好的口碑,而Qwen Coder一直也是很多人的期待。阿里官方明确提到“Coding Agent 能否自我改进”是下一阶段方向,本次开源的Qwen3-Coder-480B-A35B也显示了结合长程 RL 和可执行反馈,模型自己写测试、修 bug、迭代自身代码的路径已经铺好,只差工程化闭环。
阿里直接把Claude Sonnet 4当对标物,且认为差距已很小。在公开基准(Agentic Coding / Browser-Use / Tool-Use / SWE-Bench Verified)拿到“开源第一、逼近 Claude Sonnet 4”的成绩。即将出现可以平替闭源顶尖模型的AgenticCode模型以及工具!
更多Qwen3-Coder-480B-A35B信息和开源地址参考DataLearnerAI的模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/Qwen3-Coder-480B-A35B-Instruct
