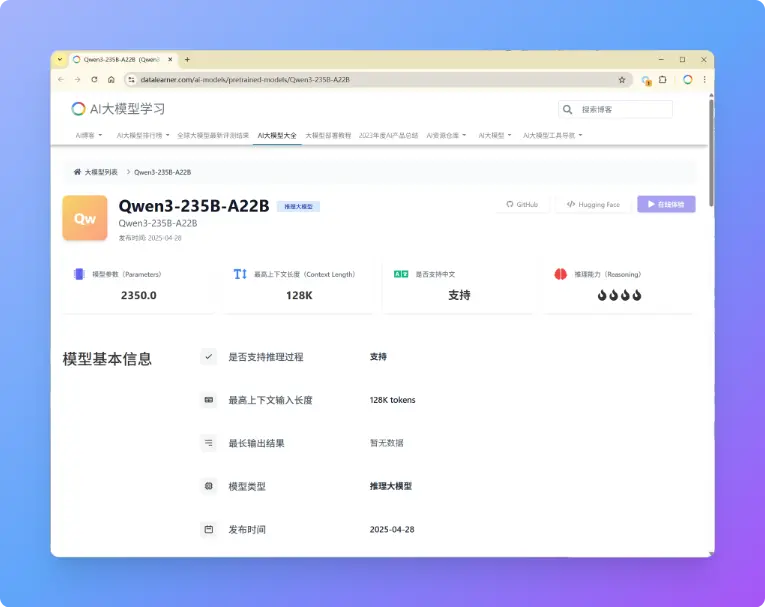
重磅!阿里开源第三代千问大模型:Qwen3系列,最小仅6亿参数规模,最大2350亿参数规模大模型!可以根据问题难度自动选择是否带思考过程的大模型,评测超DeepSeek-R1和OpenAI o3
阿里巴巴刚刚开源了第三代千问大模型,Qwen3系列包含了8个不同参数规模的大模型,最大达到2350亿参数规模,最小仅6亿参数规模。本次发布的Qwen3系列是推理大模型和常规的大模型混合版本,即Qwen3可以根据输入问题的情况自动选择是否进行推理。
汇总「阿里巴巴」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
阿里巴巴刚刚开源了第三代千问大模型,Qwen3系列包含了8个不同参数规模的大模型,最大达到2350亿参数规模,最小仅6亿参数规模。本次发布的Qwen3系列是推理大模型和常规的大模型混合版本,即Qwen3可以根据输入问题的情况自动选择是否进行推理。
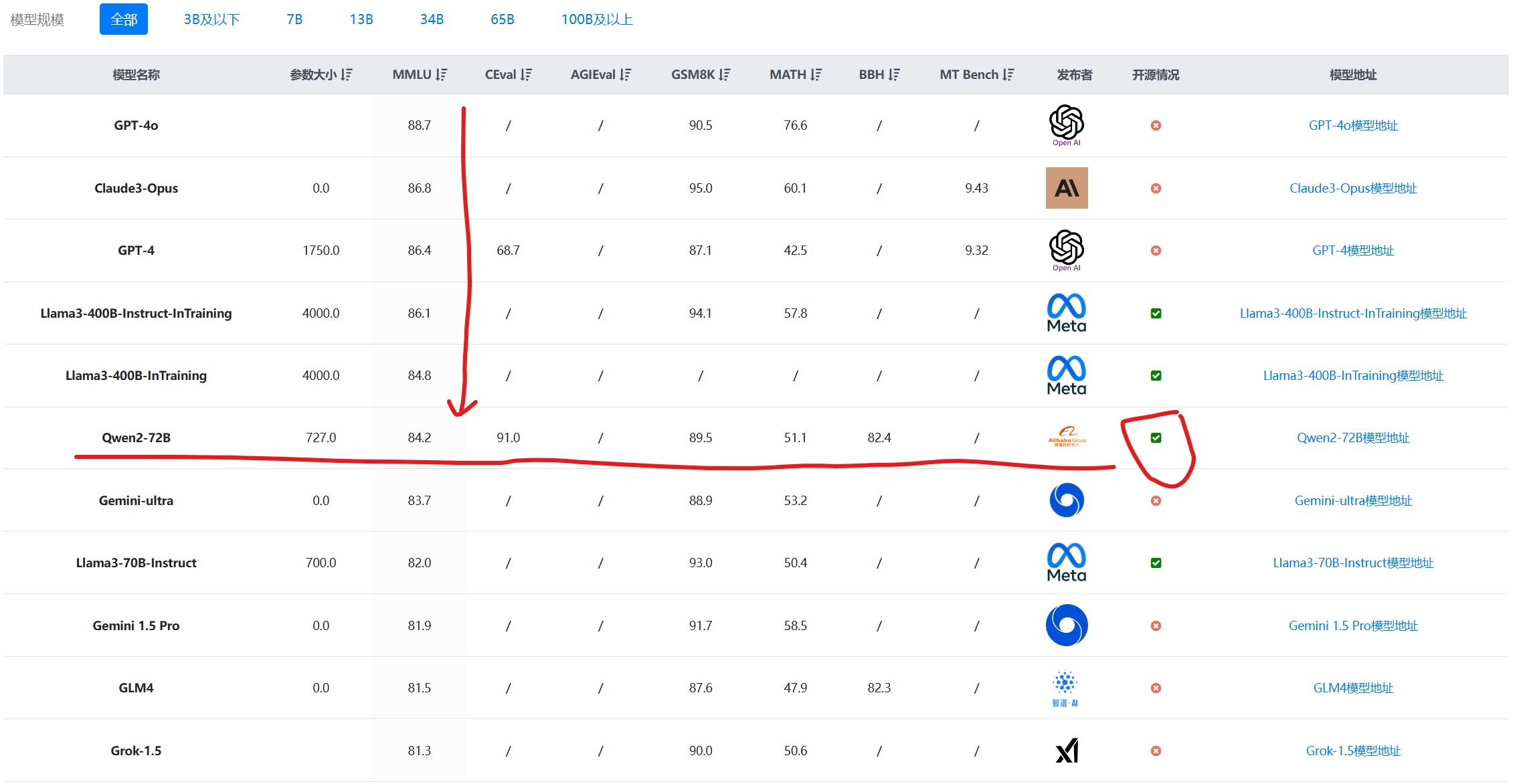
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。
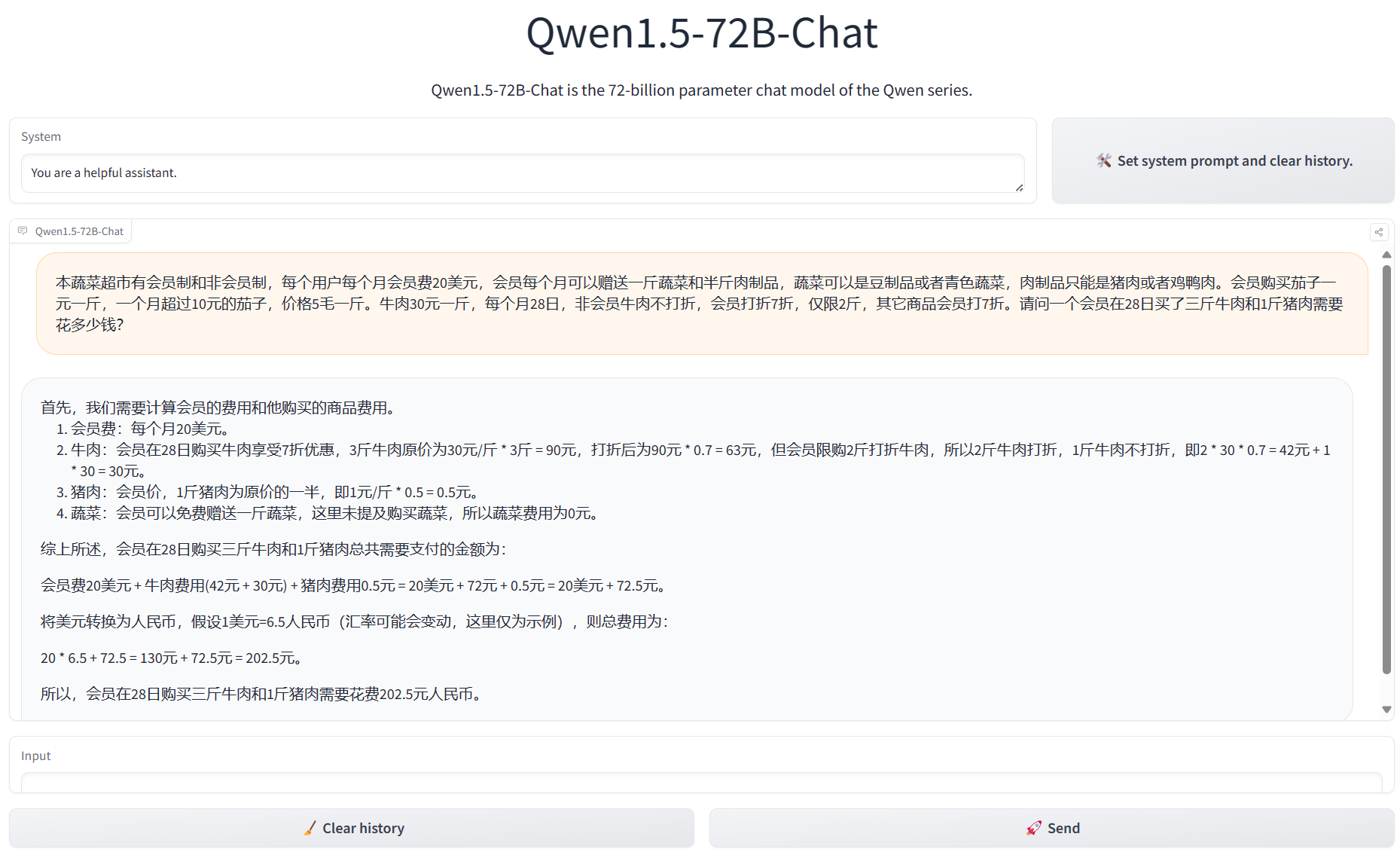
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!
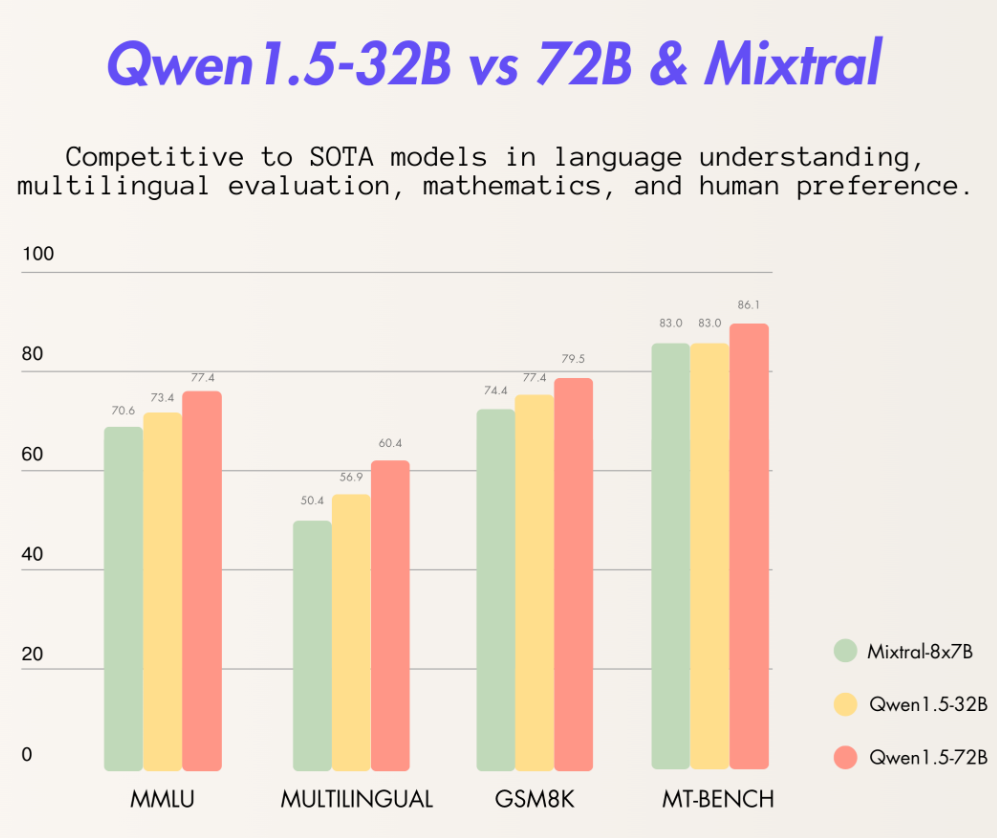
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。

Qwen系列是阿里巴巴开源的一系列大语言模型。在此前的开源中,阿里巴巴共开源了3个系列的大模型,分别是70亿参数规模和140亿参数规模的Qwen-7B和Qwen-14B,还有一个是多模态大模型Qwen-VL。而此次阿里巴巴开源了720亿参数规模的Qwen-72b,是目前国内最大参数规模的开源大语言模型,应该也是全球范围内首次有和Llama2-70b同等规模的大语言模型开源。