阿里巴巴开源第二代大语言模型Qwen2系列,最高参数规模700亿,评测结果位列开源模型第一,超过了Meta开源的Llama3-70B!
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。
Qwen2.0系列模型简介
此次开源的Qwen2系列模型包含了5个不同参数规模版本的模型,最小的模型仅5亿参数规模,最大的模型参数规模720亿,还包括一个基于混合专家技术(MoE)的大模型,Qwen2-57B-A14B。
Qwen2系列模型的数据集包含了27种语言,主要的是中文和英文。除了基础能力的提升外,Qwen2系列模型在编程、数学推理方面提升页非常明显。其中GSM8K、Math的数学评测结果均是开源模型第一。此外,Qwen2系列大模型的上下文长度也拓展到了128K!
其中,Qwen2-57B-A14B是MoE架构的大模型,参数总规模574.1亿,每次推理激活140亿的参数。
Qwen2.0系列模型在不同评测任务上都是开源的最强的模型
Qwen2-72B是此次阿里开源的模型中参数规模最高的一个,达到了720亿参数的规模。而这个模型也是当前开源模型中评价最高的一个。不管是在不同的评测基准上还是在实际测试中都是如此。
在MMLU的综合理解上,Qwen2-72B的得分达到了84.2分,超过了Llama3-70B的79.5分。这个得分超过了Gemini-Ultra,接近GPT-4的86.4分。非常接近此前Meta披露的正在训练过程中的Llama3-400B,不过,这个模型目前还没公布,不确定是否开源,参数规模也是远超Qwen2-72B。
除去不确定的Llama3-400B模型,Qwen2-72B在数学推理等方面也是目前最好的开源模型。其中GSM8K得分89.5分,MATH评测结果51.1分,超过了马斯克的Grok1.5,接近Google的Gemini Ultra。
下图是DataLearnerAI收集的主流大模型评测结果展示,按照MMLU排序的结果:
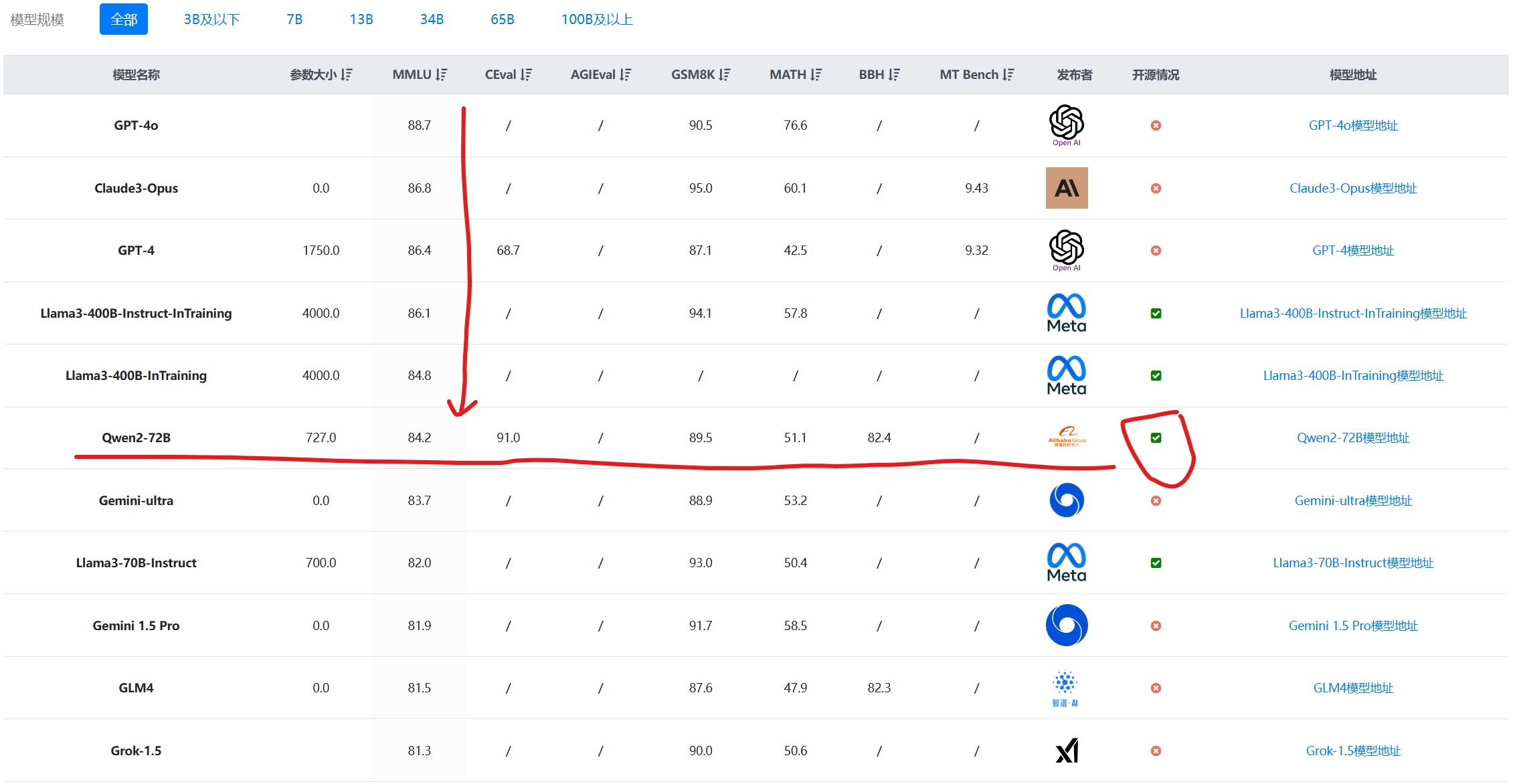
毫无疑问,除了Llama3系列,Qwen2-72B是唯一可以在一众闭源模型中获得很好结果的开源模型。这个结果也超过了此前1100亿参数的Qwen1.5-110B模型。
在数学推理和编程方面,官方也给出了Qwen2-72B和Llama3-70B的对比结果,也是完全超越了Llama3模型:

从上图中可以看到,Qwen2-72B在所有的编程语言的评测结果中都超过了Llama3-70B,而数学考试方面亦是如此。
Qwen2-72B的实测结果
目前市场的评测在很多方面不能完全代表模型的实际结果。为了提供一些新的评测视角,DataLearnerAI也做了一些测试,用了一些复杂的例子测试。
第一个逻辑推理,问题很简单,但是对大模型来说不那么容易,即“小美是一个女孩,她有三个兄弟。每一个兄弟都有2个姐妹。那么小美有几个姐妹?”
这个问题很简单,就是小美和另一个女孩两个姐妹(可以说小美有一个姐妹)。我们测过文心一言3.5,答案是错的,但是Qwen2-72B、GPT-4,结果都是对的。
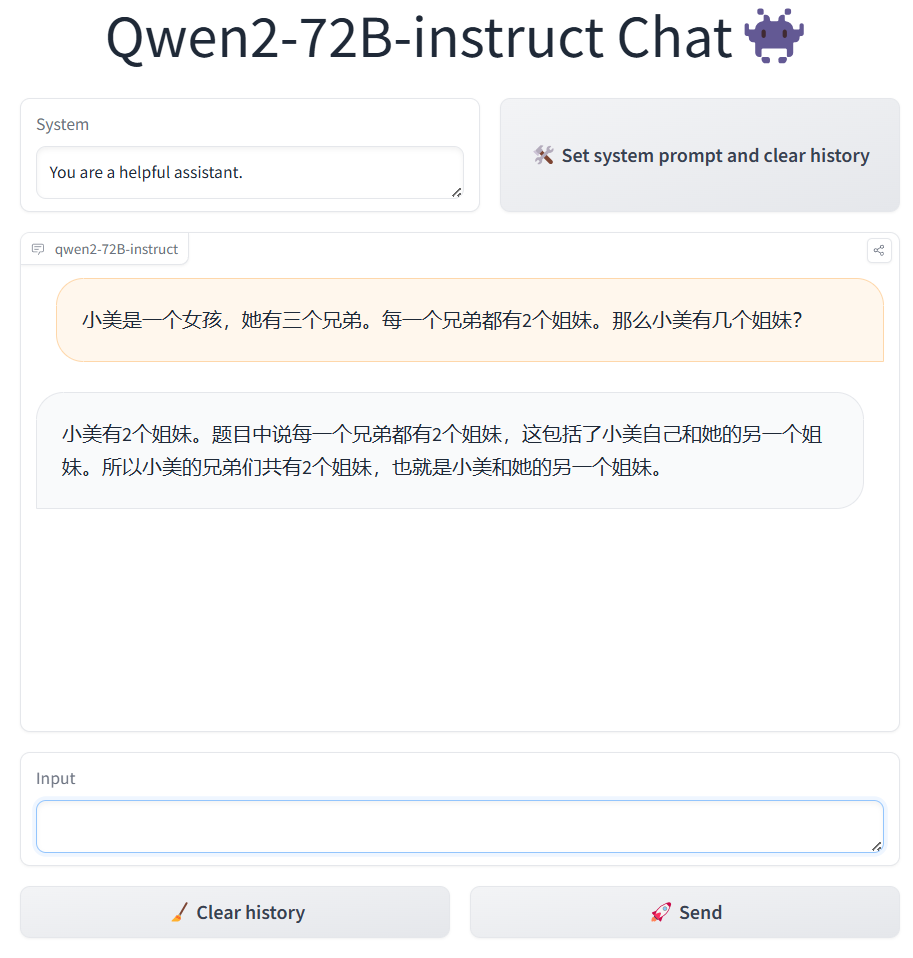
文心一言3.5回答是0个。
另一个问题是复杂的信息提取:即根据用户的输入提取复杂的json结果。

可以看到,Qwen2的结果完全正确。这个例子在文心一言的3.5测试结果中非常差。而GPT-4o的结果则有一些幻觉,在租费中提取了一些额外的并不必要的结果。
从上面两个简单的案例中可以看到,Qwen2-72B在复杂任务的处理上效果非常不错。
Qwen2开源和生态
Qwen系列模型一直是开源领域非常友好的模型。在上个月,阿里也官方宣布Qwen系列模型的开源协议转向了Apache2.0协议,这意味着可以更加友好的商用。
而此次开源的Qwen2系列模型中,值得注意的是除了Qwen2-72B模型外,均是Apache2.0开源协议,但是Qwen2-72B模型的开源协议则是《Tongyi Qianwen LICENSE AGREEMENT》。这个协议虽然允许商用,但是如果你的产品或服务有超过1亿月活跃用户,则需要申请商用授权,而这个授权需要阿里方面明确的授权协议,是否收费可能要谈谈看。
Qwen系列模型除了效果很好外,生态建设方面也非常厉害,在全球主流的开源推理框架和大模型生态中,Qwen2都做了适配和兼容。

关于Qwen2系列模型的开源地址和其它详情可以参考DataLearner的模型信息卡:
