大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处!
大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。

这篇论文名字是Lost in the Middle: How Language Models Use Long Contexts,本文介绍其核心观点。
当前大模型处理长输入的水平依然不够
在大语言模型(Large Language Model,LLM)中,"上下文长度"是指大语言模型在生成预测时考虑的输入文本的长度。上下文长度对于语言模型的性能有着重要的影响。一般来说,更长的上下文长度可以让模型看到更多的信息,从而做出更准确的预测。
然而,处理更长的上下文也需要更多的计算资源,这可能会限制模型的实用性。而且,在实际应用中,大多数模型在处理长输入的时候都发生了性能显著下降的情况。
例如,在上周的LM-SYS公布的长输入评测中,各个开源模型都遭遇了非常严重的问题(参考:支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3)。
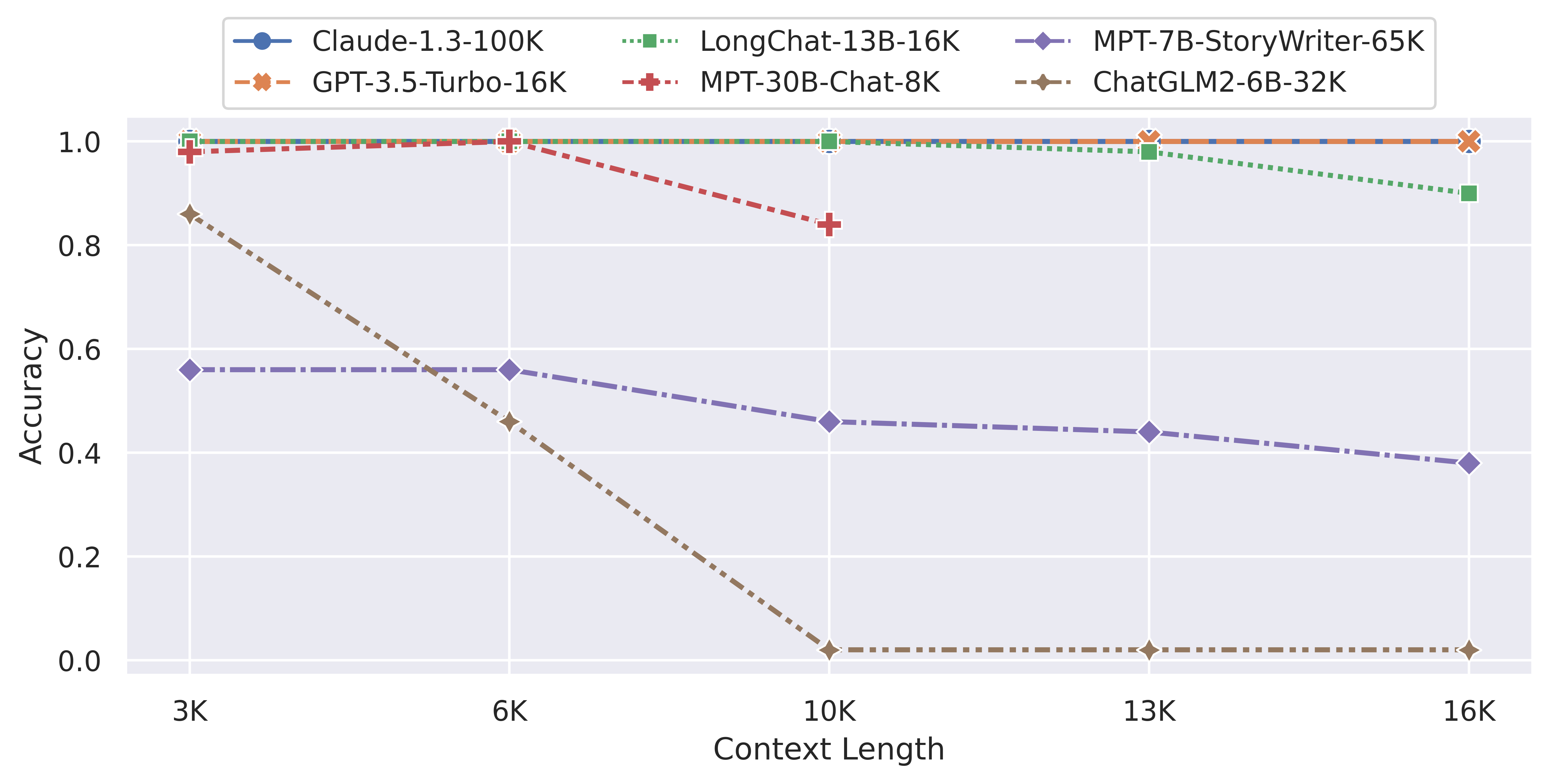
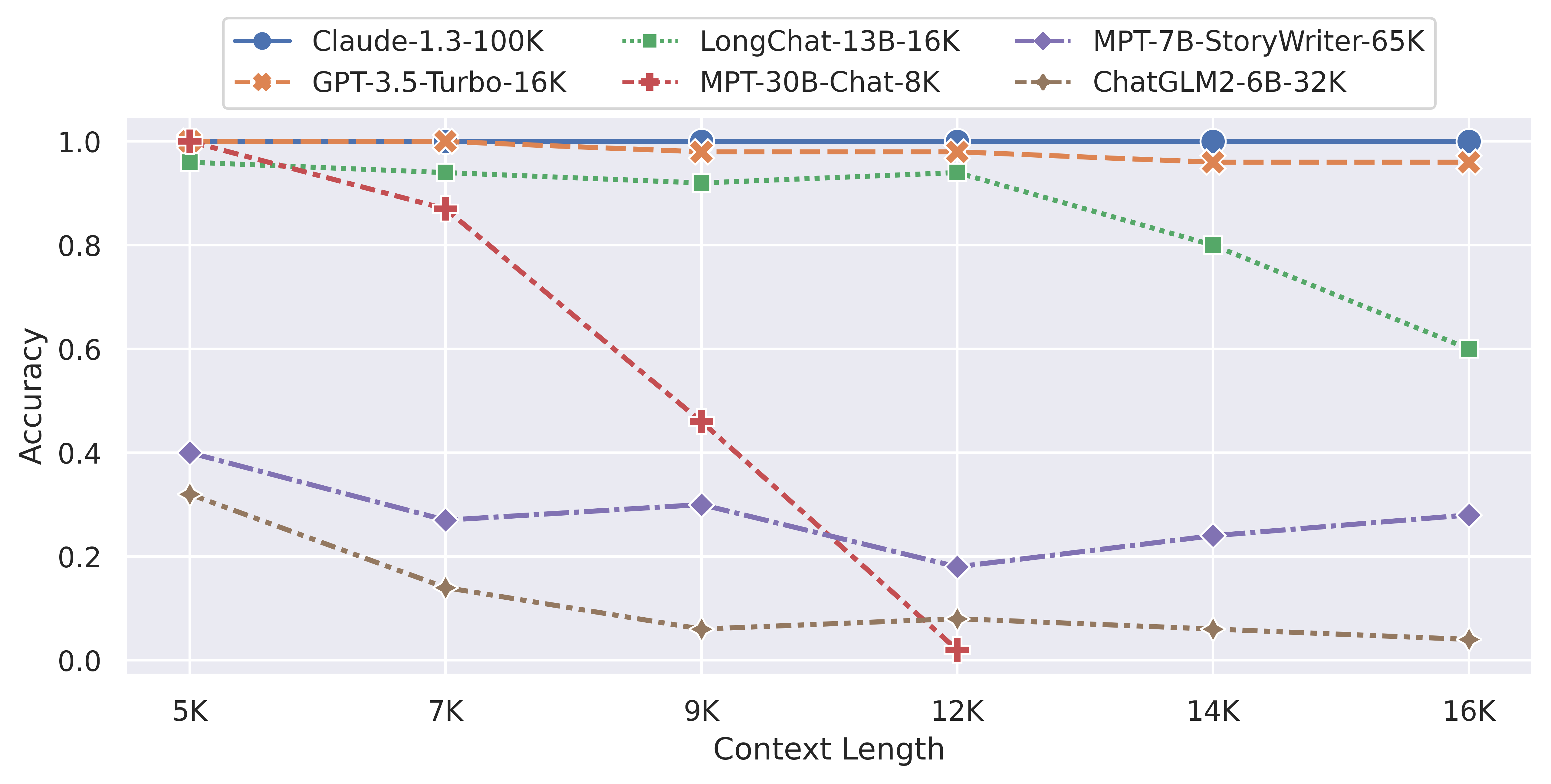
非常直观且残酷,2个商业大语言模型GPT-3.5-Turbo-16K与Claude-1.3-100K在超长上下文评测任务中表现十分稳定,完胜所有开源模型。
尽管各大企业和组织都在为大模型支撑更长输入努力,但关于这些模型如何有效利用长上下文的知识相对较少。通过分析大语言模型在需要从输入内容中识别相关信息的任务上的表现,可以揭示大模型在处理长上下文时的优势和局限。
大模型如何处理长输入?
大语言模型通常使用Transformer实现,但对于长序列的处理效果较差(例如,自注意力的复杂度与输入序列长度呈二次关系)。因此,大语言模型通常在相对较小的上下文窗口中进行训练。
最近硬件的改进使得语言模型具有更大的上下文窗口,但如何在执行下游任务时使用这些扩展上下文的方式仍不清楚。
为此,作者设计了2个实验来研究大模型如何使用上下文信息。这两种任务都需要模型识别输入上下文中的相关信息。
-
多文档问题回答(Multi-Document Question Answering,MDQA):在这个任务中,模型需要从多个文档中找到问题的答案。这个任务被设计成需要模型理解和记住长上下文中的信息。
-
键值检索(Key-Value Retrieval,KVR):在这个任务中,模型需要从一系列键值对中找到与给定问题相关的值。这个任务被设计成需要模型理解和记住长上下文中的信息。
在这两个任务中,作者们都设计了一系列实验,以测试模型在处理长上下文时的性能。他们测试了不同的模型,包括BERT、RoBERTa、GPT-3等,并且也测试了不同长度的上下文,以了解上下文长度对模型性能的影响。
最终的结果采用Sebastian Raschka老师的一幅图展示:
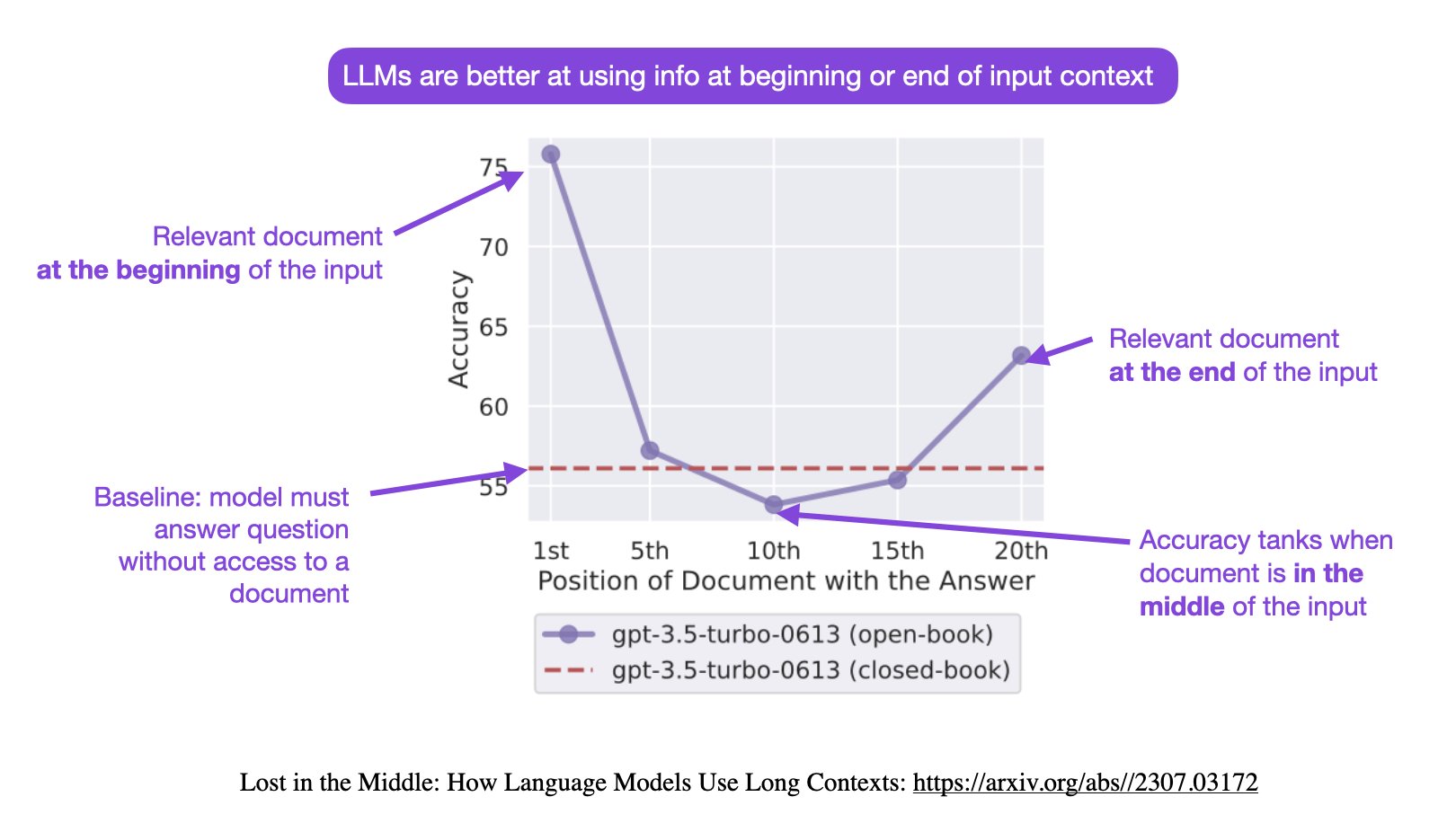
在大语言模型的输入上下文中改变相关信息的位置(即回答输入问题的段落的位置)会导致一个U形性能曲线——模型更擅长使用出现在输入上下文的开头或结尾的相关信息,而当模型需要访问和使用位于输入上下文中部的信息时,性能显著下降。例如,当将相关信息放置在输入上下文的中间时,GPT-3.5-Turbo在多文档问答任务上的开放式表现低于在没有任何文档的情况下的预测性能!也就是说,如果输入数据的重要信息没有出现在开始或者结尾位置,大模型可能会出现找不到答案的情况!
重要信息位置为什么会影响大模型的效果
这篇论文的发现在推特上引起了非常多的关注和讨论,因为这个结论真的很有意思。尽管这篇论文给了这样一个非常重要且有意思的结论,但是并没有回答为什么大模型会出现这种问题。Lightning AI的首席AI教育家, UW-Madison大学前统计学教授Sebastian Raschka也讨论了这个问题,给了他的一个观点。
Sebastian Raschka认为,基于transformer的大语言模型架构本身应该不会出现这种偏差。反而是基于RNN的模型可能会因为序列过长出现这种问题(因为RNN是按照序列处理的,早先处理的内容可能会被遗忘。而transformer是按照位置编码,一次性输入,没有先后概念)。因此,他怀疑可能是大多数人类写的文章内容习惯把重要的信息放在文章的开头和结尾,影响了大模型的训练结果。
这也是猜测,也有人认为,设计另一个类似论文的实验,但是测试代码类的问题可能就会看出是不是这样。因为,代码的执行是有逻辑的,不会出现把重要的信息放在文本的开头和结尾这种逻辑。emmmm~非常有意思的想法,的确是可以验证的。
论文资源
关于这篇论文结论讨论很多,这里不再一一列举,大家可以去看原文:
Lost in the Middle: How Language Models Use Long Contexts:https://arxiv.org/pdf/2307.03172.pdf
附:查看哪些大模型支持长输入?
如前所述,长输入对应大模型来说很重要,但是业界开源的支持长输入的大模型很少。DataLearner目前的大模型列表已经支持按照长输入类别筛选大模型了,欢迎大家体验,也支持按照语言优化、商用授权等信息查询~如下图所示:

查询地址:https://www.datalearner.com/ai-models/pretrained-models
