国产全球最长上下文大语言模型开源:XVERSE-13B-256K,一次支持25万字输入,免费商用授权~
大语言模型支持更长的上下文意味着模型可以一次处理更多的数据,可以一次性考虑更广泛、更深入的信息范围,这不仅提高了对话的连贯性和准确性,还使模型更好地理解复杂的话题和细微的语境变化。在财报分析、长篇文章写作等方面都有很高的价值。此前,商业大模型中上下文长度最高的是李开复零一万物的Yi-34B-200K上下文大模型以及Anthropic的Claude-2-200K模型,而深圳的元象科技开源了一个最高上下文256K的大语言模型XVERSE-13B-256K,可以一次性处理25万字左右,是目前上下文长度最高的大模型,而且这个模型是以Apache2.0协议开源,完全免费商用授权。
XVERSE-13B-256K的具体参数和开源地址参考DataLearnerAI模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/XVERSE-13B-256K
XVERSE-13B-256K介绍
XVERSE-13B-256K是基于XVERSE-13B-2继续训练得到的,后者是XVERSE开源一个130亿参数规模的大语言模型,该模型在3.2万亿tokens数据集上训练得到,各项评测指标结果与340亿参数的LLaMA2-34B水平差不多。
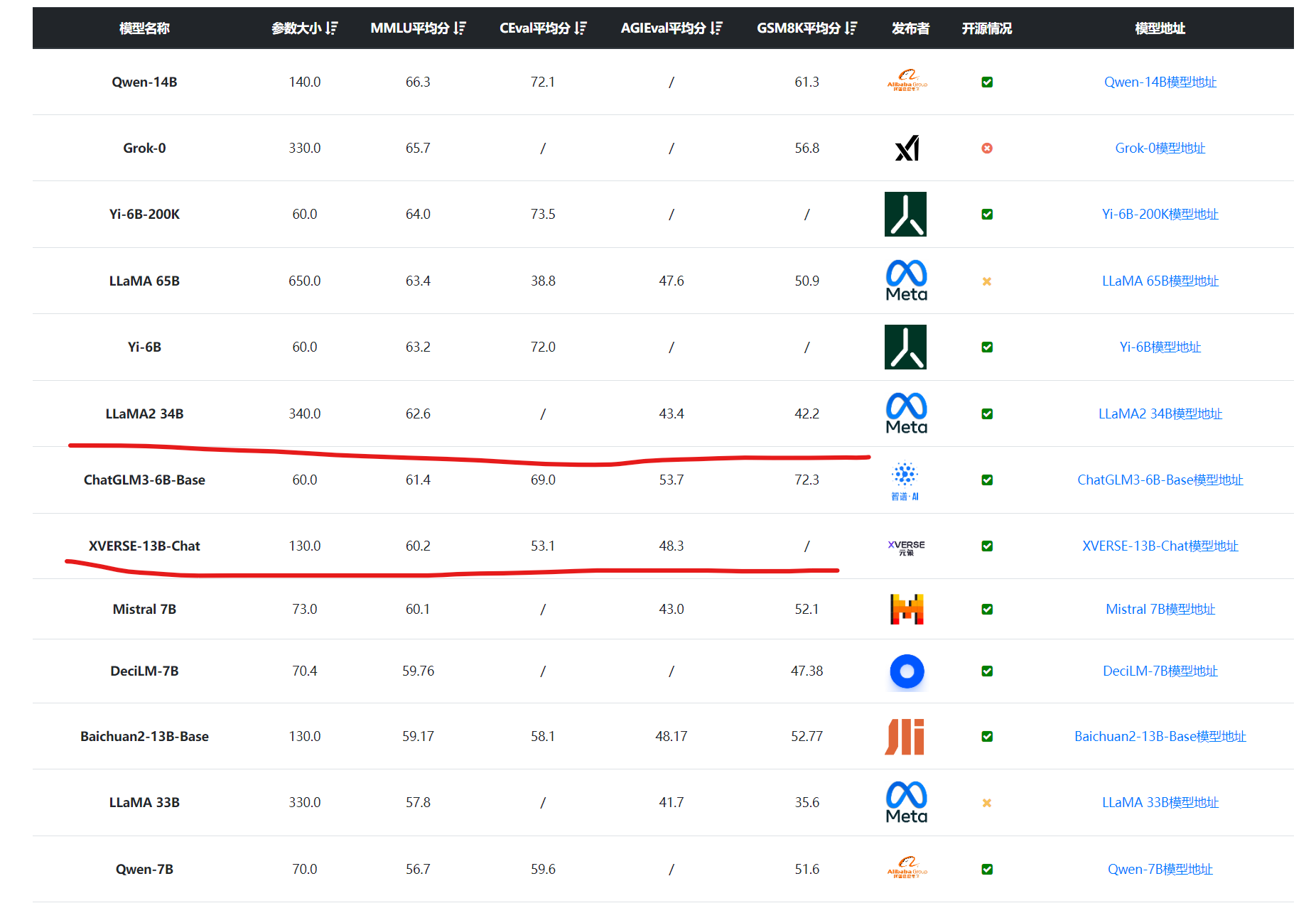
但是,XVERSE-13B-2本身只支持8K上下文,为了支持更长的上下文长度,元象科技在这个模型的基础上继续训练得到了 XVERSE-13B-256K模型。这也是目前全球最长上下文模型。
| 模型名称 | 是否中文优化 | 上下文长度 | 地区 |开源情况 | DataLearnerAI模型信息卡地址 | | ------------ | ------------ | ------------ | ------------ | ------------ | | XVERSE-13B-256K | 是 | 256K | 中国 |免费商用授权 | https://www.datalearner.com/ai-models/pretrained-models/XVERSE-13B-256K | | Yi-6B-200K | 是 | 200K | 中国|免费商用授权 | https://www.datalearner.com/ai-models/pretrained-models/Yi-6B-200K | | Yi-34B-200K | 是 | 200K | 中国|免费商用授权 | https://www.datalearner.com/ai-models/pretrained-models/Yi-34B-200K | |Claude-2.1 | 是 | 200K | 美国|不开源 | | |Baichuan2-192K| 是 | 192K | 中国| 免费商用授权 | https://www.datalearner.com/ai-models/pretrained-models/Baichuan2-192K | |GPT-Turbo-128K|是|128K|美国|不开源|| |GLM4|是|128K|中国|不开源|https://www.datalearner.com/ai-models/pretrained-models/GLM4 | |MPT-7B-StoryWriter-65k+|否|65K|美国|免费商用授权| https://www.datalearner.com/ai-models/pretrained-models/MPT-7B-StoryWriter-65k+ |
从这个表可以看出,在超长上下文大语言模型的赛道中,国内有很多开源都在做,而美国最大的2个商业模型也都支持超过100K的上下文,不过都是闭源的。而XVERSE-13B-256K是目前上下文长度最高的。
XVERSE-13B-256K的评测效果
针对模型超长上下文能力的评测目前业界没有很多的评测基准,用的最多的有2类,分别是LongBench和needle in a haystack”(大海捞针)测试。
LongBench是清华大学KEG小组推出的一个针对大语言模型长上下文能力的基准测试,包含了14个英文任务和5个中文任务,以及2个代码任务。任务的长度从5K到15K不等,共4750个测试数据集。官方提供的一些测试结果如下:
这是一个简单的对比,因为LongBench本身缺少完整的Leaderboard,上述数据来自XVerse的HF公布的结果。LongBench官方公布的一些模型中最好的也是GPT-3.5-Turbo-16k与ChatGLM3-6B,结果也在40多分,可以理解为XVERSE-13B-256K在长上下文的表现上应该是超过了60亿参数规模的大模型,与GPT-3.5-Turbo-16K和ChatGLM3-6B差不多的水平。
而在另一项needle in a haystack”(大海捞针)测试中,XVERSE-13B-256K取得了99.67%的得分,表现非常优秀。大模型“大海捞针”测试就是给定一篇超长上下文,然后插入一句与全文无关的内容,用大模型针对这个无关内容提问,如果大模型能准确回答,则说明大模型超长上下文支持良好,这个测试虽然不严谨,但是某种程度上可以代表大模型对超长上下文的支持水平。具体测试过程可以详情参考此前GPT-4与Claude的测试:https://www.datalearner.com/blog/1051699526438975 和 https://www.datalearner.com/blog/1051701947131881
而昨天智谱AI的GLM4发布会上公布的大海捞针测试结果:
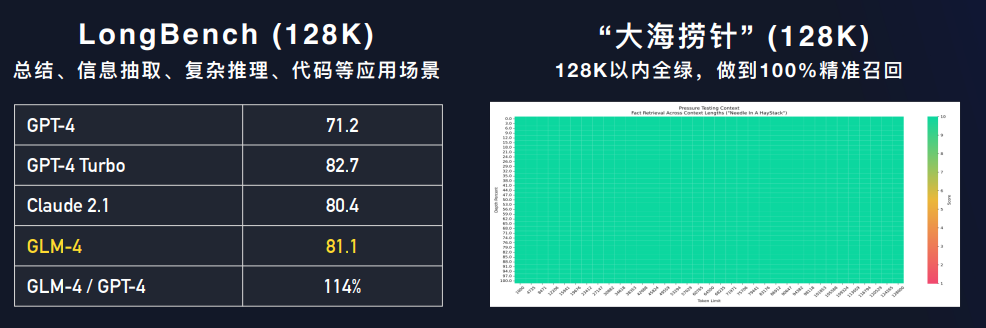
如果是相同的测试,那意味着XVERSE-13B-256K效果在这方面的表现还是非常惊人的!
XVERSE-13B-256K是如何训练出来的
大模型的超长上下文的训练非常困难,主要是上下文长度增加之后模型训练过程的显存消耗会大幅增加,而且也容易导致遗忘长序列的知识。元象科技也公布讨论了自己的长上下文训练策略:
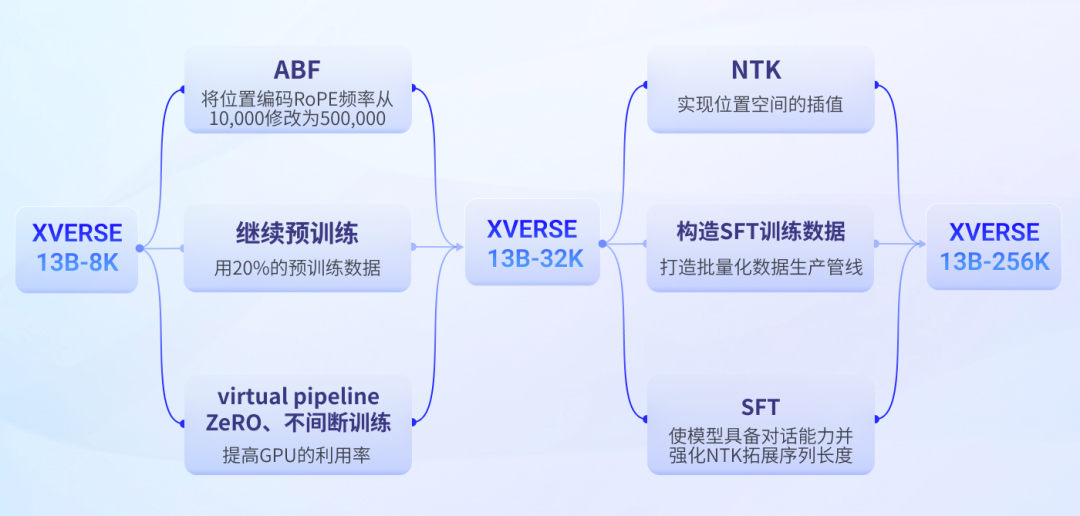
简单来说,就是在8K模型的基础上先基于ABF技术用更长的输入数据继续进行预训练,得到32K上下文大模型,然后通过微调技术将上下文拓展到256K。这部分具体的操作也可以参考他们官方发布的原文的内容:https://mp.weixin.qq.com/s/R8ewi1NsAK9Qwh0e7UyyBw
XVERSE-13B-256K总结
总的来说XVERSE-13B-256K是目前最高上下文长度的模型。在特殊的应用场景,如财报分析、PDF问答等场景是非常有价值的。它的水平可以理解为与GPT-3.5-Turbo-16K差不多,比大部分60亿参数规模的模型都要好,最主要的是该模型是免费商用授权,这是非常难得的。而目前他们官网也可以体验这个模型,对于有需求的童鞋来说可以先行测试~
