如何提高大模型在超长上下文的表现?Claude实验表明加一句prompt立即提升效果~
Claude 2.1版本的模型上下文长度最高拓展到200K,也是目前商用领域上下文长度支持最长的模型之一。但是,在模型发布不久之后,有人测试发现Claude 2.1模型在超过20K之后效果下降明显。但是Anthropic官方发布了一个说明解释这不是Claude模型本身在超长上下文的真实原因,主要是模型拒绝回答一些与文章主体不符的内容,实际中只需要一句prompt即可提高性能,将模型在超长上下文的水平准确率从27%提高到98%。

Claude2.1的超长上下文水平简介
Claude是Antropic公司发布的一个大语言模型,也是目前为止被大家认为GPT-4最强大的竞争对手之一。这个模型最大的特点就是在文档处理方面表现非常好。DataLearnerAI实际使用中发现它对文档的处理甚至比GPT-4更加优秀!
在上个月,Anthropic发布了Claude 2.1版本,这个版本的上下文长度拓展到了200K,是目前商用领域最长上下文模型之一。而有人测试实际结果并不好。
此前,有用户通过在超长上下文中注入一段特别的句子让模型回答用来测试大模型在超长上下文条件的表现(具体测试参考:GPT-4-Turbo的128K长度上下文性能如何?超过73K Tokens的数据支持依然不太好!)。发现GPT-4-128K模型在超过73K之后模型的性能开始下降:
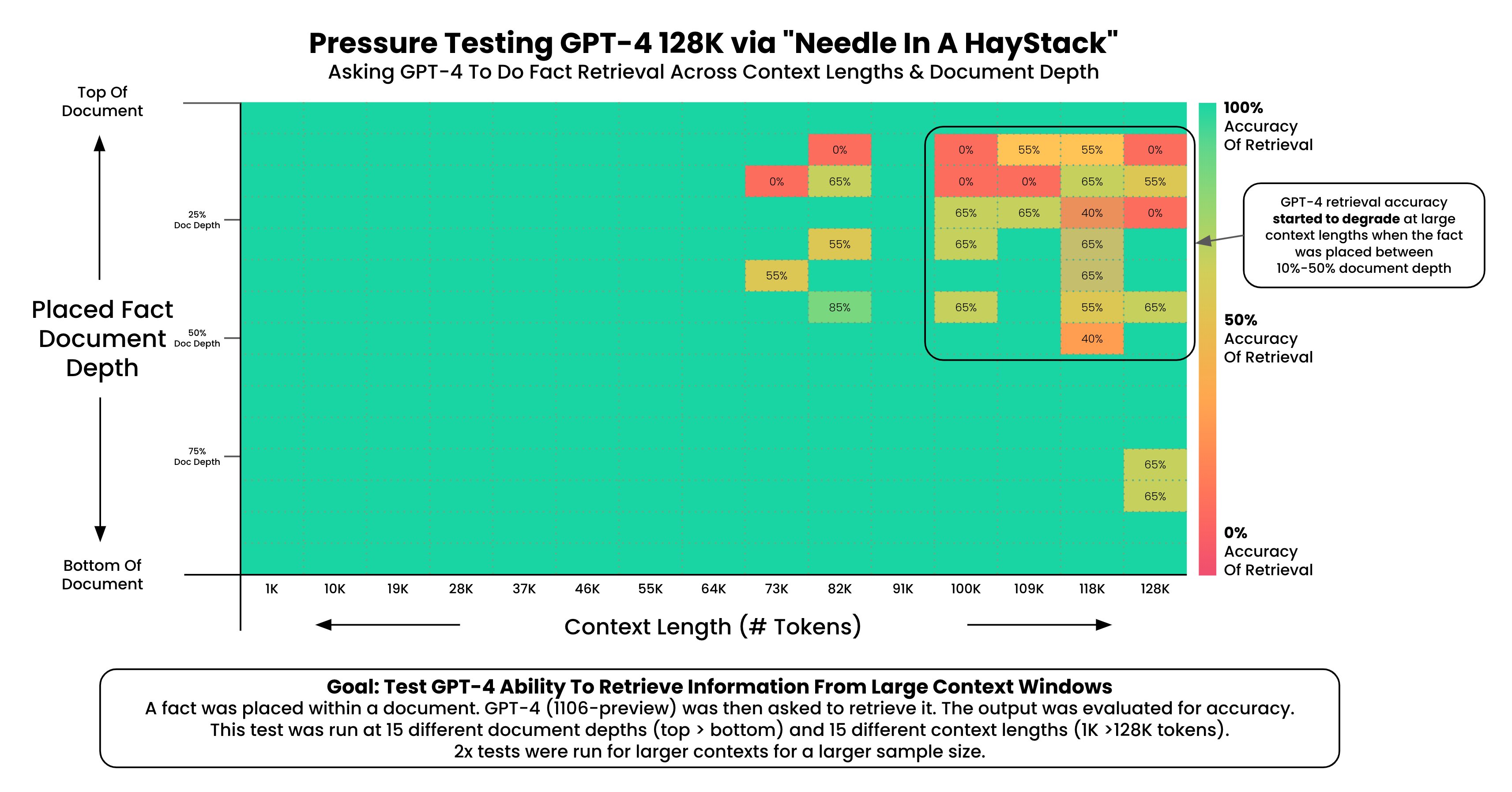
为了测试GPT-4 Turbo在超长上下文中准确定位信息的能力,作者随机在论文不同位置插入一句话“The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.”。然后让GPT-4只能用这个论文作为回答的依据。上图的横坐标是文档的长度,纵坐标是插入的文本在文档的位置。可以看到,在右上角区域模型表现效果很差,这些基本都是文档上半段,然后开始位置之后(7%位置之后)。但是如果这句话在文档下半段效果反而还可以。
Claude-2.1-200K推出之后,作者做了同样的测试,发现Claude-2.1表现非常差:

可以看到,当文档长度超过20K之后,表现就非常差,与Anthropic官方的说法差别很大。
而今天,Anthropic官方发布了一个博客解释,这个不是因为Claude模型能力不行,而是测试的方式不太好。
模型不愿意回答与文本不相干的内容
Claude 2.1接受了大量关于长文档任务的反馈训练,比如总结一个S-1长度的文档。这种训练帮助模型减少错误,并避免提出无依据的声明。相比Claude 2.0,其错误率降低了30%,错误地声明文档支持某个说法的频率降低了3-4倍。
但是,为了减少错误和避免提出无依据的声明,Claude 2.1被训练成在没有足够信息支持回答时不回答问题。这意味着如果文档没有提供足够的信息来明确回答一个问题,模型可能会选择不作回答。模型的训练数据可能包括减少不准确性的特定任务。如果模型在训练过程中接收到避免错误和不准确声明的强烈信号,它可能会在实际应用中表现出更多的谨慎。进而导致上述情况出现。
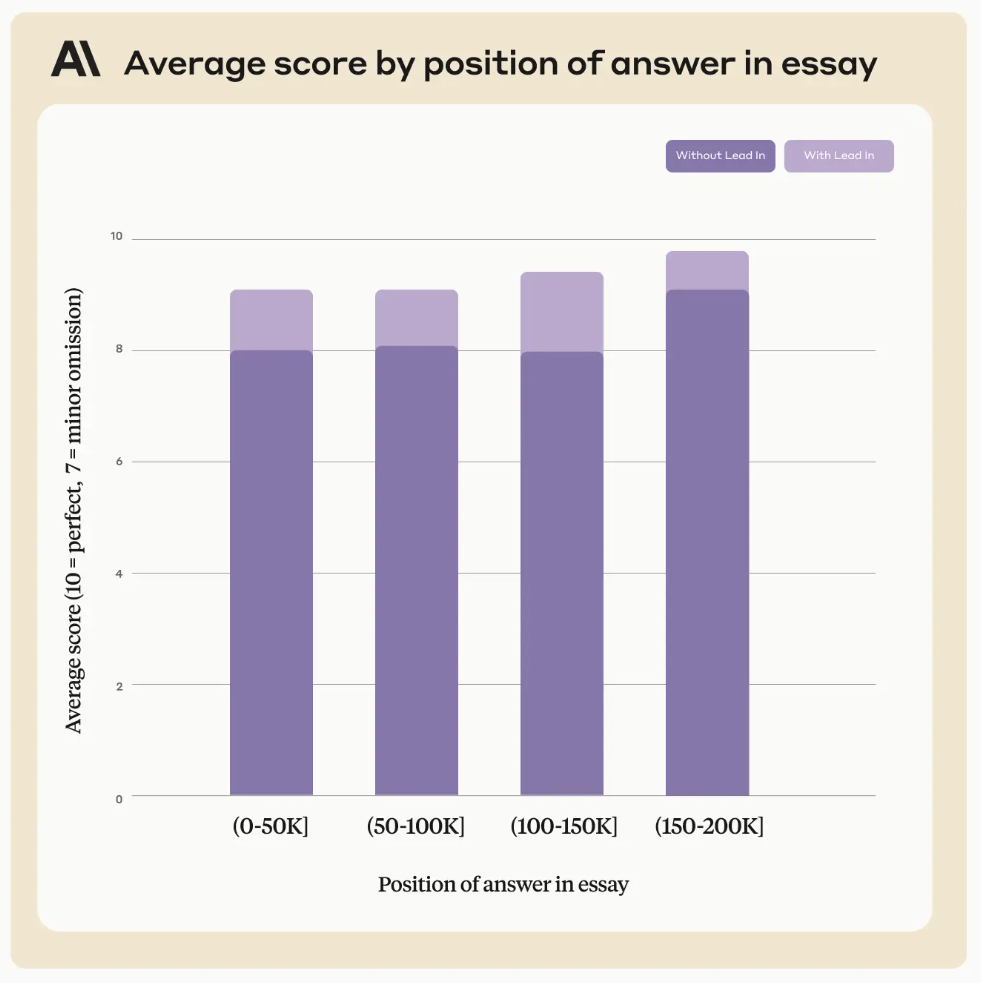
为了证明这个结论,Anthropic用同样的论文实验,但是询问的是文章内容相关的问题,并且把答案重新排序,发现Claude还是可以准确回答:

上图可以看到,不管答案位于论文说明位置,Claude表现都不错。
而进一步的,Anthropic发现可以通过简单的prompt提示就可以提高模型不愿意回答不相关内容的效果,即让模型回答问题之前,加上一句“Here is the most relevant sentence in the context:”即可大幅提升模型回答效果,改进模型不愿意回答不相关内容的水平。
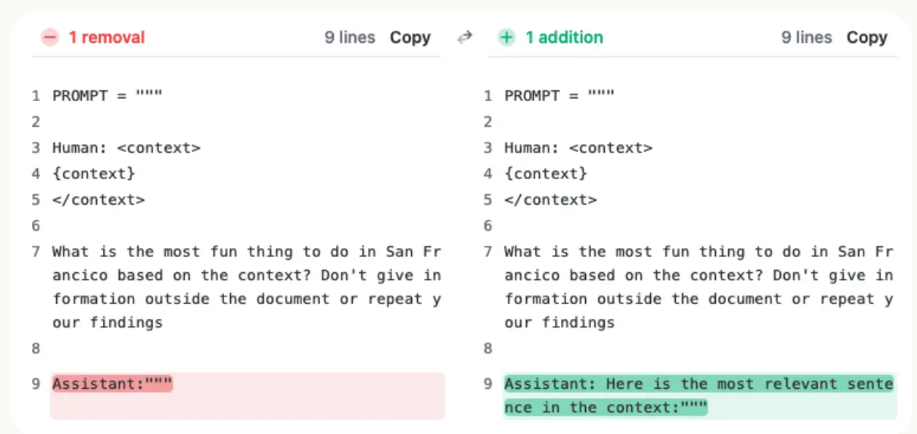
上图1是改进方法,图2是改进后模型的回答效果,几乎可以非常准确地在任意长度下回答对问题。这种提示技巧不仅有助于处理插入或不适当的句子,而且还改善了模型对原始文档中句子的处理。即使句子完全符合上下文,这种提示方法仍然能提高模型的准确率。
总结
根据上面的信息其实我们也可以看出一些非常有价值的结论。即模型的表现在很大程度上取决于其训练过程。如果我们通过大量的反馈和真实世界任务进行训练,这可以帮助模型在处理长文本任务时减少错误并避免提出无依据的声明。但是,这也导致模型在面对看似不适当或与上下文不符的句子时表现出犹豫,这反映出模型在确保回答质量方面的内在谨慎性。同时,这也指出了模型的某些局限性,即在处理非典型或歧义性数据时可能需要更多的上下文指导。
另一个比较重要的结论是,Prompt(提示工程)对于提高模型性能至关重要。通过简单的提示调整,如在回答前加入特定的引导句,可以显著提升模型的准确性和效率。这表明在使用复杂的AI模型时,用户输入的精确度对于获取准确和有用的输出至关重要。
模型的超长上下文对于实际应用中很有价值,欢迎大家持续关注DataLearnerAI在超长上下文上的技术总结和进展追踪:https://www.datalearner.com/blog_list/tag/long-context
