A21 Labs宣布开源520亿参数的全新混合专家大模型(Mixture of Experts,MoE)Jamba:单个GPU的上下文长度是Mixtral 8x7B的三倍
A21实验室是一家以色列的大模型研究机构,专门从事自然语言处理相关的研究。就在今天,A21实验室开源了一个全新的基于混合专家的的大语言模型Jamba,这个MoE模型可以在单个GPU上支持最高140K上下文的输入,非常具有吸引力。
Jamba大模型简介
Jamba是一个基于结构状态空间和transformers架构结合的大语言模型。是基于此前卡耐基梅隆大学和普林斯顿大学发布的Mamba模型的实践结果。
Mamba是基于结构化状态空间模型(Structured State Space Models,简称SSMs)训练的大模型。这个技术的核心思想是为了解决当前原生transformer架构在长序列输入的劣势。SSMs的核心思想是将输入序列通过一个隐含的状态空间进行转换,以此来捕捉序列中的动态特征和长期依赖关系。根据此前的研究,SSMs技术做的大模型有比常规的Transformer模型快5倍的吞吐量,支持处理数百万长度的序列数据。这个思路与此前泄露的OpenAI的Q*算法有异曲同工之妙:OpenAI秘密武器Q到底是什么?一个神秘帖子的解密:Q是一个不同于当前大模型推理方式的新对话生成系统
Jamba就是在Mamba基础上进行技术革新而训练的大语言模型。其核心技术特点是基于SSMs与transformer技术结合。此外,该模型还是一个混合专家技术的模型。
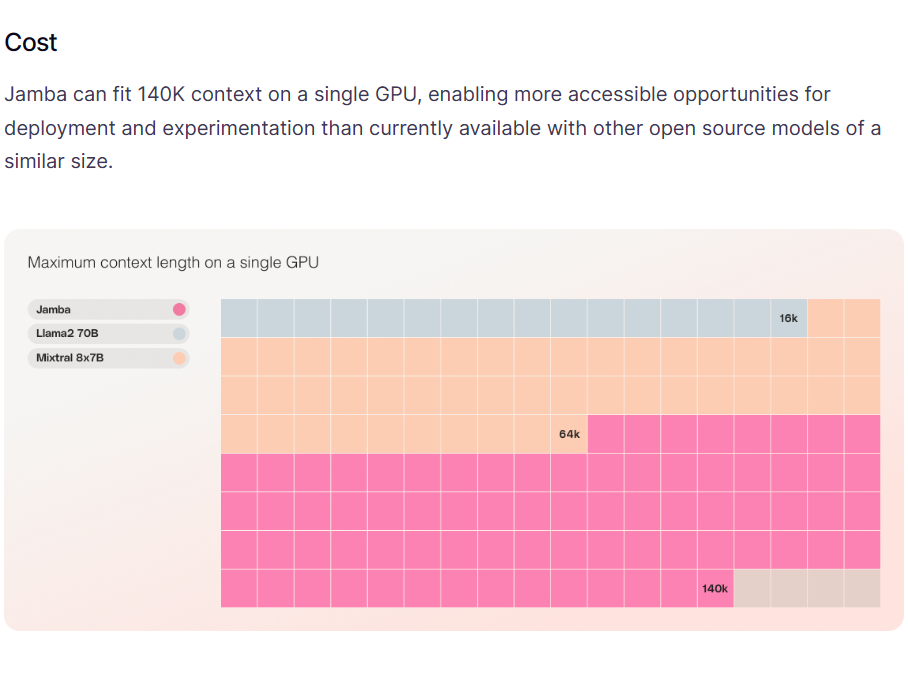
Jamba模型拥有520亿个参数,但在推理时只使用了其中的120亿个参数。这种设计使得模型在保持高效性能的同时,减少了对计算资源的需求。Jamba的架构允许它在单个GPU上处理高达140K的上下文,这比其他同等规模的开源模型更具可访问性。
Jamba模型的评测结果
Jamba在长上下文处理上的吞吐量是Mixtral 8x7B的三倍。在实际多GPU上最高支持256K的超长上下文!Jamba与其它MoE架构大模型对比如下:
| 模型信息 | 总参数数量 | 专家网络数目 |推理使用参数量 | 模型信息卡地址| | ------------ | ------------ | ------------ | ------------ | |Jamba | 520 | 16 | 120 | https://www.datalearner.com/ai-models/pretrained-models/Jamba-v0_1| |DBRX | 1320 | 16 | 360 | https://www.datalearner.com/ai-models/pretrained-models/DBRX-Instruct| |Mixtral-8×7B-MoE | 467 | 8 | 120 | https://www.datalearner.com/ai-models/pretrained-models/Mistral-7B-MoE | | Grok-1 | 3140 | 8 | 860 | https://www.datalearner.com/ai-models/pretrained-models/Grok-1 |DeepSeekMoE-16B | 164 | 8 | 28| https://www.datalearner.com/ai-models/pretrained-models/DeepSeekMoE-16B-Chat |
而在实际的评测数据上,Jamba的推理能力表现非常好,但综合理解和评价则表现不那么突出。如下图所示是Jamba模型和其它模型的对比:

可以看到,它的评测结果与Mixtral 8x7B各有优劣,但是差距不大。按照此前业界对Mixtral 8x7B的好评,Jamba模型非常值得期待生产实践的应用效果。
此外,Jamba模型的参数数量与Mixtral 8x7B在差不多的水平,总参数数量和推理时激活的参数数量差不多。评测结果也很接近。但是,Jamba一个优势是它的上下文长度比Mixtral 8x7B更高,且在单个GPU(80G显存)上即可支持最高140K的上下文(而Mixtral 8x7B单个GPU最高支持64K上下文)。
而Jamba另一个优点是推理的速度非常快,即便是在超长上下文输入每秒生成的tokens速度也很快。

还有一个值得注意的事情是Jamba的训练数据是截止到2024年3月5日,非常新!那就是说这个模型的训练时间非常短,知识很新。
Jamba模型的开源情况和总结
Jamba模型的预训练结果以Apache2.0协议开源,意味着完全免费商用授权。
Jamba信息总结如下:
- 🧠 具有 52B 个参数,生成时活跃的有 12B
- 👨🏫 16位专家,生成时活跃的有2位
- 🆕 采用新架构,具有联合注意力机制和 Mamba
- ⚡️ 支持 256K 的上下文长度
- 💻 在单个 A100 80GB 上可适配高达 140K 的上下文
- 🚀 与 Mixtral 8x7B 相比,长上下文的处理吞吐量提高了3倍
- 🔓 以 Apache 2.0 许可证发布
- 🤗 可在 Hugging Face 和 Transformers (>4.38.2) 上使用
- 🏆 在 Open LLM Leaderboard Benchmarks 上与公开的大型语言模型竞争
- ❌ 没有关于训练数据或语言支持的信息
同时,Jamba支持8bit量化推理和PEFT微调,HF上都有代码。关于Jamba具体信息参考:https://www.datalearner.com/ai-models/pretrained-models/Jamba-v0_1
