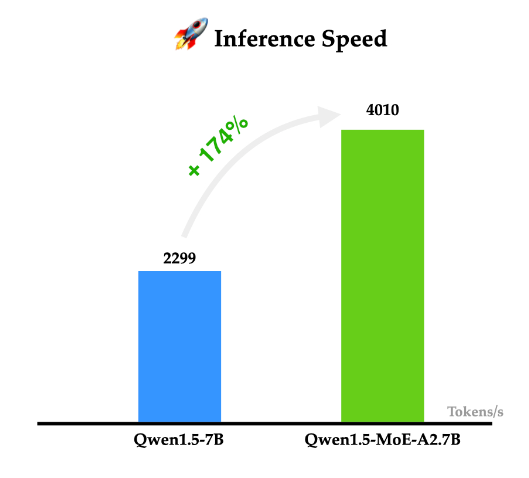
重磅!阿里巴巴开源自家首个MoE技术大模型:Qwen1.5-MoE-A2.7B,性能约等于70亿参数规模的大模型Mistral-7B
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。
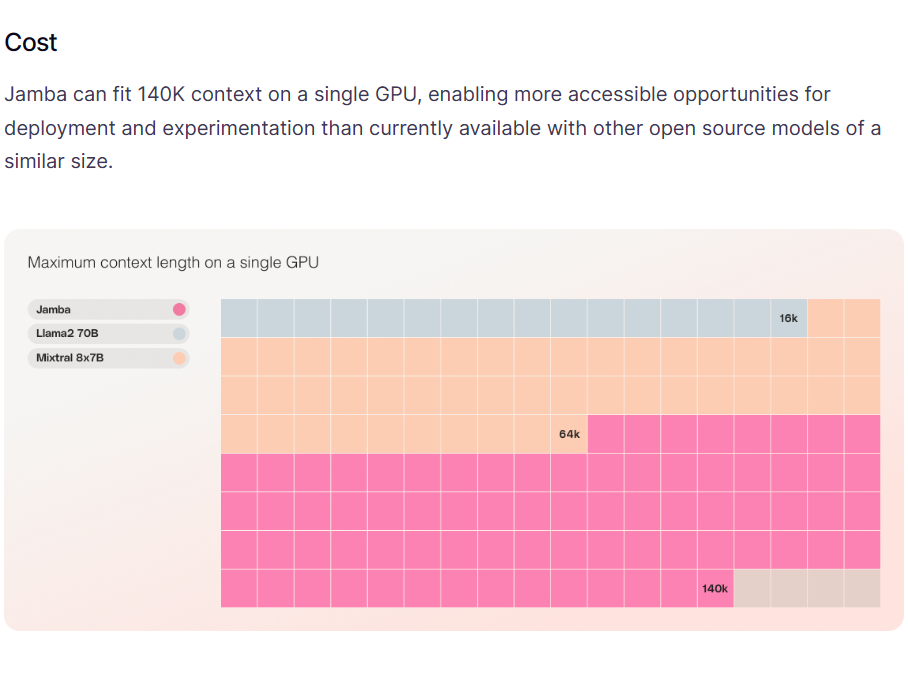
A21实验室是一家以色列的大模型研究机构,专门从事自然语言处理相关的研究。就在今天,A21实验室开源了一个全新的基于混合专家的的大语言模型Jamba,这个MoE模型可以在单个GPU上支持最高140K上下文的输入,非常具有吸引力。
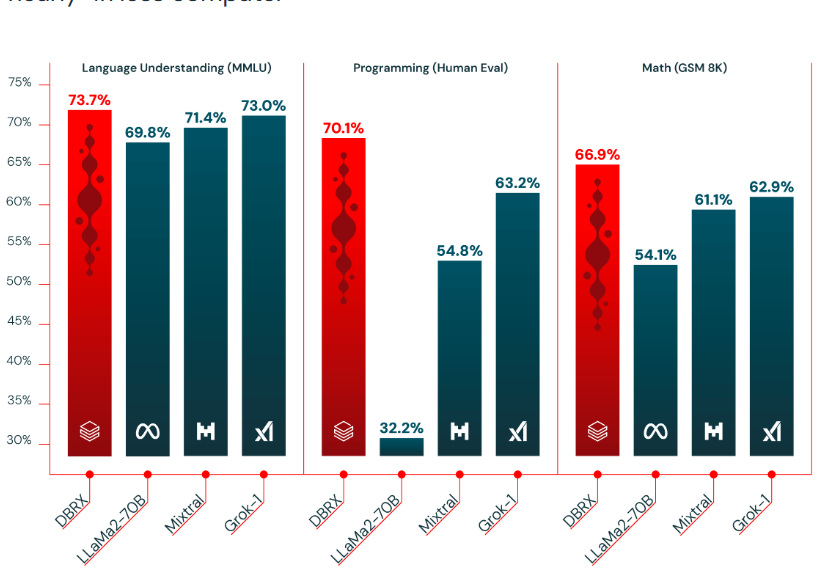
基于混合专家技术的大语言模型是当前大语言模型的一个重要方向。去年MistralAI开源了全球最有影响力的Mixtal-8×7B-MoE模型,吸引了很多关注。在2024年3月27日的今天,Databricks宣布开源一个全新的1320亿参数的混合专家大语言模型DBRX。