开源领域大语言模型再上台阶:Databricks开源1320亿参数规模的混合专家大语言模型DBRX-16×12B,评测表现超过Mixtral-8×7B-MoE,免费商用授权!
基于混合专家技术的大语言模型是当前大语言模型的一个重要方向。去年MistralAI开源了全球最有影响力的Mixtal-8×7B-MoE模型,吸引了很多关注。在2024年3月27日的今天,Databricks宣布开源一个全新的1320亿参数的混合专家大语言模型DBRX。
DBRX简介
DBRX是Databricks开源的一个transformer架构的大语言模型。包含1320亿参数,共16个专家网络组成,每次推理使用其中的4个专家网络,激活了360亿参数。
它与业界著名的混合专家网络模型对比结果如下:
| 模型信息 | 总参数数量 | 专家网络数目 |推理使用参数量 | 模型信息卡地址| | ------------ | ------------ | ------------ | ------------ | |DBRX | 1320 | 16 | 360 | https://www.datalearner.com/ai-models/pretrained-models/DBRX-Instruct| |Mixtral-8×7B-MoE | 467 | 8 | 120 | https://www.datalearner.com/ai-models/pretrained-models/Mistral-7B-MoE | | Grok-1 | 3140 | 8 | 860 | https://www.datalearner.com/ai-models/pretrained-models/Grok-1 |DeepSeekMoE-16B | 164 | 8 | 28| https://www.datalearner.com/ai-models/pretrained-models/DeepSeekMoE-16B-Chat |
可以看到,DBRX模型已经是业界混合专家模型中规模较大的一个了,而且与大家都不同的是它有16个专家网络,每次推理会使用其中的4个。而且每次推理使用的参数量也不少,有360亿。根据官方的数据,它的推理速度是Llama2-70B的2倍,效果却比Llama2-70B效果更好。
官方说,它们专家组合的可能数量是常规的8个专家网络组成的混合专家网络的65倍,计算逻辑应该是16个选4个专家可能有1820种组合,而8个专家任选2个有28种可能。所以是65倍的组合可能性!这个角度怎么说呢,不知道影响有多大。
另外,DBRX模型是在12万亿tokens的文本和代码数据集上训练得到,使用了RoPE、GLU、GQA等技术。在3072个NVIDIA H100上训练了2-3个月时间。DBRX分为两个版本,一个是预训练的基座大模型DBRX Base,一个是指令优化微调的DBRX Instruct。
DBRX模型的评测结果
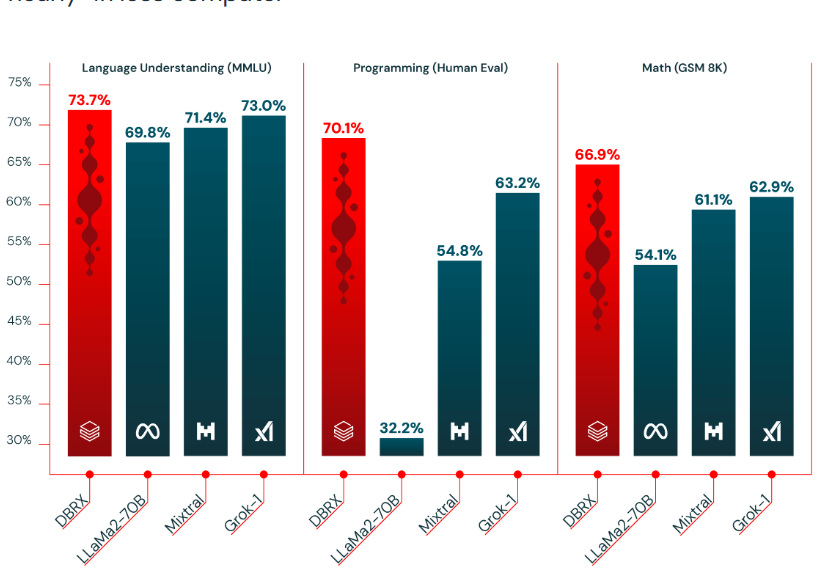
官方公布了DBRX与其它模型的评测对比,我们这里先看一下几个MoE模型的对比结果:
| 模型信息 | MMLU | GSM8K | HumanEval | MT-Bench | | ------------ | ------------ | ------------ | ------------ | |DBRX-Instruct | 73.7 | 72.8 | 70.1 | 8.39| |Mixtral-8×7B-MoE | 71.4 | 61.1 | 54.8 | 8.3| | Grok-1 | 73.0 | 62.9 | 63.2 | - |DeepSeekMoE-16B | 47.2 | 62.2 | 45.7| - |
这里的MMLU是综合理解能力,GSM8是数学推理能力,HumanEval是代码能力,而MT-Bench则是基于GPT-4的评分。从这个对比结果看,DBRX Instruct在各项评测上结果都很优秀,表现超过了其它MoE大模型。此前,开源的Mixtral-8×7B-MoE在各个应用领域好评如潮,因此,DBRX值得期待。不过需要注意的是,DBRX至少需要320GB显存才能进行推理。而Mixtral-8×7B-MoE是95GB即可运行。硬件成本差距较大!
在DataLearnerAI收集的大模型排行榜数据种,按照MMLU评分排序,DBRX Instruct排名为止仅仅比Grok-1高,低于李开复零一万物的Yi-34B和Qwen1.5-72B。

DBRX在长上下文和检索增强任务的评测
除了常规的评测外,Databricks还公布了DBRX在长上下文任务以及检索增强生成(Retrieval Augmented Generation, RAG)任务中的表现。
首先是大海捞针测试:
在较长的上下文中,DBRX Instruct比Mixtral Instruct略好。
而在RAG任务中,DBRX表现也很好。
DBRX模型总结
DBRX模型是Databricks自家的开源协议,可以免费商用。而这么大的模型推理成本也很高,大部分人估计很难用上。而现在Databricks自己也提供了这个模型的API接口,可以达到每秒150个tokens,这个速度也非常可以。
DBRX Base模型开源地址和其它信息:https://www.datalearner.com/ai-models/pretrained-models/DBRX-Base DBRX Instruct模型开源地址和其它信息:https://www.datalearner.com/ai-models/pretrained-models/DBRX-Instruct
