国产MoE架构模型大爆发!深圳元象科技XVERSE开源256亿参数MoE大模型XVERSE-MoE-A4.2B,评测结果接近Llama1-65B
混合专家架构大模型是当前最火热的一个大模型技术发展方向。三月底,业界开源了多个混合专家大模型,包括DBRX、Qwen1.5-MoE-A2.7B等。而在四月初,又一家国产大模型企业开源了一个全新的MoE架构的模型,即深圳元象科技XVERSE开源的XVERSE-MoE-A4.2B。该模型参数256亿,推理时仅激活42亿参数,效果与当前主流的130亿参数的规模差不多。
XVERSE-MoE-A4.2B模型简介
混合专家架构的大语言模型在最近一段时间集中爆发!在2023年,Mixtral 8×7B MoE模型发布之后,MoE架构模型吸引了大量的注意。
目前,根据DataLearnerAI收集的模型数据,国产开源的MoE架构模型并不多,目前只有阿里的通义千问、DeepSeek的DeepSeek LLM等,有相应的模型开源,但总参数规模都不超过200亿。
而深圳元象科技XVERSE本次开源的MoE架构的大模型,总参数量256亿,是当前国产开源MoE架构模型中总参数量最高的一个(此前,XVERSE也是国内最早开源600亿参数规模的大模型,XVERSE-65B,详情参考:截止目前为止最大的国产开源大模型发布:元象科技开源XVERSE-65B大模型,16K上下文,免费商用,该模型也是Apache2.0协议开源,可以说XVERSE在模型开源方面一直做的比较积极)。
目前国产的三个开源MoE架构模型参数对比如下:
从上面的架构对比可以看到,这三个国产MoE模型的架构很相似,都是采用非常多的小专家。与此前Mixtral-8×7B-MoE模型的做法完全不同(8个专家,推理时激活2个)。根据XVERSE发布的内容看,这样的效果是最优的。与另外两个模型不同的是,XVERSE-MoE-A4.2B固定了2个专家,每次推理的时候必然激活,而剩余的6个专家则是根据推理输入进行路由选择,这样的做法的原因是保证模型在基础通用能力上获得对应的领域性能。关于这三个国产MoE模型的具体信息可以参考DataLearnerAI的模型信息卡。
从上述三个模型的对比结果看,XVERSE-MoE-A4.2B的参数数量是最高的。
XVERSE-MoE-A4.2B模型的评测结果
根据官方公布的数据, XVERSE-MoE-A4.2B模型的评测结果与阿里的Qwen1.5-MoE-A2.7B接近,超过了DeepSeek-16B-MoE模型,与Mistral-7B、LLaMA2 34B等在同一个水平。与元象科技自家发布的XVERSE-13B-2相比,几乎时同一水平,二者均是在2.7万亿tokens数据集上训练,但是XVERSE-MoE-A4.2B模型训练的时间减少了50%,计算量降低了30%。
下图是DataLearnerAI收集的全球主流大模型评测排行数据,按照MMLU排序的结果:
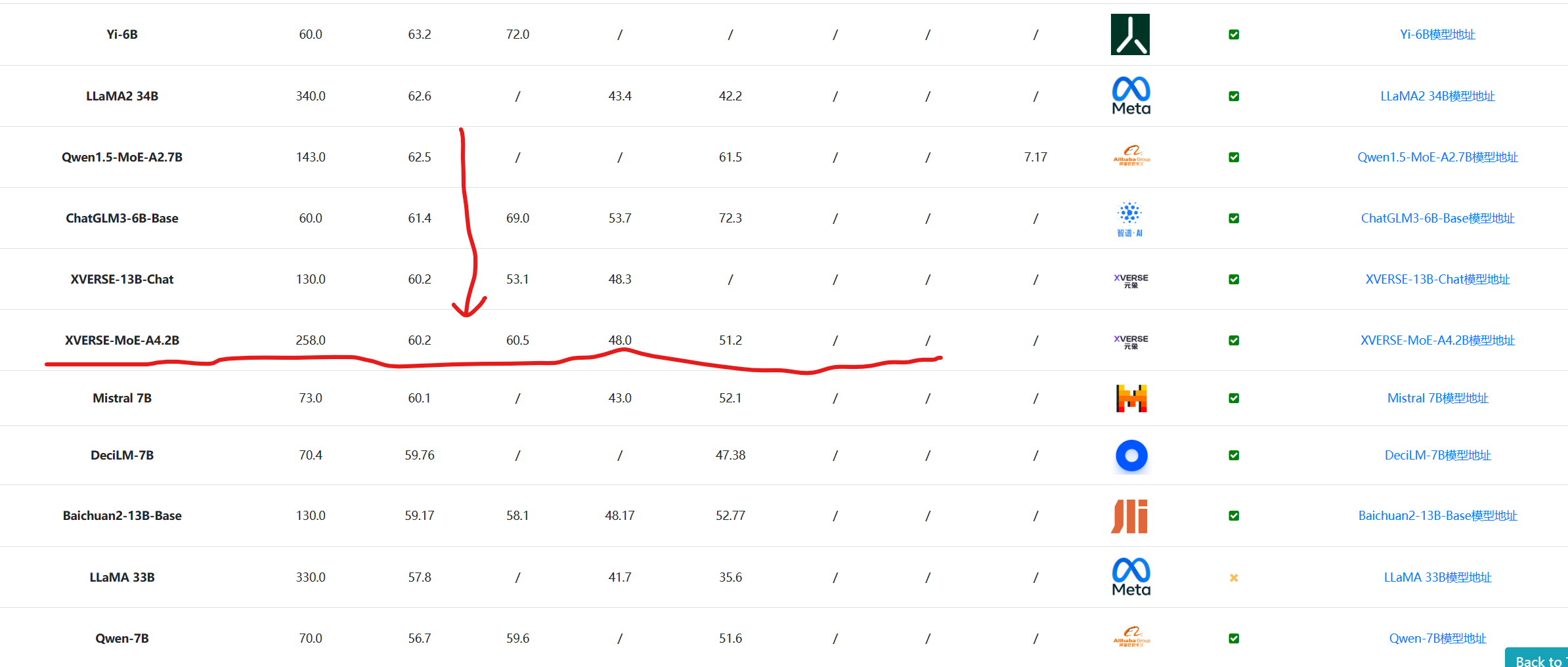
从这些分析结果也可以看到,当前MoE模型普遍的三大特点是:1)训练资源减少;2)推理显存不变(与总参数数量持平);3)推理速度变快;4)性能超过推理使用的参数规模模型,但是低于总参数规模模型。也就是说,目前MoE模型最大的特点是用显存换速度!
XVERSE-MoE-A4.2B模型也是如此,官方也发出了XVERSE-MoE-A4.2B模型与其它模型的对比结果:
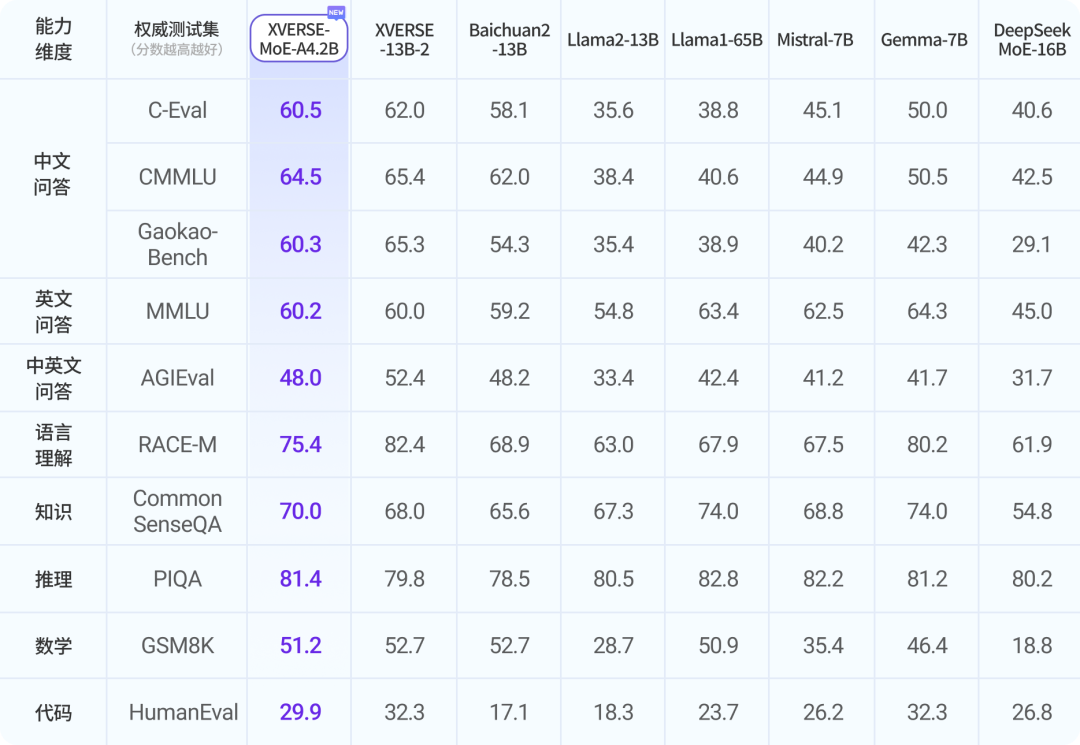
与主流的130亿参数规模的模型基本差不多,明显好于较早发布的一些模型。
XVERSE-MoE-A4.2B模型的开源情况和下载地址
除了前面描述的特点外,XVERSE-MoE-A4.2B模型最大的优点是以Apache2.0协议开源。与其它模型有显著不同,Apache2.0是非常友好的开源协议,意味着这个模型几乎可以无条件免费商用。关于模型的HuggingFace预训练开源地址以及推理代码地址参考DataLearnerAI的XVERSE-MoE-A4.2B模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/XVERSE-MoE-A4_2B
元象科技旗下开源了多个模型,都是Apache2.0开源协议,在国产开源大模型领域一直是较早开源大规模参数(600亿以上模型是第一个开源的)模型的企业,关于XVERSE的简介和所有开源的模型可以参考DataLearnerAI关于XVERSE的介绍:https://www.datalearner.com/ai-organizations/xverse
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
