重磅!百度文心一言开源,包含2个多模态大模型,4个大语言模型,最大参数量4240亿!完全免费商用授权!
今天,百度正式宣布开源其最新的旗舰级大模型系列——ERNIE 4.5。ERNIE 4.5系列模型当前包含2个多模态大模型,4个大语言模型及其不同变体的庞大家族,还区分了PyTorch版本和paddlepaddle版本,共23个模型,其核心采用了创新的异构多模态混合专家(MoE)架构,在提升多模态理解能力的同时,实现了文本处理性能的同步增强。每个版本的模型都开源了基座(Base)版本和后训练版本(不带Base)。

本次开源遵循 Apache 2.0 协议,意味着社区可以自由地进行商业化使用和二次开发。同时,百度还配套开源了从训练、微调到部署的全栈工具链,可以说开放得及其彻底。
ERINE 4.5系列模型简介
此次百度开源的ERINE-4.5系列模型共23个,包含2个多模态大模型,4个大语言模型及其不同变体的庞大家族,还区分了PyTorch版本和paddlepaddle版本。最低是仅3亿参数(0.3B)的语言模型,除了这个版本不是MoE架构外,其它都是。
可以说,本次百度开源的模型十分全面,从最低0.3B的端侧模型,到最高4240亿的超大参数规模大模型以及多模态大模型,非常全面。另外,还很贴心开源了PyTorch和Paddle两个版本,最重要的是,这些模型全部是Apache2.0协议开源,完全免费商用授权。
ERINE 4.5性能实测:传统测试很棒,但是具有挑战性的测试表现一般
百度也开放了ERINE-4.5系列模型的多个评测结果。虽然官方宣传在大多数评测基准上百度的模型都是领先的。不过,DataLearnerAI发现,百度的评测结果中包含了大量的传统的评测基准,如MMLU、MMLU Pro等,当然也有最新的LiveCodeBench和AIME系列。但是,不幸的是,尽管传统评测基准上得分很高。在这些最新的评测基准上,百度的评分却非常一般。而传统评测,很多业界新的模型已经不再对比了,因为区分度并不高。
ERINE-4.5-300B-A47B与其它模型在传统评测上的对比
为了更好更直观的对比ERINE-4.5系列和其它模型,我们首先看一下,传统的MMLU等评测的结果,如下图所示(橙色的是百度的模型):
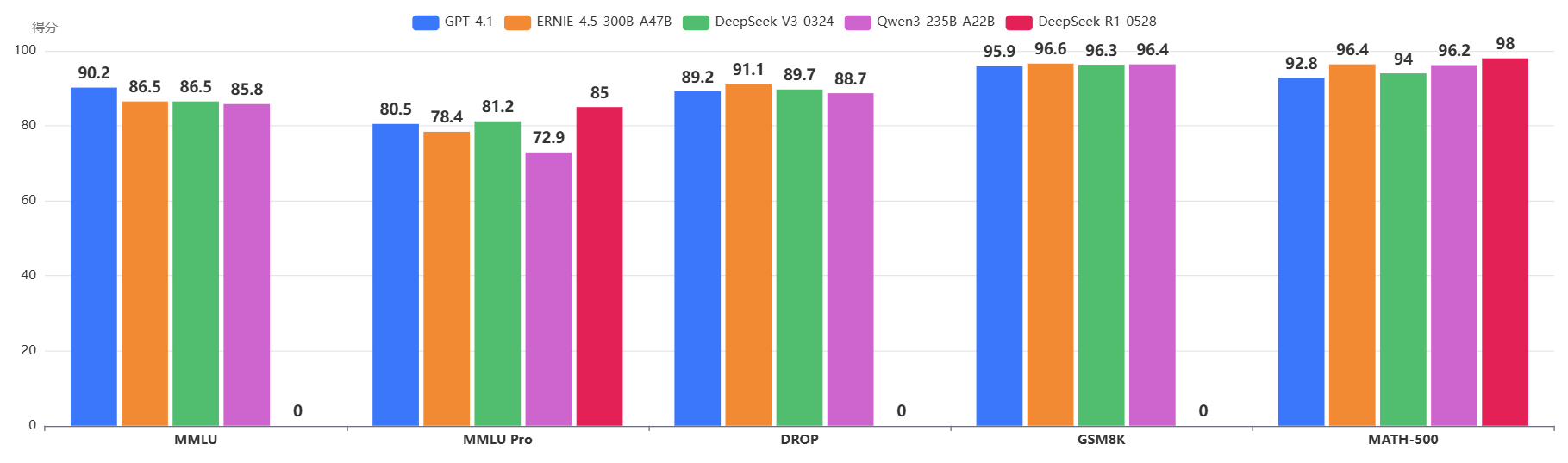
可以看到(橙色的是百度的模型),在传统的GSM8K、DROP、MMLU等评测上,EREINE-4.5模型与当前最强的DeepSeekV3、Qwen相比几乎没有区别,可以说是很好,也可以说是这些评测的区分能力较弱。
ERINE-4.5模型与其它模型在较难的评测任务上的对比
但是,在具有挑战性的新的评测任务上,百度的ERINE-4.5-300B-A45模型则显得有点不太好。

如上图所示,除了SimpleQA外,AIME这种数学难度较高和编程较难的LiveCodeBench,ERINE-4.5-300B-A47B模型表现非常“一般”(是不好)。这里还没有对比能力更强的Gemini 2.5 Pro和Claude4系列。
即使参数量的对比上,百度的模型其实要高于Qwen3的,但是性能表现似乎一般。
多模态模型(VLM)性能对比
ERNIE 4.5 的视觉语言模型包含了“思考”与“非思考”双模式。而这一点是多模态模型独有的能力(非常奇怪为什么文本模型没有),官方给出了能力测试结果。
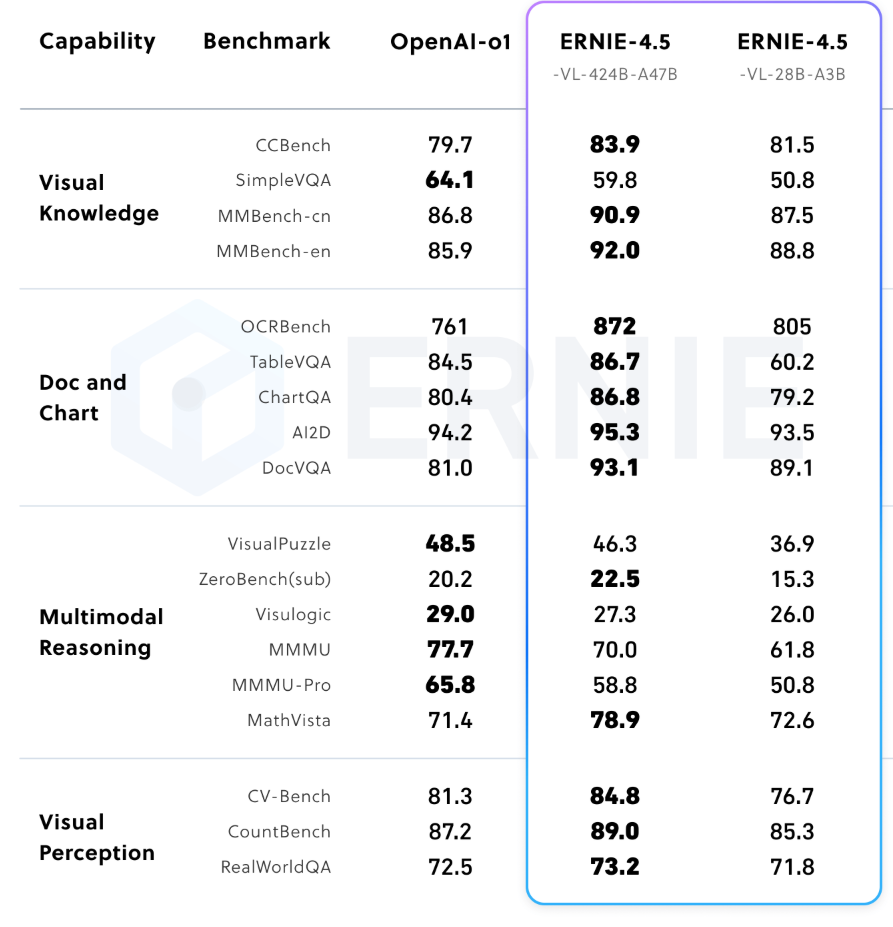
图1:ERNIE 4.5-VL 在非思考模式下的多模态基准表现
看起来似乎是可以的。
ERNIE 4.5的核心亮点总结:异构架构与全栈赋能
ERNIE 4.5 的发布,并非简单的参数扩展,而是在模型架构、训练效率和应用落地层面实现了三大关键创新,共同构成了其强大的核心竞争力。
创新一:多模态异构MoE预训练
传统的多模态模型在联合训练时,常常面临不同模态间信息“干扰”或“妥协”的挑战。为解决这一难题,ERNIE 4.5 独创性地设计了异构MoE架构。该架构的核心思想是,既允许不同模态(如文本和视觉)共享一部分参数以促进跨模态理解,又为每个模态保留了专用的专家网络。
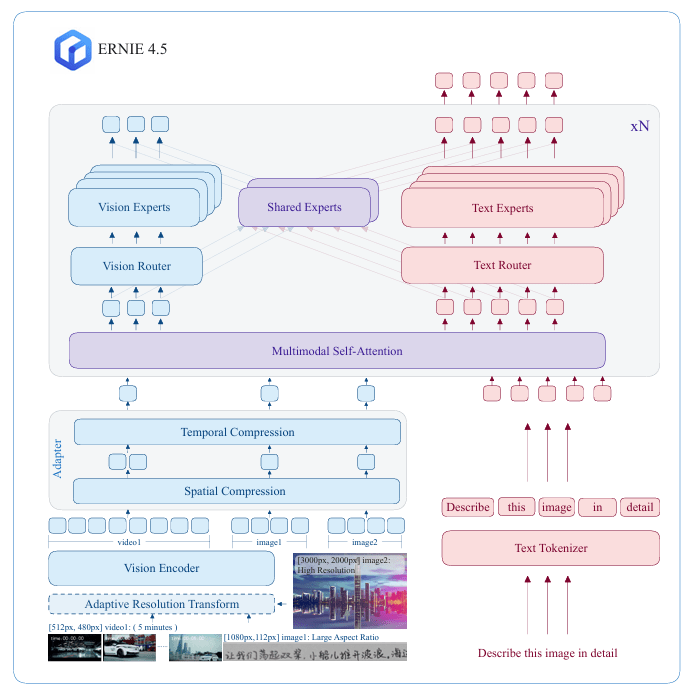
为了实现高效的协同训练,模型引入了模态隔离路由(modality-isolated routing)、路由器正交损失(router orthogonal loss) 和多模态令牌均衡损失(multimodal token-balanced loss) 等多种机制。这些精巧的设计确保了文本和视觉信息在训练过程中能够相互促进,而非相互掣肘,最终实现了1+1>2的多模态融合效果。
创新二:极致扩展的训练与推理效率
大模型的训练和部署成本是业界关注的焦点。ERNIE 4.5 基于飞桨(PaddlePaddle)深度学习框架,构建了一套极致高效的基础设施。在训练端,通过创新的异构混合并行策略、内存高效的流水线调度、FP8混合精度训练等技术,其最大规模模型的训练吞吐(MFU)达到了惊人的47%。
在推理端,ERNIE 4.5 同样表现出色。它支持 4-bit/2-bit 无损量化,并引入了多专家并行协作、动态角色切换的PD解耦(PD disaggregation)等先进技术,在保证模型性能的同时,大幅降低了部署门槛和运行成本。
创新三:面向应用的模态专属后训练
为了满足真实世界的多样化需求,ERNIE 4.5 对预训练后的基础模型进行了精细的模态专属后训练。
- 语言模型(LLMs): 专注于通用语言理解与生成任务,通过监督微调(SFT)、直接偏好优化(DPO)等技术进行对齐,使其在指令遵循和知识问答方面表现卓越。
- 视觉语言模型(VLMs): 重点强化视觉语言理解能力,并创新性地支持**“思考模式(thinking mode)”和“非思考模式(non-thinking mode)”**。非思考模式擅长快速的视觉感知,而思考模式则能在处理复杂推理任务时表现更佳。
ERINE-4.5模型的总结与展望
虽然ERINE-4.5模型的评测很难简单的说不行,但是百度全面开放的态度还是非常值得欢迎的。也希望过程模型可以更好更强。
附录:百度开源的23个模型总结
这23个模型总结如下:
