OpenAI开源2个全新大模型,比肩o3-mini的GPT-OSS-20B和比肩o4-mini的GPT-120B,完全免费商用授权
在几个小时前,OpenAI开源了两款名为gpt-oss-120b和gpt-oss-20b的大语言模型。这是自GPT-2以来,OpenAI首次推出开源权重大语言模型,这两个模型的评测效果达到了o4-mini和o3-mini的水平,而且以Apache 2.0协议开源,大家可以自由使用,包括任何形式的商用。

GPT-OSS-20B和GPT-OSS-120B2个模型特点与核心能力
GPT-OSS的2个模型在设计上注重推理能力、效率和在不同部署环境中的实用性。这两个模型均在灵活的Apache 2.0许可下发布,并针对消费级硬件进行了优化,使其更易于广泛应用。
- 模型架构与参数:这两个模型都采用了混合专家(Mixture-of-Experts, MoE)的Transformer架构,这种架构可以在处理输入时减少所需激活的参数数量,从而提高效率。
- gpt-oss-120b:拥有1170亿总参数,但在处理每个token时仅激活51亿参数。它包含36个层,每层有128个专家,每次激活4个。该模型可以在单张80GB的GPU上高效运行。
- gpt-oss-20b:拥有210亿总参数,激活36亿参数。它包含24个层,每层有32个专家,同样每次激活4个。该模型内存需求仅为16GB,非常适合设备端应用、本地推理或快速迭代。
- 通用特性:两个模型均使用分组多查询注意力机制(grouped multi-query attention)以提高推理和内存效率,支持高达128k的上下文长度,并使用旋转位置编码(RoPE)。
GPT-OSS两个模型的总结如下:
上下文长度128K,这个不那么好~
OpenAI的官方博客说,这两个模型都采用了OpenAI最先进的预训练技术和后训练技术训练。
训练数据主要为英文文本,侧重于STEM、编码和通用知识领域。后期训练采用了与OpenAI o4-mini类似的流程,包括监督微调(SFT)和高计算量的强化学习(RL)阶段,旨在使模型具备强大的思维链(CoT)推理和工具使用能力。
GPT-OSS-120B和GPT-OSS-20B模型的核心能力
虽然此次开源的模型没有公布更多的训练细节,如训练数据等,但是官方给出了这个模型的高度评价,认为GPT-OSS两个模型都是为了推理和工具使用的能力打造,主要包括:
- 高效推理:模型经过优化,可在消费级硬件上高效部署。
- 强大的工具使用:模型展示了出色的工具使用能力,例如网络搜索或执行Python代码。
- 可定制化:模型完全可定制,提供完整的思维链(CoT)过程,并支持结构化输出。
- 可调节的推理努力:开发者可以通过系统消息中的一句话轻松设置三种推理努力程度(低、中、高),以在延迟和性能之间取得平衡。
可以说,也许这两个模型不是最先进的架构,但是从能力上来说也可以让大家看出OpenAI内部模型训练的强大能力。相比较此前的完全封闭,这2个模型可以完整输出思维链模式,可以设置推理的成本,支持更好的工具使用等,都是业界非常需要的能力。
模型评估结果
OpenAI对gpt-oss模型进行了一系列标准学术基准测试,并将其与包括o3、o3-mini和o4-mini在内的其他OpenAI推理模型进行了比较。
首先,我们先在DataLearnerAI的大模型评测工具对比上对比了这两个模型和Qwen、Kimi的差异:
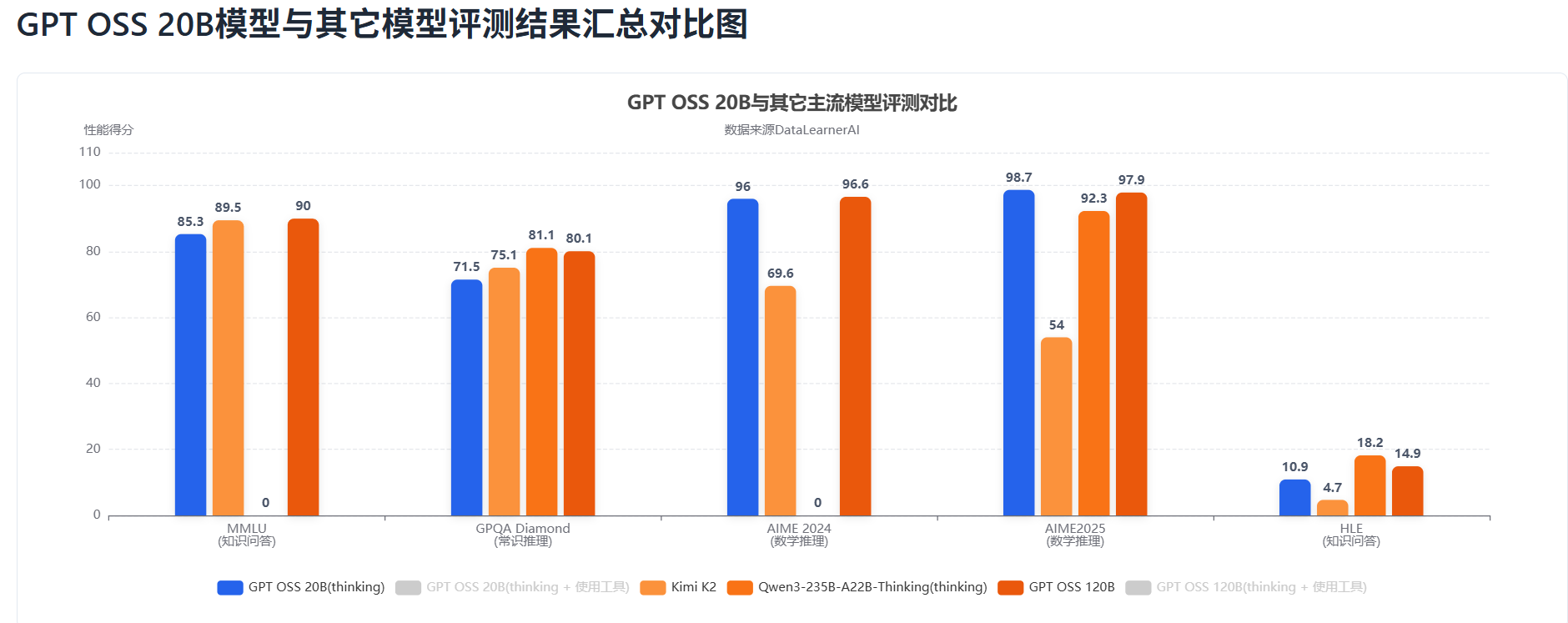
可以看到,单就这几个评测结果来说,GPT-OSS-120B模型的水平和Qwen-235B-A22B-Thinking-2507模型差不多,不过前者参数规模和激活参数规模都只有后者的一半。
此外,下图展示了OpenAI的GPT-OSS模型的其它对比。
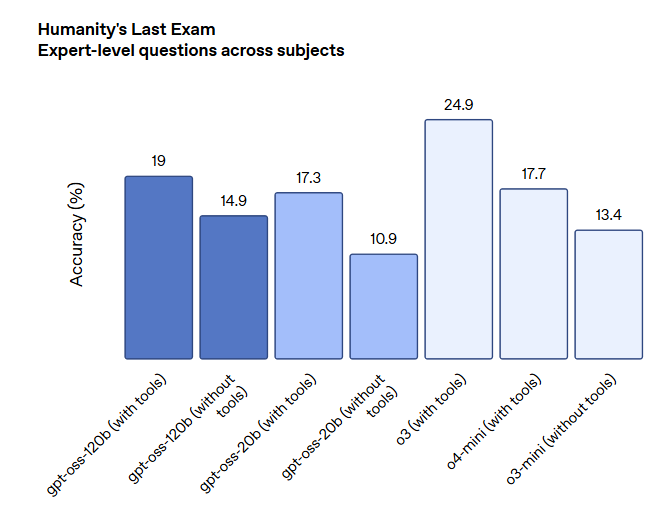
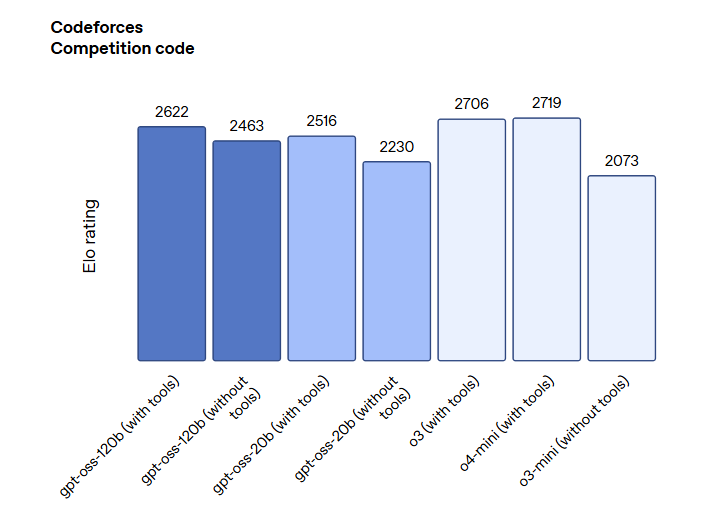
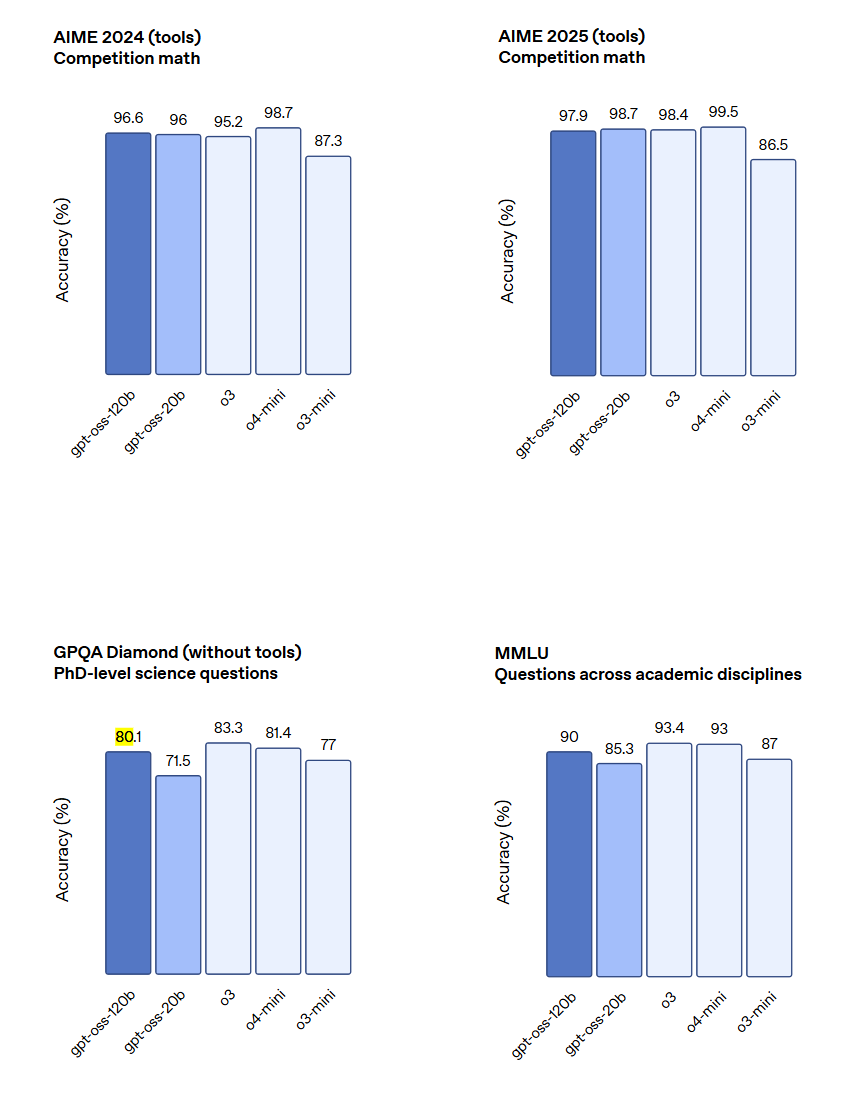
总体来说,这两个开源模型的评测结果都很好,也接近o3 mini和o4 mini水平。
-
gpt-oss-120b表现:在核心推理基准测试中,gpt-oss-120b的表现几乎与OpenAI o4-mini相当。在竞赛编程(Codeforces)、通用问题解决(MMLU)和工具调用(TauBench)方面,其表现优于o3-mini,并达到或超过了o4-mini。特别是在健康相关查询(HealthBench)和竞赛数学(AIME)方面,它的表现甚至超过了包括GPT-4o在内的专有模型。
-
gpt-oss-20b表现:尽管尺寸较小,gpt-oss-20b在上述评估中的表现能够达到或超过o3-mini,在竞赛数学和健康领域的表现同样出色。
需要注意的是,OpenAI说在训练中没有对模型的思维链(CoT)进行任何直接的监督对齐。他们认为这对于监控模型的潜在不当行为、欺骗和滥用至关重要。通过发布具有非监督思维链的开放模型,OpenAI希望为开发者和研究人员提供研究和实施自己CoT监控系统的机会。同时,官方也提醒开发者不应将CoT内容直接展示给用户。
虽然终端用户可能没必要,但是开发者还是挺需要的。
GPT-OSS模型可以在单张显卡上运行,速度很快
此外,根据官方的描述GPT-OSS-120B可以在单张80G显存的硬件上运行(应该是量化),而 GPT-OSS-20B只需要16GB显存的消费级硬件可以运行。
下图展示了NVIDIA硬件运行GPT-OSS模型的速度:
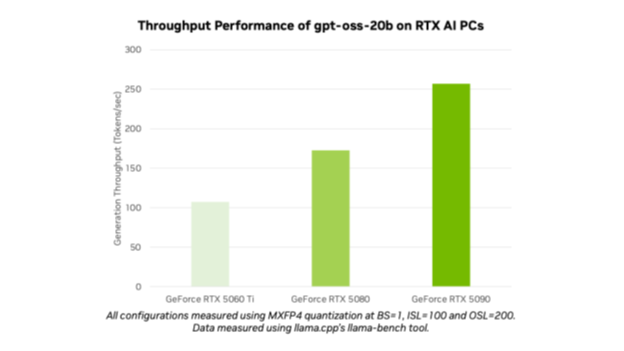
此外,根据英伟达的描述,GPT-OSS-20B模型在5090上可以达到250tokens/秒,而在3090上也可以达到90tokens/秒。非常快!
GPT-OSS模型开源总结
此次gpt-oss模型的发布,对AI开源社区具有重要意义,它不仅提供了性能强大的工具。
自从GPT-2之后,OpenAI再也没有开源任何大模型,也没有公开其模型的技术细节。此次转变极大概率还是DeepSeek R1开源的影响。
关于OpenAI GPT-OSS两个模型的开源地址和其它信息参考: GPT OSS 20B:https://www.datalearner.com/ai-resources/pretrained-models/gpt-oss-20b GPT OSS 120B:https://www.datalearner.com/ai-resources/pretrained-models/gpt-oss-120b
