月之暗面开源了一个全新的160亿参数规模的MoE大语言模型Moonlight-16B:其训练算力仅需业界主流的一半
月之暗面(Moonshot AI)是此前中国大模型企业中非常受关注的一家企业。旗下的Kimi大模型和产品因为强悍的性能、超长的上下文以及非常快速的响应引起了广泛的关注。不过,此前MoonshotAI的策略一直是闭源模型,但是产品免费。也许是受到了DeepSeek的压力,月之暗面在2025年2月23日首次开源了旗下的一个小规模参数的大语言模型Moonlight-16B。
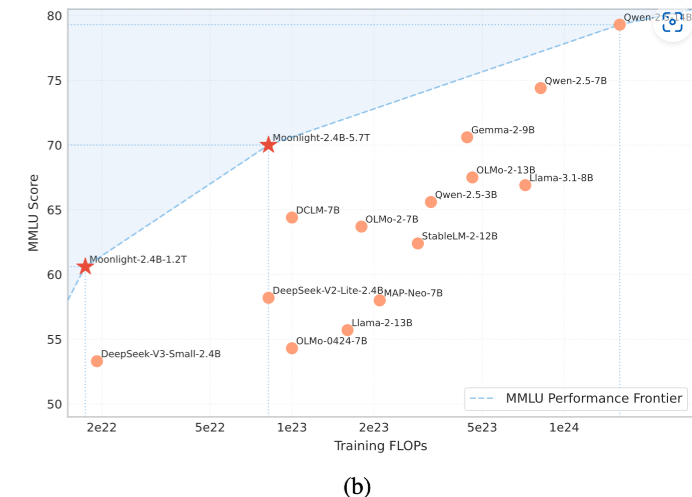
Moonlight-16B模型简介
Moonlight-16B是一个大规模的混合专家(MoE)模型,参数数量160亿。官方开源的模型名字是Moonlight-16B-A3B,因为它是160亿参数的大模型,但是每次推理仅激活其中的24亿参数,所以加了一个A3B,A是激活Activation,3B是24亿的参数。
根据官方开源的模型参数,Moonlight-16B-A3B有64个专家和2个共享专家,每次推理的时候每个token会激活其中6个专家。
Moonlight的另一个关键创新点是其使用了Muon优化器,这是一种基于矩阵正交化的优化算法,能够大大提高训练过程的效率和稳定性。通过结合MoE架构和Muon优化器,Moonlight模型不仅提高了训练效率,还展现了强大的性能。根据官网的数据,Moonlight模型在训练中使用了5.7万亿tokens的训练数据,但是因为使用了Muon优化器,所需的训练计算量比传统方法减少了50%。
Moonlight-16B模型的评测效果
在多个基准测试中,Moonlight-16B模型展现了超越同类模型的表现(与3B规模模型对比):
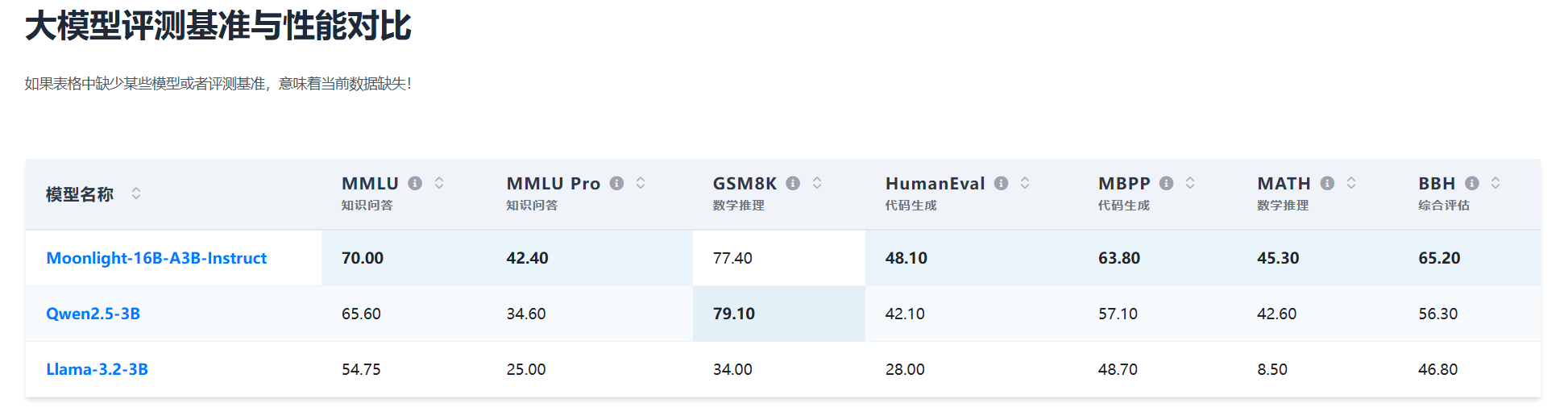
可以看到,与业界同等参数规模的优秀代表Qwen2.5-3B和Llama-3.2-3B对比来看,Moonlight-16B都非常优秀,出了GSM8K略低于Qwen2.5-3B外,其它评测结果都显著高于另外2个模型。
即使和业界70亿参数规模相比,Moonlight-16B模型也展现了不俗的效果:
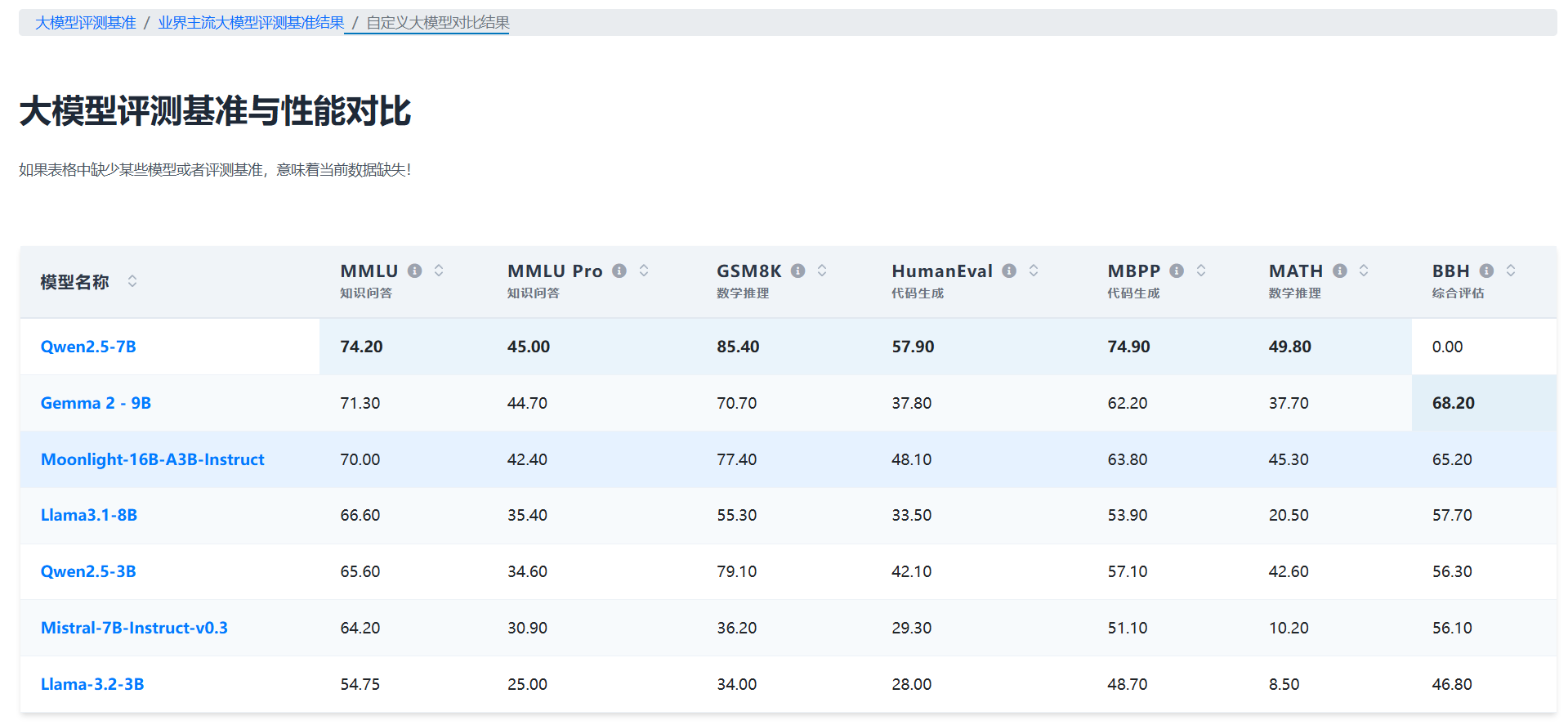
以MMLU Pro为例,非常接近业界的Qwen2.5-7B和Google的Gemma2-9B。
Moonlight-16B-A3B的核心创新是使用Muon优化器
在神经网络训练中,优化器负责调整模型的权重(即神经网络的参数),以使得模型的输出越来越接近预期。AdamW是目前最常用的优化器之一,它通过计算梯度(损失函数对权重的导数)并利用动量来更新权重。
而本次MoonlightAI最大的创新是基于Muon优化器训练得到Moonlight-16B-A3B模型。而Muon的创新之处在于,它不仅仅是利用梯度和动量来更新权重,它还会通过一种叫做“正交化”的技术来“调整”权重更新的方向。通过正交化,Muon确保权重更新不会沿着某些“偏向性”的方向走得太远,避免了某些方向更新过多,导致模型不稳定。
同时,该优化器使得Moonlight-16B-A3B模型的训练成本也大幅降低。
Moonlight-16B模型总结
本次MoonshotAI开源的Moonlight-16B-A3B包含2个版本,一个是基座版本的Moonlight-16B-A3B,一个是Moonlight-16B-A3B-Instruct。MoE的架构使得这个模型的显存占用与160亿参数规模相当,但是推理速度与24亿参数的大模型一致。意味着速度会非常快。
关于Moonlight-16B-A3B的模型详细和评测结果参考DataLearnerAI的模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/Moonlight-16B-A3B-Instruct
也许是因为迫于DeepSeek开源之后带来的压力,传闻月之暗面最近也减少了市场推广的投放,而首次开源大模型,极力宣传他们技术的创新可能也意味着一些方向的改变。但不管怎么说,对于开源大模型来说,中国企业似乎显得比美国企业Open的多!
