Kimi开源K2大模型:全球首个开源可商用的1万亿参数规模大模型,MoE架构,评测结果与DeepSeekV3相当,但模型文件有1TB!
2025年7月12日,Moonshot AI开源了Kimi K2大模型,这个模型是MoE架构(混合专家架构)拥有1万亿参数规模,大概是当前业界最大参数规模的大模型了。Kimi K2首次将开放Agentic Intelligence(自主代理智能)与强大工具调用能力有机整合。它不仅在知识推理、数学、代码等传统“非思维模型”任务上展现出全球领先的能力,还特别针对一系列实际Agentic(自动决策与操作型)任务进行了深度优化。可以说,Kimi K2是专为AI Agent打造的一个大模型。

Kimi K2的核心亮点:超大规模参数与开放Agentic
Kimi K2定位为开放Agentic智能的通用基础模型,Moonshot AI认为这是多专家模型与大规模自主智能领域的最新结合的突破。与众多同类模型相比,K2围绕“高性能Agentic任务能力”、“开箱即用的工具适应性”和“广泛领域的卓越泛化”进行了全面升级。
Kimi K2主要有以下几个核心亮点:
- 超大规模专家混合架构:拥有总参数量1万亿,激活参数达320亿,在全球开源领域属顶级规模。此前,虽然有PanGu-Σ、GLaM等模型号称有1万亿参数,但都没有开源,且几乎没有商用。相对较大参数规模并开源的模型应该是DeepSeek V3和DeepSeek R1,参数规模6710亿。不过,这个模型输出仅支持128K的上下文。
- 极致Agentic任务表现:针对自动化操作、工具调用等Agent应用场景进行专项强化,实现“会思考也会动手”。这一点在后面的评测也可以看到,Kimi K2在任务规划、工具使用方面都表现非常好,几乎达到了全球最好的一类水平。
- 两种开源版本:
- Kimi-K2-Base:完全基础模型,便于研究者和开发者进行自定义微调与二次开发。
- Kimi-K2-Instruct:经过指令微调,更适合通用对话与Agent任务的即用式应用。
- 无需复杂流程的AutoTool调用能力:只需描述工具与任务,模型即可自动推理、操作、输出结果,无需人工编写复杂Agent角色或工作流。这一点也是非常值得期待,在当前AI Agent应用中,由于模型本身能力的限制,需要对接口进行详细的描述,并通过某种方式告诉模型工具的使用流程,否则Agent效果很差。而Kimi这个特性似乎是使用了大量的接口数据告诉模型,我们正常的系统可能从哪些角度使用什么工具流程完成任务,进而可以让模型在新的场景下有更好的泛化能力。
- 全面开放:官方已对外开源,使用的是一个修改版本的MIT开源协议,相比较原版完全开发自由商用的协议,修改版只加了一个义务要求,即如果你的产品月活超过1亿用户,或者月收入大于2000万美元,那么需要在用户界面上显著标识『Kimi K2』。
可以说,不管是技术能力还是开源协议方面,本次Kimi K2的开源都是很有诚意。不过1万亿参数规模,1.01TB的模型文件,一般人或者机构几乎很难用的起来。
Kimi K2的核心技术是一个多Agentic任务训练体系
从官方的给的内容来看,Kimi K2的重点就是称为AI Agent系统中的核心控制器,在工具使用等Agent场景中做了大量的优化。在技术实现上,Kimi K2围绕“自主Agent能力”进行了一系列创新,涵盖预训练、优化器改进、Agentic数据生成与强化学习等多条技术路线。其中,最核心的是大规模的agentic数据合成和强化学习的突破。
Kimi K2大规模的agentic数据合成流程
为了让模型学会如何使用工具,Kimi团队构建了一套大规模agentic数据合成流程,这个思路来源于ACEBench,核心思想是大范围模拟现实场景中的工具使用情况,团队共演进了几百个不同领域,每个领域可能都包含几千个工具(包含真实的MCP工具和合成工具),然后生成几百个拥有不同工具集的Agents,这里几百个不同工具集的Agents应该就是前面所说的Agent角色了。

Agentic数据合成的过程是Agent与模拟环境和用户代理交互,创建逼真的多轮工具使用场景。再使用大模型根据任务准则评估模拟结果,筛选出高质量的训练数据。这个可扩展的流程可以生成多样化的高质量数据,为大规模拒绝采样和强化学习奠定基础。
Kimi K2的强化学习
当然,最后的强化学习阶段也很重要,Kimi团队认为通用强化学习的关键挑战在于将强化学习应用于具有可验证和不可验证奖励的任务;可验证任务的典型示例是数学和竞赛编程,而撰写研究报告通常被视为不可验证的任务。为此,团队做了很多不仅针对可验证奖励(如数学、竞赛代码)训练,还实现了模型自评(self-judging)等机制,有效解决“不可验证奖励”场景下训练难题。
Kimi K2的性能测试结果:Agentic能力表现不错,好于DeepSeek V3-0324,但与推理模型有差距
Kimi K2在国际主流基准测试中,表现不错。总体结果看,与非推理模型中最好的一类,如DeepSeek V3-0324、GPT-4.1相比,结果都很好。不过,与顶尖的推理模型相比,如Claude 4 Opus、Gemini 2.5 Pro、Grok4相比,那结果就不够亮眼了。不过,考虑到这个模型每次推理只激活320亿参数,也就是说理论上相当于32B模型,且没有深度思考的能力,这个结果还是不错的。
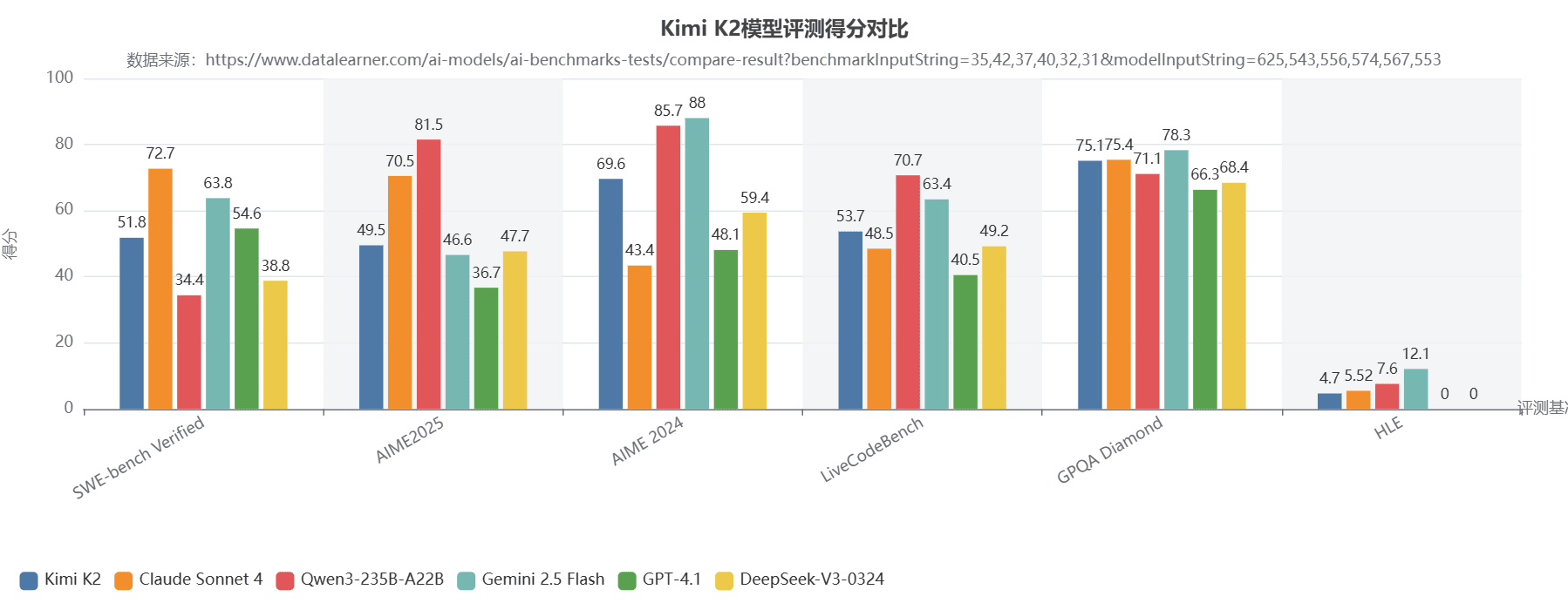
这几类评测是当前比较主流的评测结果,与Claude 4 Sonnet相比,Kimi K2在SWE-Bench Verified、AIME2025和HLE上表现不足,但是在AIME2024和LiveCodeBench上更好。与DeepSeek V3-0324和GPT-4.1等非推理模型相比,Kimi K2都不错,基本上都更好。唯一可惜的是,在人类最后的难题HLE上,Kimi K2比较差。
与阿里Qwen3最强的模型Qwen3-235B-A22B相比,Kimi K2评测似乎不敌。
不过,这里列举的是主流的大家知道比较多的测试,还有一些工具使用、Math & STEM之类的评测结果,Kimi K2表现是可以的(官网的数据与DataLearnerAI的数据有差异,原因是Kimi K2官网对比的都是非thinking模式)。总之,评测的维度和角度很多,算是一个参考吧。具体官方的数据大家可以参考DataLearnerAI的模型信息卡,里面有官方博客地址:https://www.datalearner.com/ai-models/pretrained-models/kimi-k2-0711-base-preview
官方实例和实测结果
Kimi K2的Agentic能力在真实场景中的应用体验极为突出,无需编写复杂工作流,模型即可自动适配工具、理解任务、完成目标。
以官方“远程办公薪资分析”场景为例,用户仅需输入任务描述及数据,Kimi K2便可自动理解表结构、编写分组统计、绘制可视化图表,并生成全流程交互式分析网页:
- 自动数据解析与分组:模型能自动发现表头、识别数据类型,并按照用户的分析需求(如远程程度、工作年限等)灵活分组。
- 多步统计检验:自动调用Scipy或等效工具,完成双因素方差分析(ANOVA)、t检验、均值统计等步骤,输出严谨的显著性分析结论。
- 智能可视化:自动生成小提琴图、箱型图、条形图、交互式折线等,配色美观(支持muted pastel等高级图表配色)。
- 交互式推荐模拟器:用户输入个人职业信息后,模型可实时计算远程/现场办公收益变化,并给出可视化推荐。

DataLearnerAI对Kimi K2的一个实测
这种端到端智能代理模式,极大地缩短了生产力应用的开发周期——不用设计繁琐的Agent角色,也无需手动工具TF调用,任何人只需一段任务描述即可完成从分析、到推理、到落地交互的全流程。
为了验证这个效果,我们也丢给了Kimi K2一份DataLearnerAI的数据:
- 模型列表:来源DataLearnerAI的模型列表页面,当前包含了约600个模型的数据,https://www.datalearner.com/ai-models/pretrained-models,我们直接copy了网页的列表源码,大约300K的tokens。
- 部分模型评测结果:https://www.datalearner.com/ai-models/ai-benchmarks-tests/benchmarks-for-all
让其进行分析并画图,不过第一步出现了问题,我们的模型列表源码300K左右,Kimi K2最多仅支持128K输入,导致超限。所以我们用Gemini 2.5 Flash Lite模型提取了HTML,变为一个纯粹的txt格式,最终大概是49K,然后让Kimi K2分析了的大模型的趋势洞察。
也就是说,最终Kimi K2给了我4个图,怎么说呢,有点浅薄简单了~
我们也顺便测试了Gemini 2.5 Pro,当然,这个测试前2个都是一样的prompt,只是Gemini想把所有模型列出来,我们最后加了第三个prompt,让它不要这样做,结果很不错:
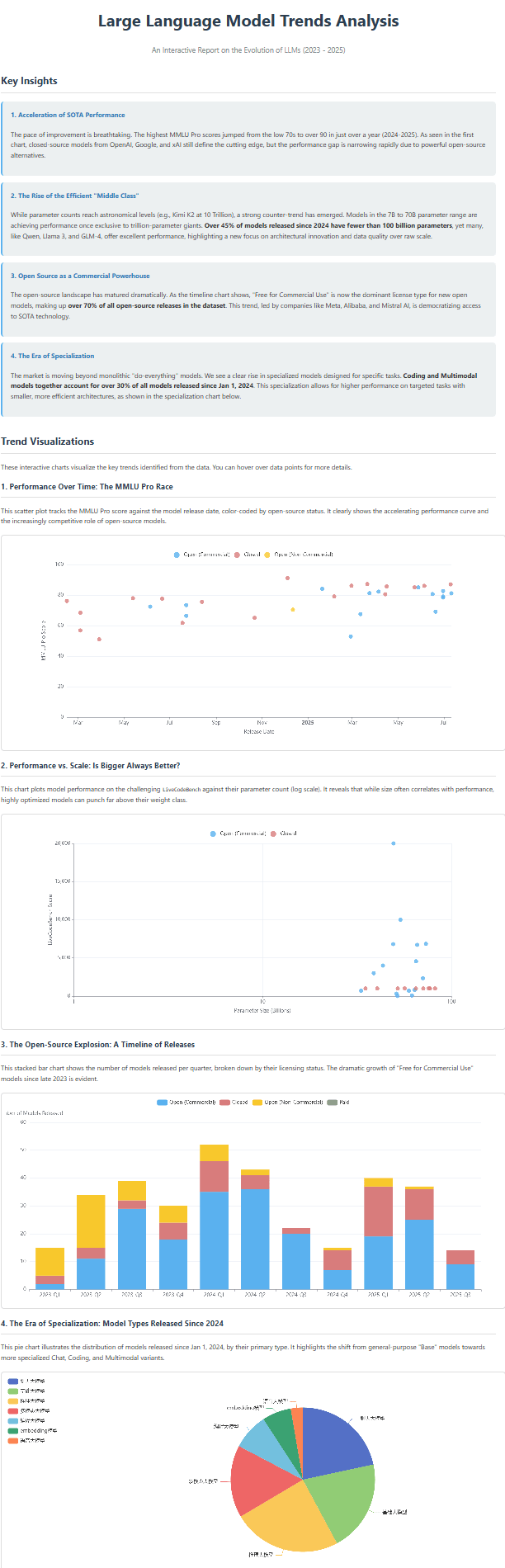
我们也把这部分源代码放到了DataLearnerAI上:https://www.datalearner.com/resources/llm_examples/gemini-analyze-models-example.html 大家参考。
Kimi K2的开源情况和价格
Kimi K2开源了2个版本,分别是基座版本和指令优化版本,两个版本都是修改版本的MIT开源协议。目前官网的网页可以免费使用,而价格方面,Kimi K2很便宜,输入是100万tokens要4块钱,输出是16块钱,单位是人民币。
其实从官网看,Kimi K2并不是顶级的推理模型的对手。但是Kimi的思路也很简单,就是要成为AI Agent的强大基座,所以在自动任务执行、工具规划,工具使用等方面发力。当然,官方也说,未来版本将在“模型思考”(planning)与“多模态能力”方向持续升级,例如更强的自主推理和视觉理解。
官方也提到,当前Kimi K2需注意的局限包括:
- 高难度推理任务、工具描述不清场景下有可能生成冗余token或输出部分中断;
- 工具调用模式下,部分类别任务性能下降;
- 一次性长任务场景,链式Agent框架弱于反复执行模式。
关于Kimi K2更多的信息参考DataLearnerAI模型信息卡:https://www.datalearner.com/ai-models/pretrained-models/kimi-k2-0711-base-preview
