2026年5月份 AI Agent 产品中的记忆设计与工程实践
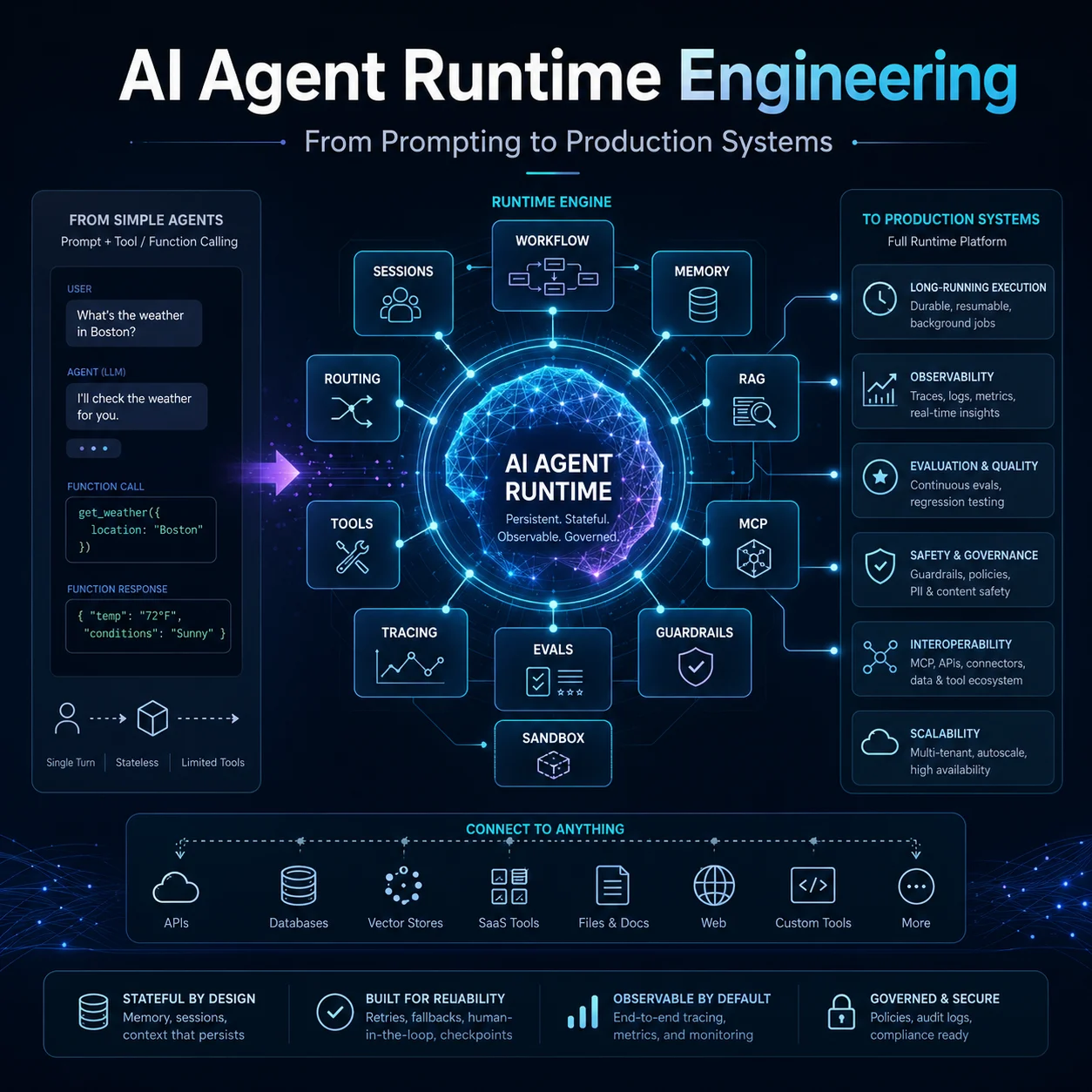
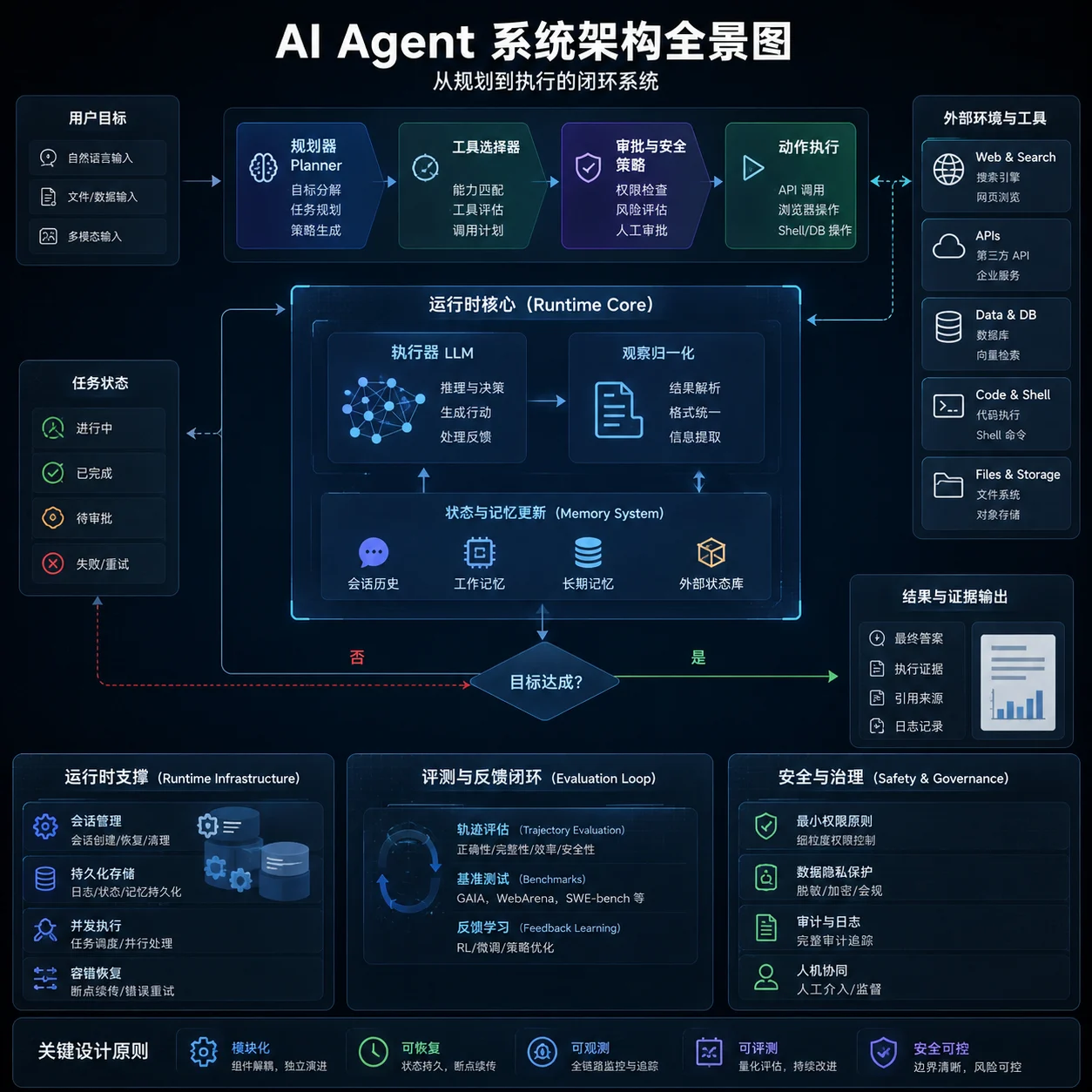
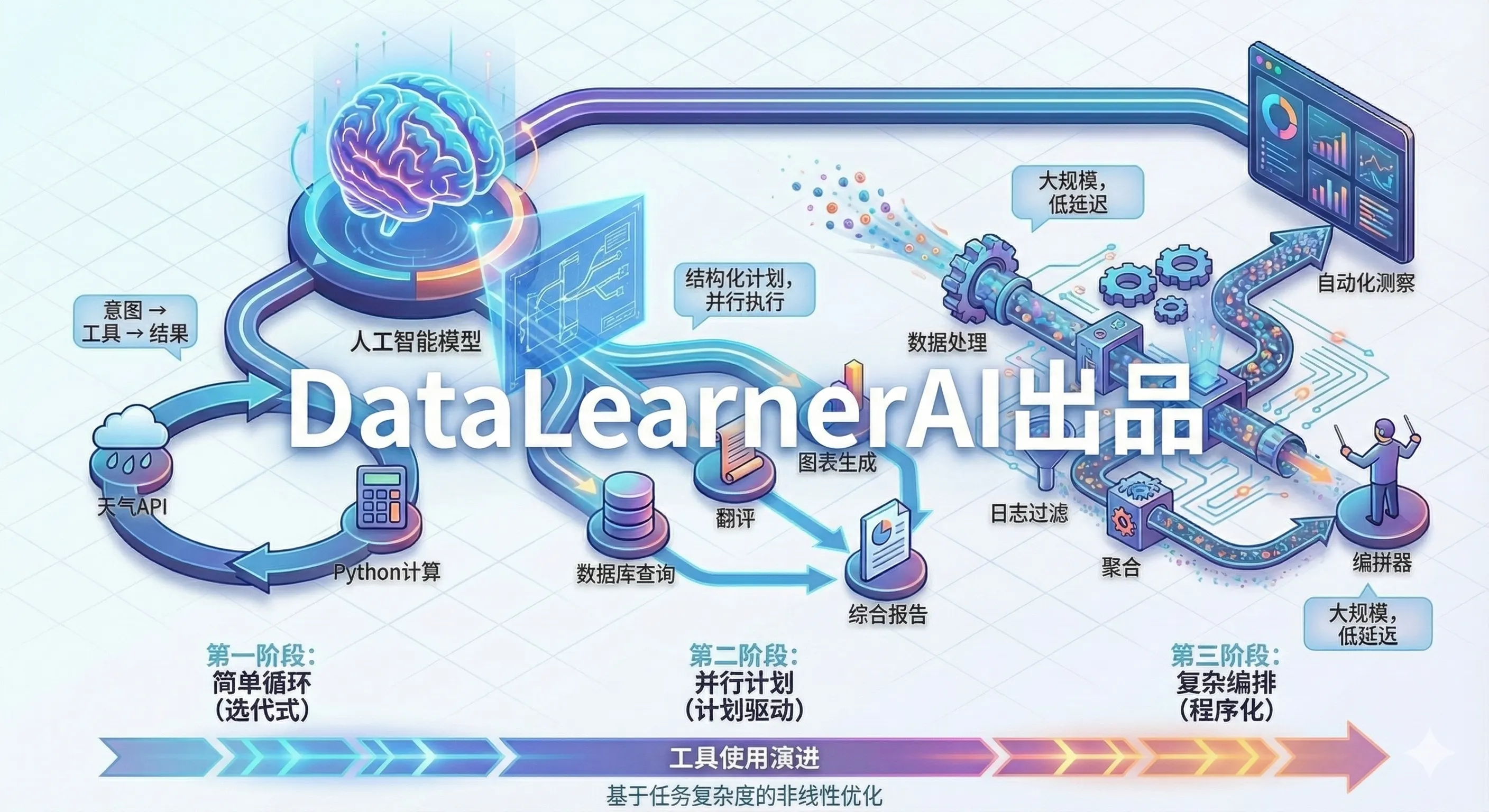
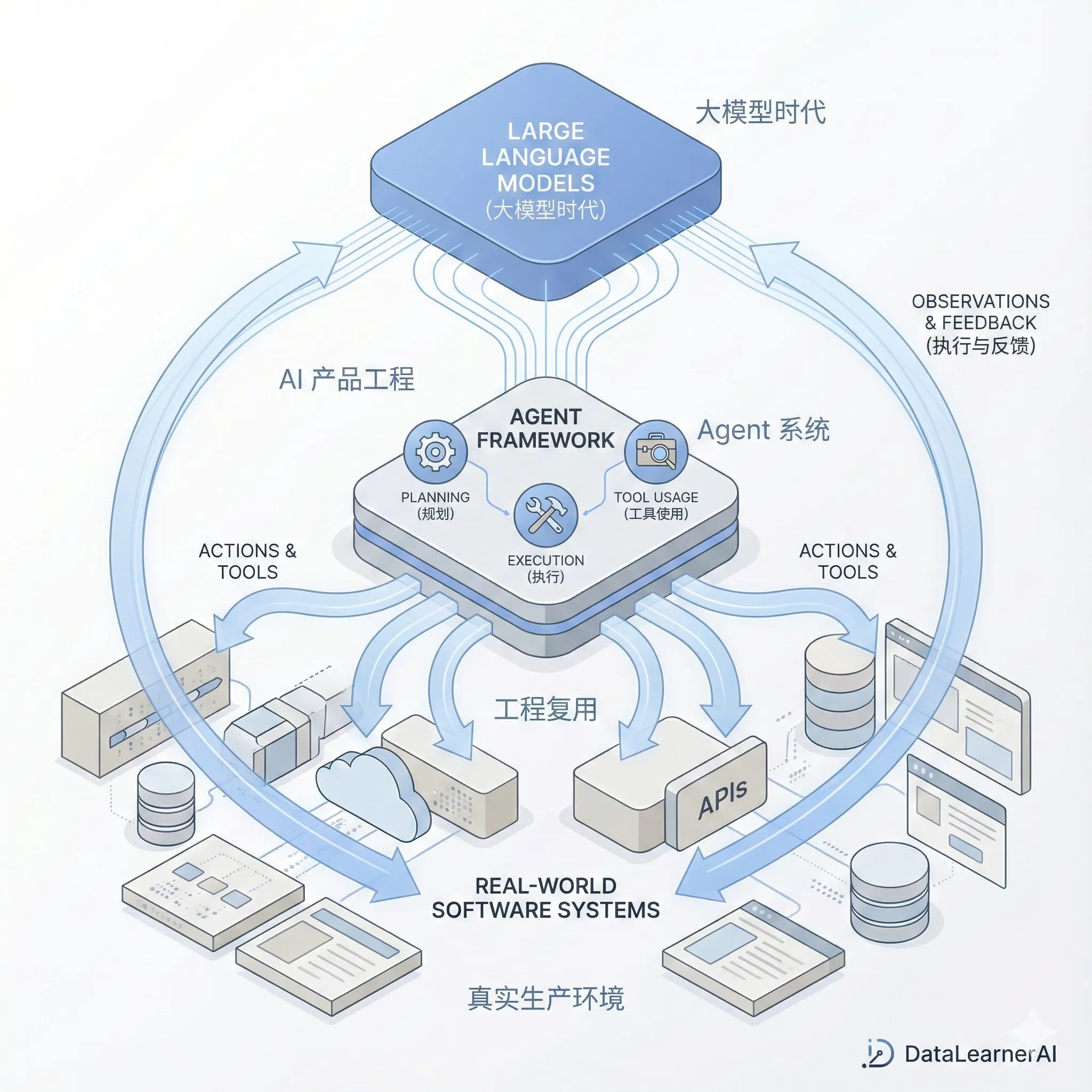
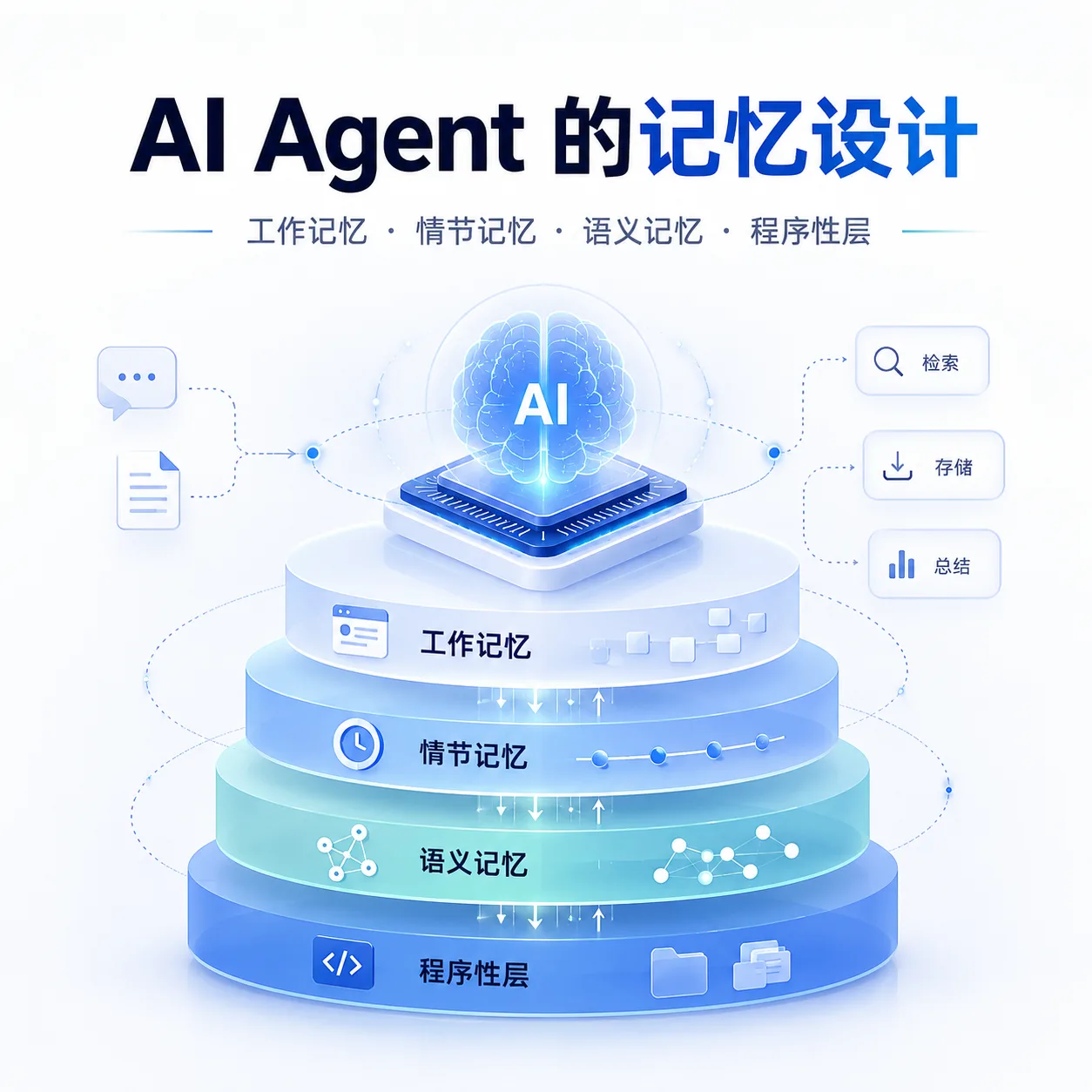
过去一年里,AI Agent 的“记忆”设计明显从“把更多历史塞进上下文窗口”转向了更工程化的多层体系:把当前上下文当作**工作记忆**,把会话记录、屏幕轨迹、日志等当作**情节记忆**,把稳定偏好、约定、知识摘要当作**语义记忆**,再把规则、技能、流程模板当作一种接近平行“程序性记忆”的外化层。Anthropic、OpenAI、OpenClaw、Hermes、Cursor 等产品虽然界面不同,但其核心都在解决同一个问题:如何在**有限上下文、可接受延迟、可控成本**下,为 agent 提供持续、一致、