MistralAI开源全球首个(可能)基于MoE(Mixture of Experts)技术的大模型:预训练下载链接全球直发,但实测表现似乎一般!
MistralAI是一家法国的大模型初创企业,其2023年9月份发布的Mistral-7B模型声称是70亿参数规模模型中最强大的模型,并且由于其商用友好的开源协议,吸引了很多的关注。在昨晚,MistralAI突然在推特上公布了一个磁力下载链接,而下载之后大家发现这是一个基于混合专家的大模型这是由8个70亿参数规模专家网络组成的混合模型(Mixture of Experts,MoE,混合专家网络)。

而这也可能是目前全球首个基于MoE架构开源的大语言模型(如果有漏掉,欢迎补充~)。另外,Mistral-8x7B-MoE已经上架DataLearnerAI模型信息卡,欢迎关注后续的开源地址和技术报告分析:https://www.datalearner.com/ai-models/pretrained-models/Mistral-7B-MoE
混合专家网络(Mixture of Experts,MoE)简介
混合专家网络(MoE,Mixture of Experts)是一种大型深度学习模型的设计方法,旨在提高模型的规模和效率。这种方法的核心是将大型网络划分为多个较小的子网络(称为“专家”),然后根据输入数据的特性选择性地激活这些专家。
在此前的一则GPT-4技术泄密中,有传闻,GPT-4就是一个包含了16个专家网络的MoE大模型,其中每个网络是一个1100亿参数的大模型,组合之后是一个1.8万亿参数左右的超级大模型(详情参考:未经证实的GPT-4技术细节,关于GPT-4的参数数量、架构、基础设施、训练数据集、成本等信息泄露,仅供参考)。
在MoE模型中,有两个关键组件:
-
专家(Experts):这些是网络中的小型子网络,每个专家通常专注于处理一种特定类型的数据或任务。专家的设计可以是多种形式,如完全连接的网络、卷积网络等。
-
门控机制(Gating Mechanism):这是一个智能路由系统,负责决定哪些专家应该被激活来处理当前的输入数据。门控机制基于输入数据的特性,动态地将数据分配给不同的专家。
混合专家模型的主要优势在于用较低的成本实现一个更大规模的模型,可以实现更高的性能(因为每个专家网络可以针对特定数据优化,推理的时候可以只激活一个或者多个专家网络,因此可以通过较低的成本获得更好的性能)。而此次MistralAI发布的8个专家网络混合的大模型可能会突破现有很多模型的想象,值得期待非常优秀的性能。
Mistral-8x7B-MoE简介
MistralAI目前没有公布Mistral-7B-MoE这个模型的其它细节,而根据公布的磁力下载链接中的文件夹名称,这个模型目前也被称为mixtral-8x7b-32kseqlen。
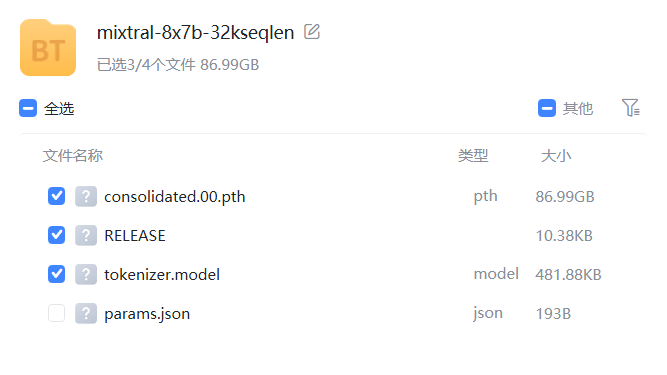
从上图可以看到,这个模型的预训练结果大小为86.99GB,这意味着单个专家网络大小在10.9GB左右,比此前开源的Mistral-7B(Mistral-7B模型信息卡地址:https://www.datalearner.com/ai-models/pretrained-models/Mistral-7B )小不少(Mistral-7B模型为15GB左右)。
而这个模型参数的具体配置如下:
从这个配置结果看,这个模型是8个专家混合而成,而输入的时候每个token分给2个专家处理。注意,这个模型的词汇表大小是32000,与LLaMA2模型是一样的。
而模型配置说维度是4096,但是文件夹命名是32k序列长度,应该是单个专家网络4K,8个一起可以处理32K输入!
目前,除了这些参数外,官方没有公布技术文档或者博客介绍,但是吸引了大量的关注和讨论,着实是一个营销的好案例。
Mistral-7B-MoE(mixtral-8x7b-32kseqlen)实际评测
尽管Mistral AI目前没有给出除了模型下载链接外的任何信息,但是这个模型吸引了社区的大量注意。因为这可能是目前已知的全球首个完整的基于MoE架构的大语言模型。因此,已经有很多人开始测试了。
FireworksAI已经上架mixtral-8x7b-32kseqlen
目前动作比较快的是Fireworks AI平台,已经上架了这个模型,速度非常快:

可以看到,这个模型的首字生成时间不到1秒,而后续平均每个tokens的生成速度在20-30ms左右!当然,这不排除是Fireworks优化的结果。但是如果一个560亿参数的模型可以在MoE技术加持下达到这个速度那真的很恐怖。
mixtral-8x7b-32kseqlen实际问答测试结果
另外,还有人测试了这个模型的效果,但可惜似乎很一般。
首先是问答结果:


看起来结果很差,但是有人认为这是基座大模型,不是针对聊天和指令调优的结果,只能预测下一个tokens,所以显得不好。于是有人测试将问答重新组织得到如下回答(还是上面的香蕉为什么是弯的问题):

可以看到,效果好很多。这是将前面的问题变成如下形式提问:
Practical examples for Biology teachers.
Student: Can you explain to me why bananas are curved?
Teacher:
mixtral-8x7b-32kseqlen的评测结果
而另一个老兄已经直接测试了mixtral-8x7b-32kseqlen在代码上面的能力(测试了HumanEval),结果是33.54%,比此前的Mistral-7B的30.5%好一点点!而其它用户的其它评测基准表现也是只比Mistral-7B好10-20%左右,提升十分有限,非常奇怪!

对比如下:
可以看到,结果好像提升很有限,甚至在TruthfulQA MC2有所下降!真的很奇怪!
Mistral-8x7B-MoE运行的资源
最后总结一下网友运行这个模型的资源。按照目前的测试,需要最少95GB显存以上才可以运行这个模型。因此,2个A100-80G的显卡可以运行,或者4个A40显卡也可以。实测结果显存占用95GB左右!
Mistral-8x7B-MoE已经上架DataLearnerAI模型信息卡,欢迎关注后续的开源地址和技术报告分析:https://www.datalearner.com/ai-models/pretrained-models/Mistral-7B-MoE
关于Mistral-8x7B-MoE的其它信息目前还没有看到,期待官方给出技术细节~
