支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3
尽管大语言模型发展速度很快,但是大多数模型对于上下文长度的支持都非常有限。长上下文对于很多任务来说都十分重要。如文档生成、多轮对话、代码生成等任务都需要较长的上下文输入才能取得较好的效果。

目前开源领域已经有一些模型宣称支持了8K甚至是更长的上下文。那么这些模型在长上下文的支持上表现到底如何?最近LM-SYS发布了LongChat-7B和LangChat-13B模型,最高支持16K的上下文输入。为了评估这两个模型在长上下文的表现,他们对很多模型在长上下文的表现做了评测,让我们看看这些模型的表现到底怎么样。
支持超长上下文对大语言模型(LLM)意味着什么
所谓LLM的上下文长度其实就是LLM背后模型的输入长度。大多数大语言模型的输入长度都在2K以内。以输入长度是2048为例。这个长度的含义是模型一次性接受输入的tokens数量为2048个。根据OpenAI官方的介绍,一般tokens换算到单词的比例是75%左右,这意味着2K模型的输入一般只能支持2048*0.75=1500个单词的输入(关于为什么LLM输入是token而不是单词可以参考:https://www.datalearner.com/blog/1051671195034710 )。
尽管对于大多数任务来说,1500个单词的输入是足够的,但是如果需要对文档进行理解、支持多轮对话、代码理解和生成这些任务来说,更长的输入是必要的。而目前,超过2K的大模型并不多。
LLM对上下文长度输入的限制主要原因在于过长的输入会使模型的资源使用急剧扩大,而过长的训练数据也可能因为关联问题带来质量的下降。因此,对于超长上下文的支持都会限制在一定范围内。但是,目前业界已经有一些支持超长输入的LLM,最高的已经达到100K。
支持超长上下文长度的大语言模型(LLM)总结
这里定义的支持超长上下文长度的LLM是指支持超过2K输入的LLM。原因是大多数模型都能达到2K输入,而且开源LLM的领头羊LLaMA的输入限制就是2048。因此,我们这里只关注超出这个结果的LLM。
下表是DataLearner官方总结的支持超过2k输入的LLM列表:
其中
- MPT是MosaciML开源的大模型,自己重新训练得到
- ChatGLM2-6B是清华大学THUDM开源的6B规模的聊天大模型,基于清华大学自己的GLM模型微调
- XGen是Salesforce在6月30日发布的,目前包含3个,分别是XGen-7B-4K-base、XGen-7B-8K-base和XGen-7B-8K-inst,前两个免费商用授权,最后一个不可商用:https://www.datalearner.com/blog/1051688055743803
- OpenChat-8192是2023年7月2日刚发布的基于LLaMA-13B微调后拓展上下文长度以支持8K输入的大模型
- LongChat是由LM-SYS自己发布的支持长输入的大模型
可以看到,超过2K输入的模型并不多(如果你知道其它的也欢迎留言)。而这其中开源且可以免费商用的只有MPT-7B-storywriter和XGen 7B系列中的2个。
各个模型在超长上下文的表现
LM-SYS是著名开源大语言模型Vicuna系列背后的组织,也是前面LongChat模型的发布者。LM-SYS推出的大语言模型匿名评测(Chatbot Arena Leaderboard)受到了广泛的关注。
因此,针对此次超长上下文模型的发布,LM-SYS在官方也公布了他们对这些模型的评测结果。由于XGen 7B与OpenChat-8192发布比较晚,本次评测没有包含。
本次评测包含2个任务,结果如下:
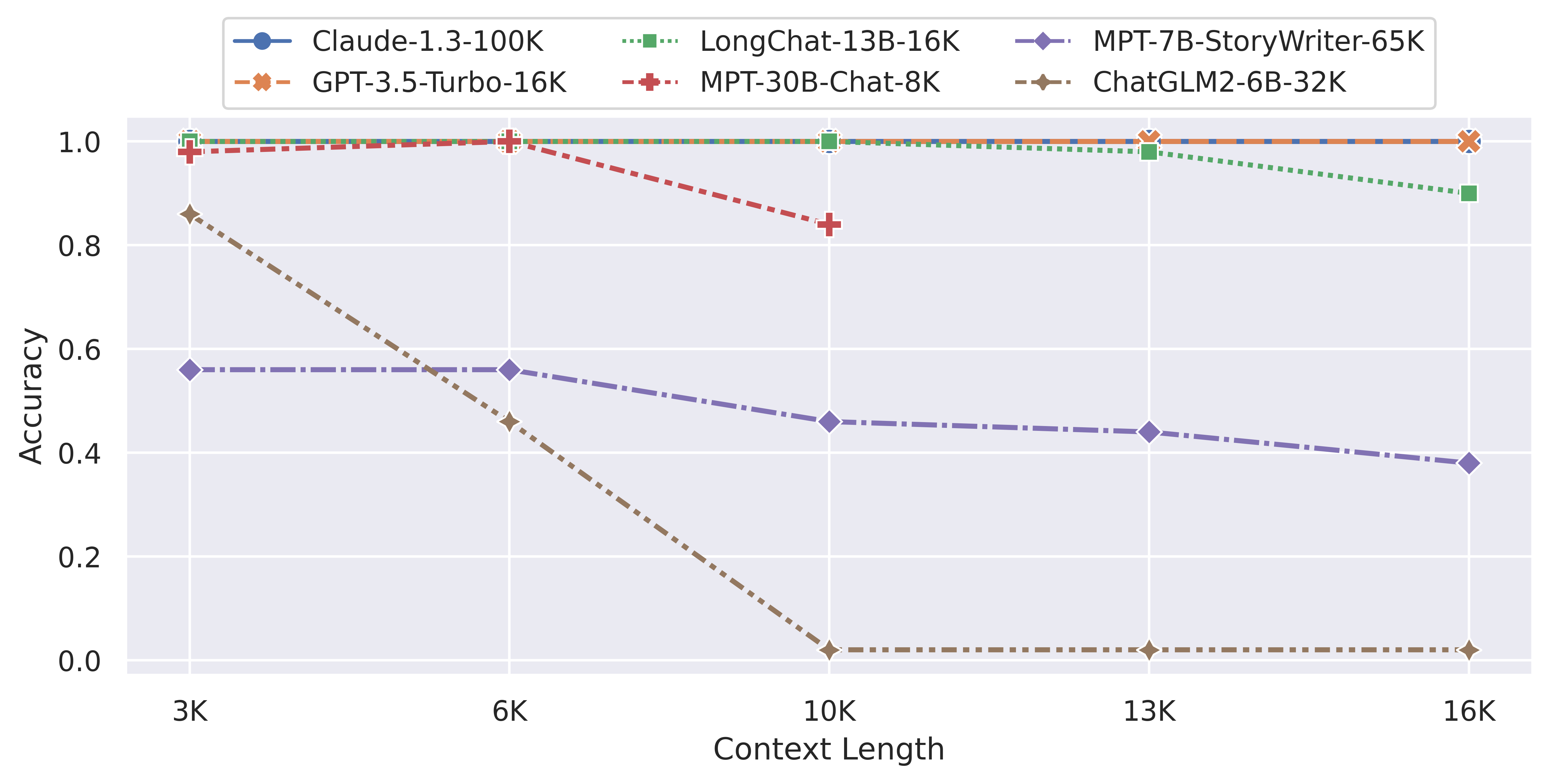
下图是超长主题检索评测结果总结:
下图是超长行检索评测结果总结:
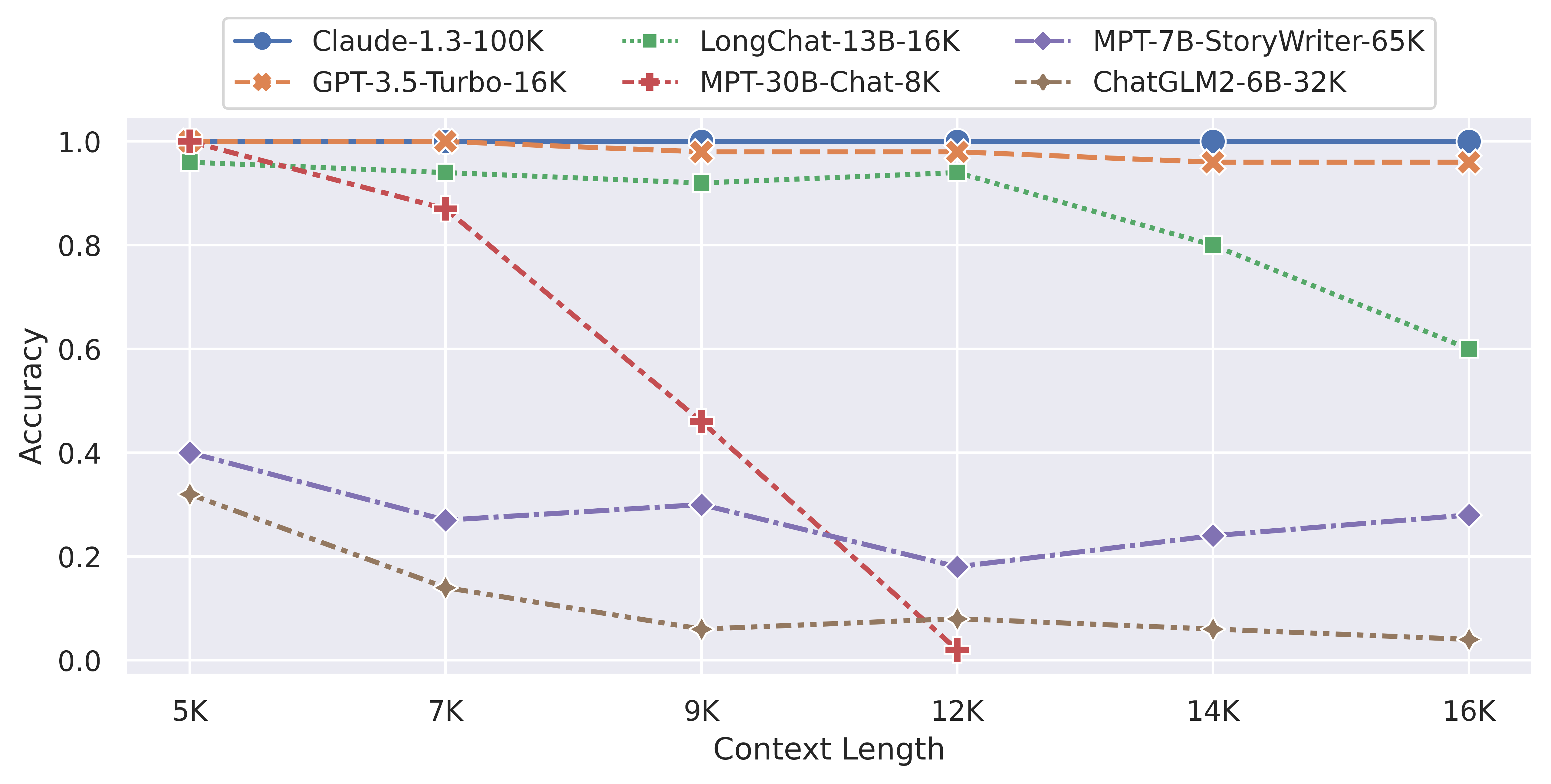
非常直观且残酷,2个商业大语言模型GPT-3.5-Turbo-16K与Claude-1.3-100K在超长上下文评测任务中表现十分稳定,完胜所有开源模型。更加悲剧的是国产翘楚ChatGLM2-6B模型,超长话题检索任务中,在超过6K之后性能急剧下降,准确率在10K、13K、16K上直接降低到了0!在行检索任务上表现12K以内垫底,12K以上,MPT-30B-Chat降到了0,只有LongChat表现尚可,可以说,开源模型一片惨淡!
这个评测是基于LM-SYS最新推出的LongEval评测系统做的。超长上下文评测任务与正常的LLM差别很大。因为很多任务可能用不到超长上下文,二者存在很大差距,而模型对超长上下文支持的方向可能也不相同。本次LM-SYS推出的LongEval是专门用以评测超长规模大语言模型性能的测试套件。主要包含以下2类任务:
任务1 - 粗粒度主题检索:在现实生活中的长对话中,用户通常会与chatbot交谈和切换多个主题。主题检索任务模拟了这种场景,要求chatbot检索长对话中包含多个主题的第一个主题。 任务2 - 精细粒度行检索:为了进一步测试模型从长对话中定位和关联文本的能力,LongChat引入了一种更精细粒度的行检索测试。在这项测试中,LLM需要从长文档中精确检索出一个编号,而不是从多轮长对话中检索一个主题。
官方宣称这两个任务都是大家在使用LLM遇到的比较多的超长上下文的应用场景,代表了模型在支持现实中超长上下文使用的真实场景。
超长上下文模型评测结果总结
尽管开源模型在长上下文支持中比较惨,但是也有一个亮点,即LongChat在16K以内输入场景中表现不错。他们也完全开源了他们的方法,相信开源领域很快会有相应的改进模型。
不过,需要承认的是,LongChat在接近16K输入附近表现就很差了。官方认为主要是他们微调的时候就是16K作为目标导致的结果。如果未来改成32K作为输入微调的目标,相信会有较大的改进。
不过,总的来说,开源领域的LLM在对超长上下文的支持上还是有所欠缺,还需要很多努力~
LM-SYS关于本次超长上下文评测的官方博客:https://lmsys.org/blog/2023-06-29-longchat/
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
