EleutherAI、MetaAI、StabilityAI、伦敦大学等合作的最新关于大语言模型的11个应用方向和16个挑战总结:来自688篇参考文献与业界实践
前天,EleutherAI、MetaAI、StabilityAI、伦敦大学等研究人员合作提交了一个关于大语言模型(Large Language Model,LLM)的挑战和应用的论文综述,引用了688篇参考文献总结了当前LLM的主要挑战和应用方向。
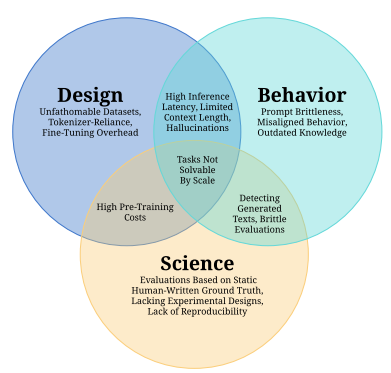
这个论文并不是简单罗列论文,而是从业界实践和学术研究多方面综合性系统性地总结了当前LLM的问题,十分值得学习。本文总结一下这篇论文的核心内容。
这篇论文大方向就两个,一个是LLM的挑战,一个是LLM的应用。作者先说的LLM挑战,再说的应用,我们换个思路,先说一下LLM的11个应用方向,再说一下LLM的16个挑战。
LLM的11个应用方向
在LLM的应用上,作者总结了11个应用方向,并提供了LLM在每一种应用上的架构或者是挑战。总体来说,11个应用方向如下:
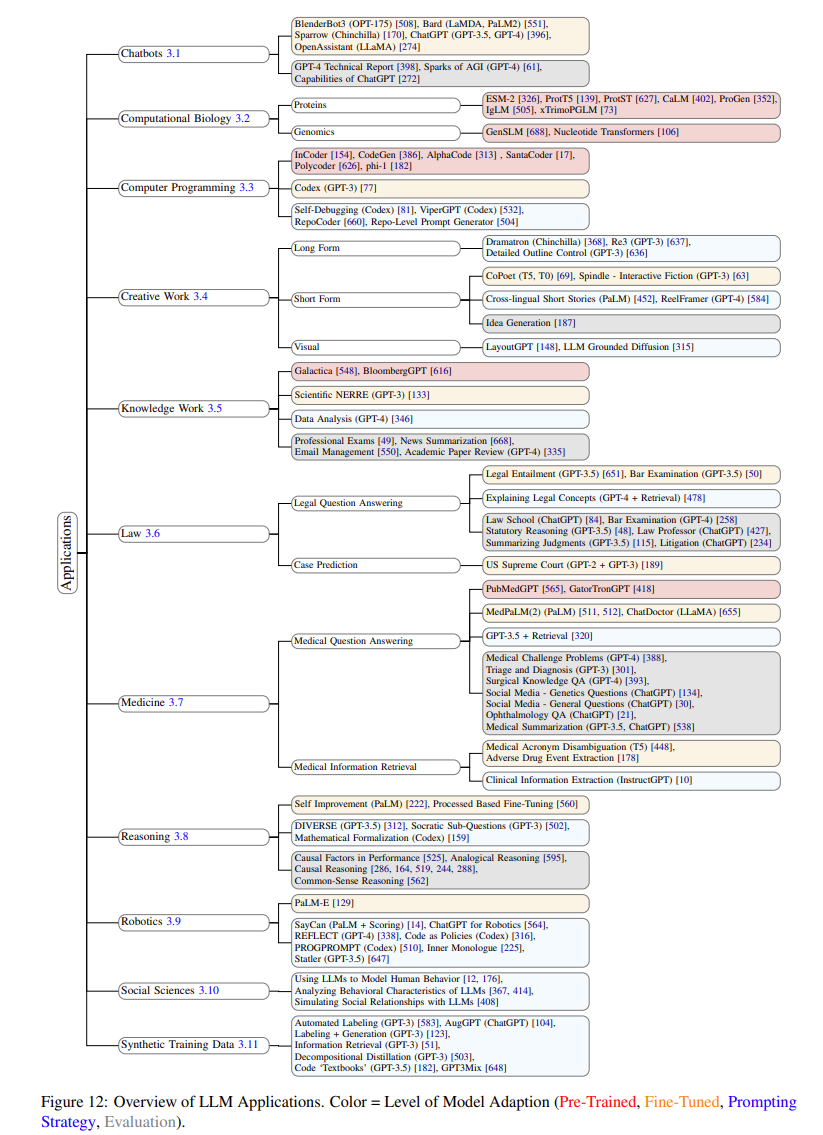
可以看到,这11个应用里面还包含了一些子应用方向,里面也总结了什么样的模型可以应用在这些问题上。作者主要是根据模型的几个方向来区分应用,分布是预训练阶段模型、微调模型、Prompt工程和LLM评估。
这11个应用的具体总结如下:
可以看出,LLM在涵盖了语言理解和生成的绝大多数任务,展现了强大的能力,但也存在一些共性的约束和挑战。比如偏见、hallucination、组合推理能力较弱等,这亦是未来的研究方向。
LLM的16个挑战
这部分内容作者共总结了16个挑战。也是LLM应用和建模中面临的巨大的问题。
可以看到,这些挑战的总结真的十分精辟且一阵见血。不过,尽管作者提出了一些解决方向,但依然只是一个大概方向而已~
这里提到的挑战作者都有详细的分析。例如,第二个问题是分词器的问题,具体来说有很多问题都影响LLM的效果,作者给出另一个例子:
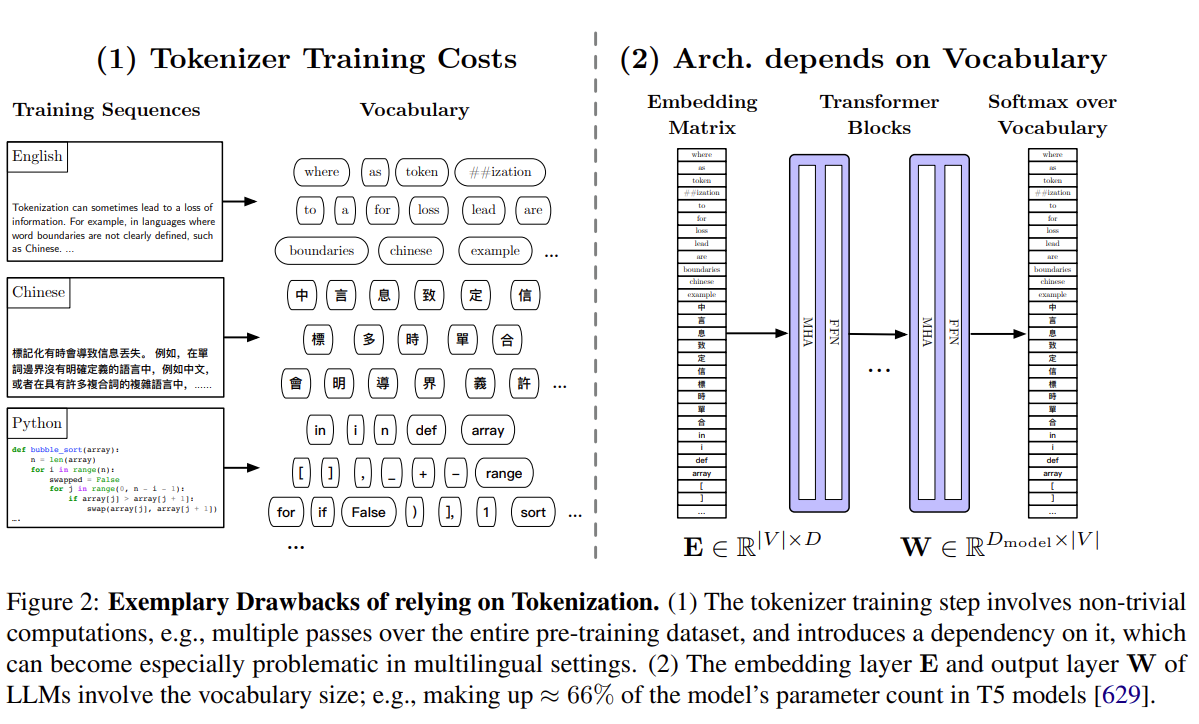
以T5模型为例,tokenizer的训练占用了大量的计算资源,需要进行很多论的训练之后才能使用,还会让模型产生对该tokenizer的依赖,也会在多语言方面引起问题。此外,embedding的输出参数占整个模型的66%左右,影响巨大。具体来说,tokenzier引起的问题:
- 计算开销:需要预训练一个分词器,这增加了计算量,也让模型与特定的预训练语料集耦合。
- 语言依赖性:现有的分词方法更适合语料资源丰富的语言,对低资源语言的支持不够。
- 新词处理:分词器词表固定后,对新词的处理并不友好。
- 词表大小固定:分词时需要限制序列长度,这就要求词表大小固定。
- 信息损失:分词可能造成某些语言信息的损失,如中文中没有明确的词间隔。
- 可解释性低:从子词组成词的过程对人不够直观。
- Glitch token:如果分词器和模型的训练语料不同,会产生训练不充分的未知子词。
这些问题限制了分词器在跨语言场景下的适用性,也给模型的表示能力带来约束。
总之,分词带来了计算和表示上的限制,是大语言模型面临的一个重要挑战。克服这一挑战,对模型的多语言适用性和表示能力都将有益。
近年来LLM训练数据集总结
这篇论文还总结了今年来用于大模型训练的数据集,也非常不错。总结如下:
可以看到,这个总结几乎涵盖了当前大模型常用的数据集,也值得大家收藏。
总结
本文只是非常粗略的总结了当前LLM应用的方向和挑战。原文包含了非常详细的分析与总结,值得大家仔细研读~~
论文名:Challenges and Applications of Large Language Models
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
