MiniMaxAI开源全球推理长度最长的推理大模型MiniMax-M1:100万tokens输入,最高支持80K的推理长度
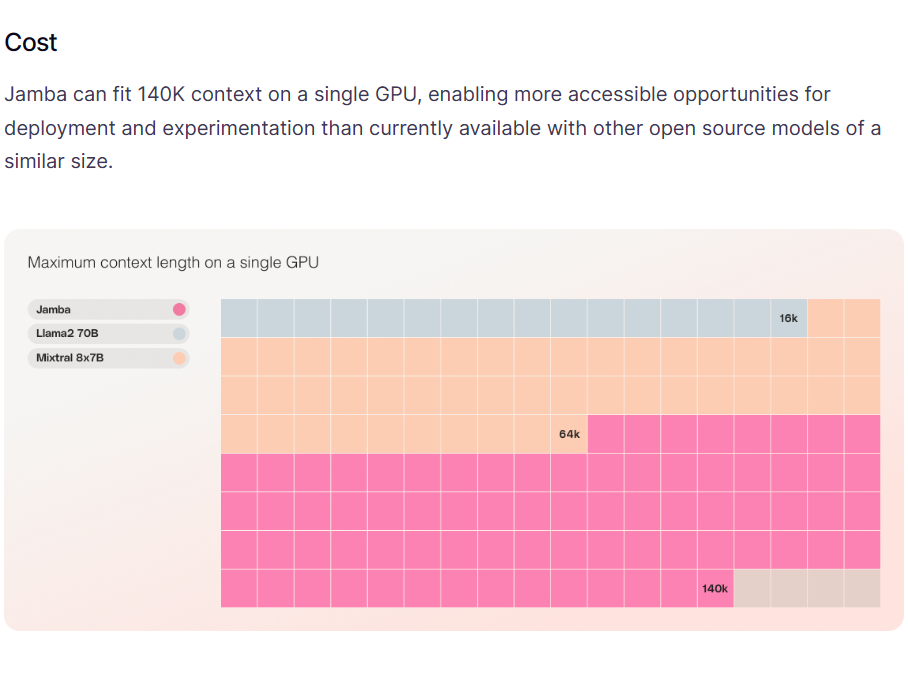
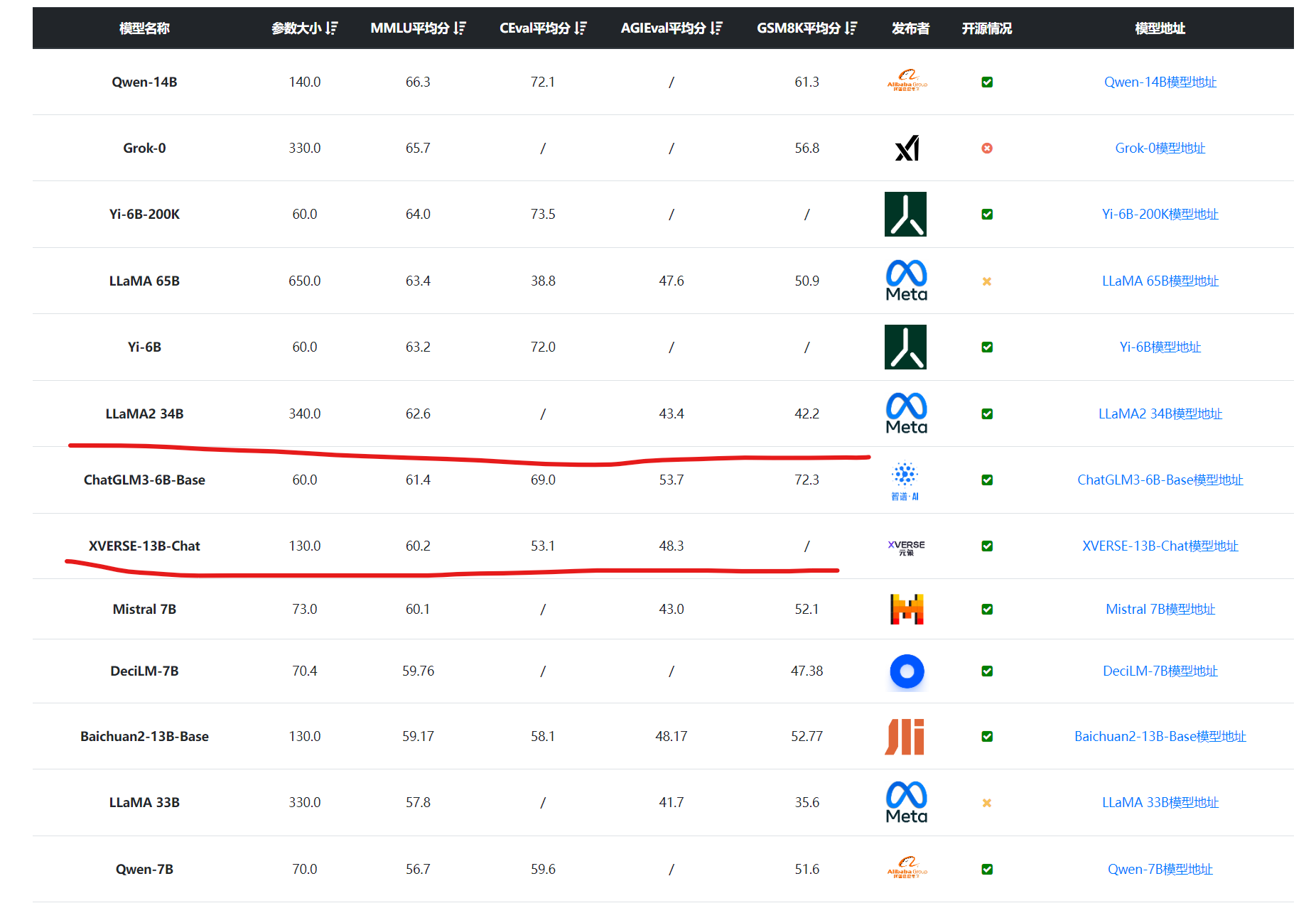
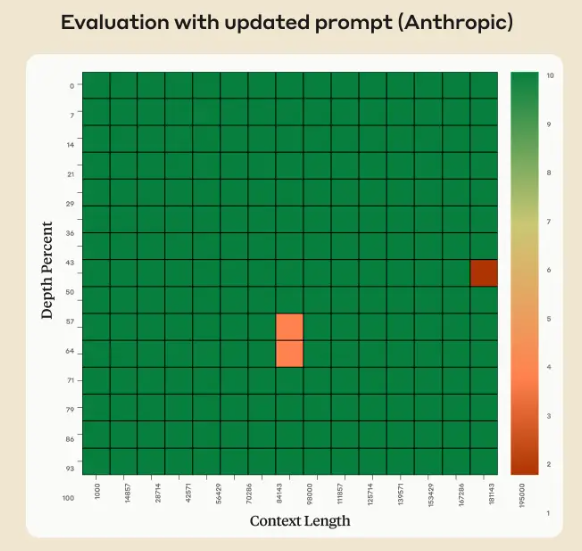
MiniMaxAI于2025年6月17日正式发布了其新一代大模型——MiniMax-M1。MiniMax-M1的核心亮点在于结合了混合专家(MoE)架构和创新的闪电注意力(Lightning Attention)机制。MiniMax-M1不仅原生支持高达100万Token的上下文长度,推理的tokens也支持最高80K,是当前支持的最多推理长度的大模型。此外,MiniMax-M1在计算效率上也很高,例如在生成10万Token时,其FLOPs消耗仅为DeepSeek R1的25%!