大模型泛化能力详解:大模型泛化能力分类、泛化能力来源和泛化研究的方向
关于什么是好的泛化、存在哪些类型的泛化以及在不同的场景中哪些应该被优先考虑,人们对此了解甚少且意见不一。而MetaAI等机构的研究人员最近发布了一篇关于大模型泛化能力的综述,详细总结了大模型泛化能力的分类等。本篇论文详细总结一下大模型的泛化能力分类以及什么样的泛化是未来的中的重点等问题。
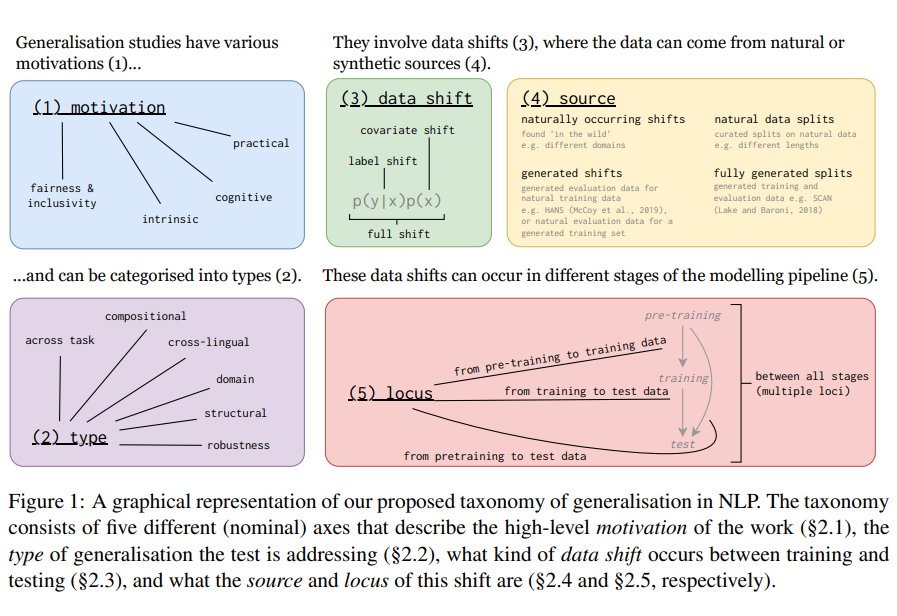
大模型泛化能力简介
泛化(Generalisation)可以理解为一种迁移学习的能力,大致可以理解为把从过去的经验中学习到的表示、知识和策略应用到新的领域,是大模型最被需要的能力。
在NLP的上下文中,泛化意味着模型应该能够在没有直接训练的数据上表现得同样出色。
泛化能力对于大模型的应用尤为重要。因为在我们使用大模型时,我们希望它不仅在训练数据上表现得很好,而且在实际应用中也能够处理各种各样的未见过的数据。尽管泛化的重要性几乎是无可争议的,但是当前的大模型在泛化方面的能力到底在什么水平?各大研究的方向到底是什么却没有一个统一的结论。
《State-of-the-art generalisation research in NLP: A taxonomy and review》论文总结了400多篇ACL关于大模型泛化的研究,得出了一些结论。
泛化能力的分类
作者将泛化分成6种,如下图所示:
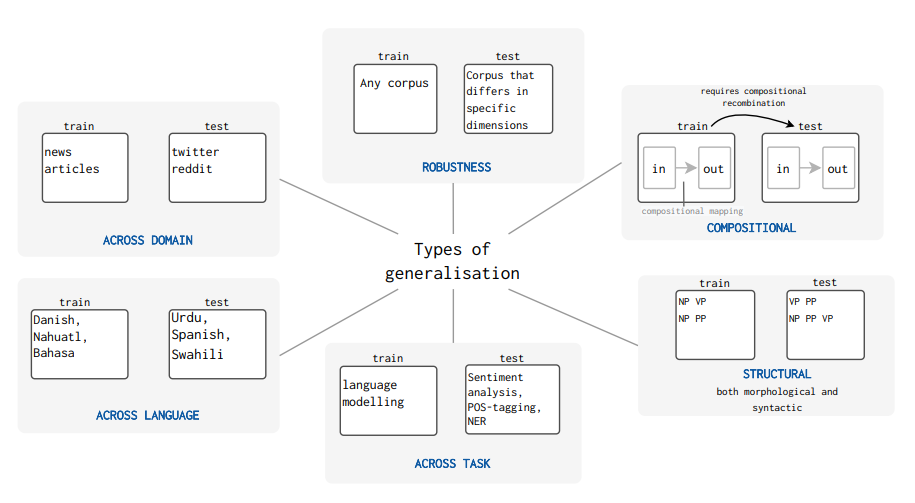
组合式泛化(Compositional generalisation)
组合式泛化可以被理解为一种“拼搭”能力。想象一下,你拥有一套玩具积木,你学会了如何用这些积木搭建各种不同的形状和结构。当你面对一些新的、你之前从未见过的建筑图纸时,你仍然可以利用你已知的积木组合方式来搭建这些建筑。
在语言学习中,这意味着当你学会了某些词汇和语法规则后,你可以将它们组合起来,构造和理解你之前从未遇到过的句子或表达方式。
简而言之,组合式泛化就是利用我们已经学到的知识,通过组合的方式,去理解或处理新的、未曾见过的情境或任务。
-
组合式泛化的定义: 它通常被认为是支持人类快速泛化到新数据、任务和领域的能力。在语言中,输入是“形式”(例如短语、句子、更大的话语部分),它们被映射到它们的意义或解释。组合式泛化被定义为系统地重新组合之前学到的元素的能力,以将由这些元素组成的新输入映射到其正确的输出。
-
为什么它重要: 由于与人类和人类语言的强烈联系,组合式泛化的研究通常主要是出于认知动机。但是,样本效率、快速适应以及在低资源场景中的良好泛化也经常被提及为额外或替代的驱动因素。
-
组合式泛化的挑战: 尽管它具有强烈的直观吸引力和清晰的数学定义,但组合式泛化在经验上并不容易确定。
-
如何评估: 由于组合式泛化是根据输入和输出空间定义的,所以它通常在诸如序列分类、机器翻译、语义解析或其他类型的生成任务中进行评估。在这些任务中,输入和输出空间是明确区分的。
-
当前的问题: 尚未有许多明确的系统尝试来评估(无基础的)语言模型中的组合性。如何在这样的模型中适当地评估组合性,其中输入和输出(形式和意义)在一个空间中被混合(由语言词汇定义的空间),这些问题尚待解答。
结构泛化(Structural Generalisation )
结构泛化是关于计算机模型(特别是语言模型)是否能够理解和生成正确的语言结构,比如句子的语法和词的形态变化。换句话说,这不仅仅是关于模型知道某个词的意思,而是模型是否知道如何正确地使用这个词。
这里主要提到了两种结构泛化:
-
句法泛化(Syntactic Generalisation):就是看模型是否能够理解和生成正确的句子结构。比如,“我喜欢吃苹果”是正确的,但“苹果喜欢我吃”就不对。
-
形态学泛化(Morphological Generalisation):关注词的形态变化,如单复数、时态等。例如,模型是否知道“run”(跑)的过去式是“ran”。
这个概念是为了测试和研究模型是否真的理解语言的结构,还是仅仅记住了训练数据中的模式。
跨任务泛化(Generalisation Across Tasks)
跨任务泛化是指一个模型如何在不同的任务上都表现得很好,而不只是在它原本训练的那一个任务上。例如,如果一个模型在文本摘要上做的针对性训练和调优,但是实际使用时候如果它可以在分析情感上做得很好,那么这个模型就具有跨任务泛化的能力。
这部分的能力在过去几年发生了很大的变化,下面是一些发展总结:
-
多任务学习 (Multitask Learning)
- 传统上,跨任务泛化在NLP中与转移学习和多任务学习紧密相关。
- 在多任务学习中,模型要么在一组任务上进行训练和评估,要么先在某些任务上进行预训练,然后适应其他任务。
- 提到了几个早期的跨任务基准测试,如DecaNLP、GLUE和SuperGLUE。
- 更近期的基准测试将所有任务都定义为序列到序列的问题,可以用一个大的文本到文本的语言模型来处理。
-
预训练-微调范式 (Pretrain-Finetune Paradigm)
- 跨任务泛化曾被认为是一个非常有挑战性的话题。
- 近年来的趋势是先使用一种通用的自监督目标(通常是(掩蔽的)语言建模)对模型进行预训练,然后通过添加特定于任务的参数进行微调。
- 这种预训练-微调范式强调了如何评估跨任务泛化,即模型如何成功地适应不同的任务。
- 微调后,任务的表现通常使用随机的训练-测试切分来评估,因此不一定考虑到单个任务内的泛化。
-
上下文学习 (In-context Learning)
- 近年来,跨任务泛化的研究重点已经进一步转向,考虑预训练的语言模型如何在没有添加任务特定参数的情况下处理不同的任务。
- 在最极端的情况下,这意味着直接在一系列任务上评估语言模型,而不需要进一步的训练。
- 这种方法可以通过问题直接提示语言模型,表示一个特定的任务(零次学习),或者可能之前给出几个例子(少次学习)。
- 在上下文学习中,模型在没有任何参数更新的情况下从上下文中给出的例子中“学习”。
从传统的多任务学习,到预训练和微调范式,再到最新的上下文学习,我们可以看到NLP模型如何适应和处理多个任务的方法正在不断进化。
跨语言泛化(Generalisation across languages)
跨语言泛化是指一个模型在一个语言(比如英语)上学习了某种任务(比如文本分类),然后能够在没有直接在那上面训练的其他语言(比如中文或法语)上执行相同的任务,而且执行得好。简单说,就是模型在一种语言上学了东西,然后看它是否能在其他语言上也用得上这些知识。这很重要,因为对于很多语言,我们可能没有足够的数据来训练模型,所以希望模型能够利用其他语言的数据进行泛化。
该段落讨论了NLP研究中的跨语言泛化问题。以下是主要的理解和解释:
跨语言泛化非常重要,主要方法包括如下两类:
-
跨语言微调 (Cross-lingual finetuning):
- 这是评估跨语言泛化的常见方法之一。
- 常见的实验场景是:在一个语言(通常是英语)中有标签的训练数据,然后在多个语言中评估模型。
- 常见方法是首先在多语言预训练的语言模型上进行微调,使用某一个或几个语言的特定任务注释,然后以零次学习的方式转移到其他语言。
- 这样的设置用于测试模型解决任务的能力在多大程度上与用于训练的标签数据的语言无关。
- 例如,Multilingual BERT 在英语标注数据上微调后,可以很好地泛化到使用不同脚本的语言,但对于词序特性不同的语言对,如英语和日语,可能存在一些系统性的不足。
-
多语言学习 (Multilingual learning):
- 这是另一种评估跨语言泛化的方法。
- 通过测试是否多语言模型在多语言同时训练的情况下,能比单一语言模型在特定语言任务上表现得更好。
- 和多任务学习类似,同时训练在多种语言(或多个任务)上的方法可以被看作是对跨那些语言(或跨任务)的泛化的隐式评估。
- 许多研究调查了多语言模型,通常用于语言建模或机器翻译。
- 大多数这些研究的主要目的是引入在多语言任务上整体改进的模型,而不是由泛化问题驱动的。
- 但是,有些研究确实在其设置中包括了明确的泛化实验,例如评估泛化依赖于不同语言的可用数据量或模型在训练期间接触的语言数量。
跨领域泛化( Generalisation across domains)
跨领域泛化是指一个模型在某种类型的数据上接受训练后,当我们使用它来处理另一种不同类型的数据时,它仍然能够表现得很好。
在这里,主要是指大语言模型文本生成的风格等方面的跨领域。
-
跨领域泛化的定义: 跨领域泛化是指模型在一个域上训练后,对另一个与训练数据不同的域展现出良好性能的能力。所谓的“域”在这里指的是具有不同主题和/或风格属性的文本集合。
-
领域的示例: 如小说、信件、政府文件、电话通话、面对面互动、生物医学文本,以及来源于ArXiv、Github、OpenSubtitles等在线来源的文本。
-
跨领域泛化的研究: 研究的例子包括情感分析模型如何从一个产品评论训练到新产品的泛化,或者从一个人群的数据上训练的模型如何泛化到另一个人群。
-
领域适应: 与跨领域泛化紧密相关的另一个概念是领域适应,这是指将现有的一般模型适应到一个新的领域的问题。在机器翻译、词性标注、情感分析和语言模型预训练等多种任务中都有研究此问题。
-
时间泛化: 跨领域泛化也与时间泛化相关,这涉及到在一个特定时间段内生产的训练数据上的模型在来自不同时间段的数据上的测试。这在如语言建模、问答、命名实体识别、文档分类和情感分析等任务中都有研究。
鲁棒性的泛化( Generalisation in the context of robustness)
鲁棒性泛化是指模型的能力,使其能够在面对新的、与训练数据略有差异的情境时仍然表现良好。简而言之,一个具有鲁棒性泛化的模型不会因为一些小的、未在训练数据中看到的变化而轻易出错。
鲁棒性泛化是指模型有能力学习抽象任务解决方案,使其不受训练数据中可能存在的偶然关联的影响,而是与人类与任务相关的基本泛化解决方案保持一致。
这段文字深入探讨了自然语言处理(NLP)中大型模型在鲁棒性方面的泛化问题。以下是对这段文字的总结和解释:
1. 研究焦点: 鲁棒性泛化的研究通常集中于由不同的数据收集过程产生的数据偏移。这些偏移通常是无意的,并且可能很难识别。
2. 鲁棒性评估的三种常见场景:
-
注释的偏见和人为错误 (Annotation artefacts): 当数据通过众包方式收集时,可能会存在注释偏见或错误。例如,在SNLI和MultiNLI这两个自然语言推断数据集中,已经发现存在这种偏见。研究显示,模型可能只根据特定的句子模式或单词来做出正确的预测,而不是真正的逻辑推断。
-
标准化数据划分的问题 (Standardised splits): 有研究质疑我们如何通常使用数据划分,特别是固定的标准数据划分是否真正反映了模型的泛化能力。某些研究建议使用启发式和对抗性的数据划分方法,以更直接地挑战模型的泛化能力。
-
子群体偏见 (Subpopulation bias): 当训练数据中某些人口统计群体被过度或不足地表示时,可能会出现偏见。这种偏见可能导致模型对某些特定群体的泛化能力不佳,从而导致性能的过度估计。
4. 为了避免这些问题: 要系统地评估和调整模型的性能,例如,通过评估模型在各种人口统计群体中的最差精度,而不仅仅是在所有群体中的平均精度。
总结
上面是本篇论文总结的大模型泛化方面的分类,此外,论文也介绍了这些泛化的能力来源,包括数据分布的变化等。大家有兴趣可以详细阅读。
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
