阿里开源截止目前为止参数规模最大的Qwen1.5-110B模型:MMLU评测接近Llama-3-70B,略超Mixtral-8×22B!
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。DataLearnerAI实测结果,相比Qwen1.5-72B模型来说,Qwen1.5-110B模型复杂任务的逻辑提升比较明显!
Qwen1.5-110B模型简介
在开源大模型领域,最大的模型参数规模通常不会超过700亿参数规模。最近2个月,国外开源的DBRX、Mixtral-8×22B-MoE是最新的超过1000亿参数规模的模型。而国内此前开源领域最大的参数模型是720亿参数规模的Qwen1.5-72B规模和650亿参数的深圳元象科技开源的XVERSE-65B。
这次阿里开源的1100亿参数规模的Qwen1.5-110B模型是截止目前为止国内开源模型中参数规模最大的模型。Qwen1.5-110B模型与其它Qwen1.5系列模型架构一致。采用了分组查询注意力机制,因此推理效率很高。该模型最高支持32K上下文,并且支持多语言,包括英文、中文、法语、西班牙语、德语、俄语、韩语、日文等。
按照1100亿参数估计,Qwen1.5-110B模型半精度的推理显存需要220GB。
Qwen1.5-110B模型开源的版本包含基座模型和Chat优化版本,可以说诚意满满!
Qwen1.5-110B模型的评测结果
根据官方公布的评测结果,Qwen1.5-110B模型的评测结果略略超过Llama-3-70B和Mixtral-8×22B。也比Qwen1.5-72B模型本身更强,这几个模型的评测结果对比如下:
从上面的对比结果看,Qwen1.5-110B模型在综合理解(MMLU)、数学推理(GSM8K和MATH)方面得分比Llama-3-70B略高一点点,是几个模型中最强的。而在复杂推理任务ARC-C上则略低于Mixtral-8×22B模型。在编程测试HumanEval得分则是远超另几个模型,而MBPP编程测试上则低于Mixtral-8×22B模型。从这个评测结果看,Qwen1.5-110B模型应该是与全球最强的开源模型可以一拼。
在DataLearnerAI收集的全球大模型排行榜中,Qwen1.5-110B模型的评测结果非常靠前:
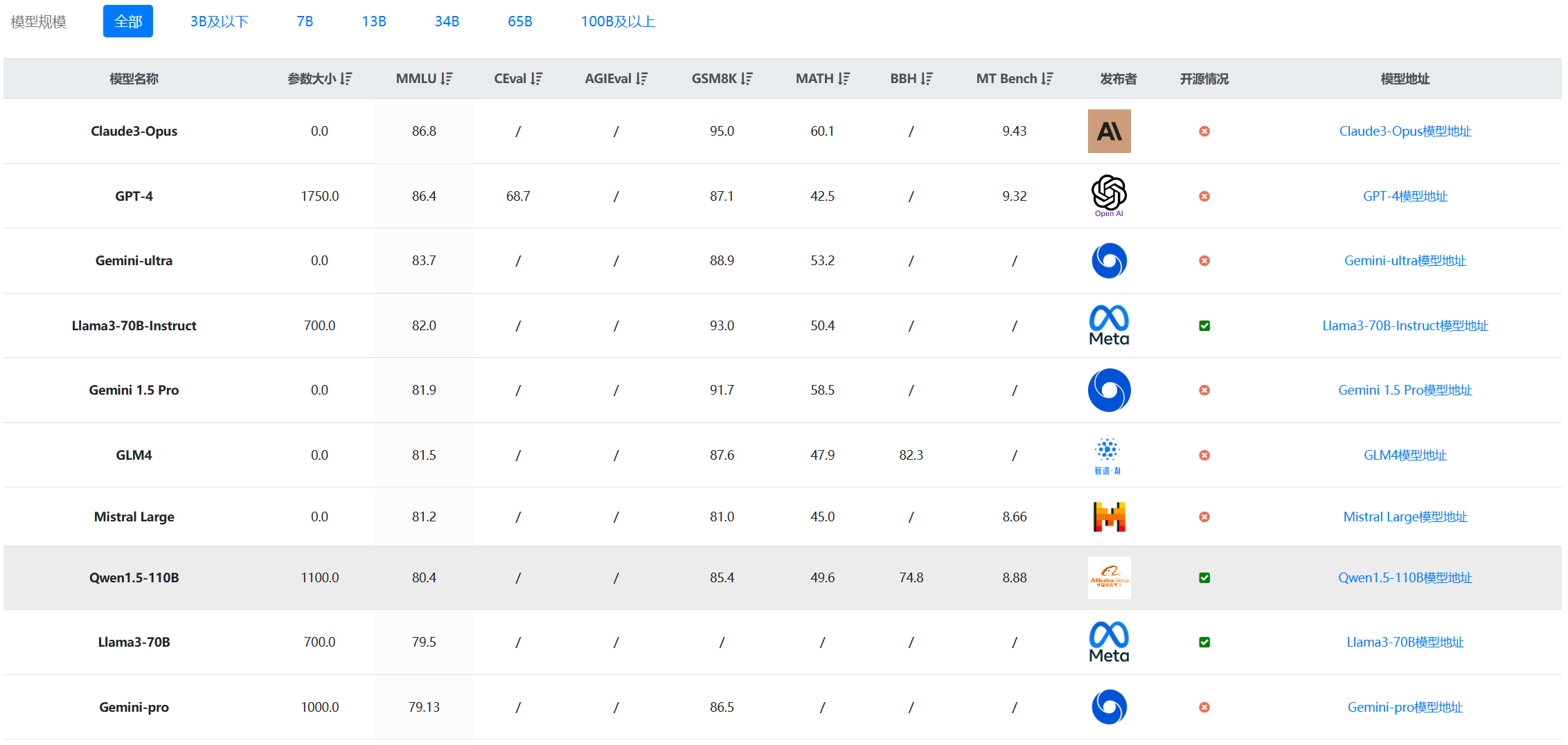
这是按照MMLU排序的结果,也是除了Llama3-70B-Instruct模型外最强的开源模型。
Qwen1.5-110B模型实测结果
官方在HF上放了演示链接,我们用一个实例测试了Qwen1.5-110B和Qwen1.5-72B,模型逻辑方面Qwen1.5-110B模型明显更好,答案非常准确:
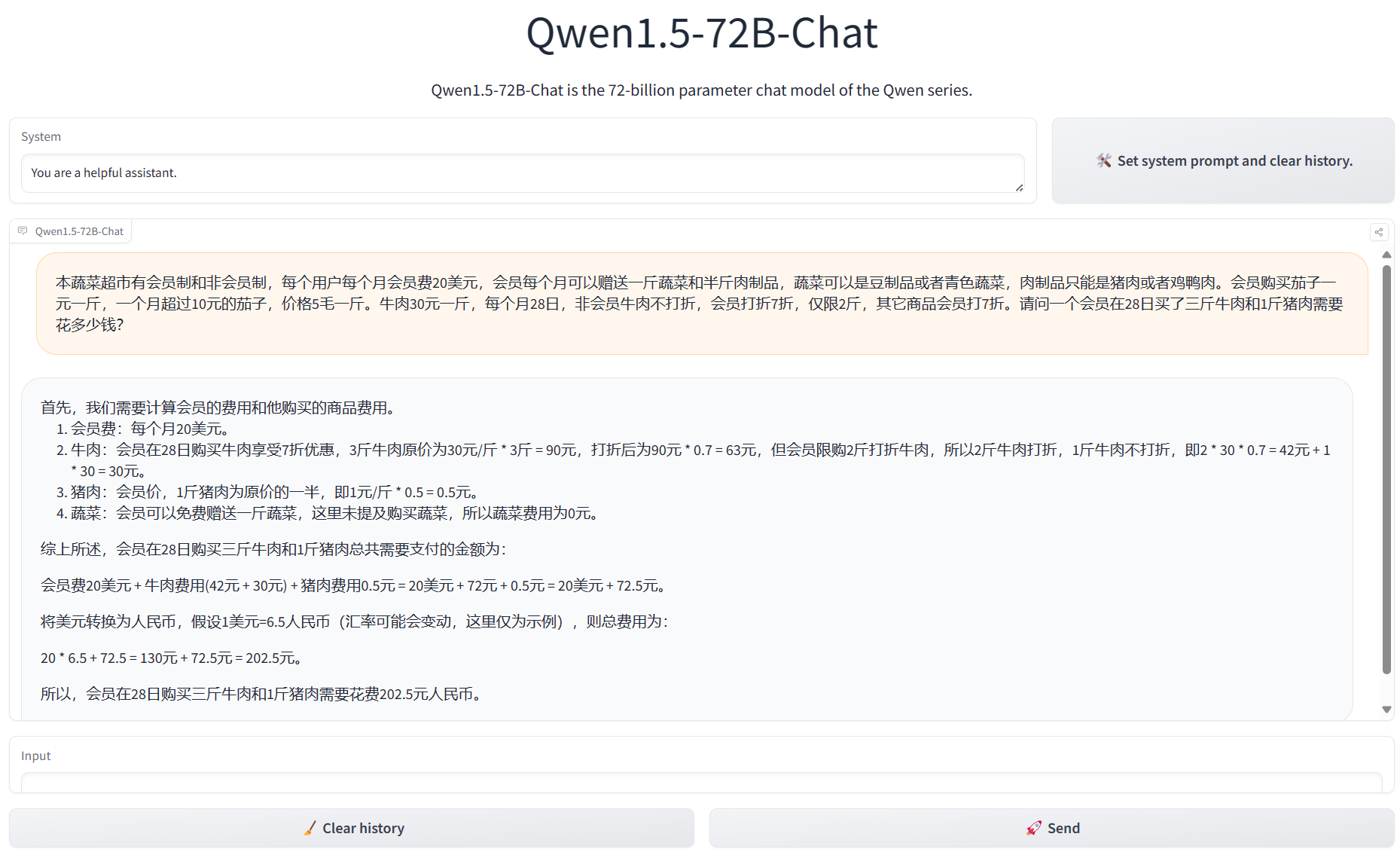
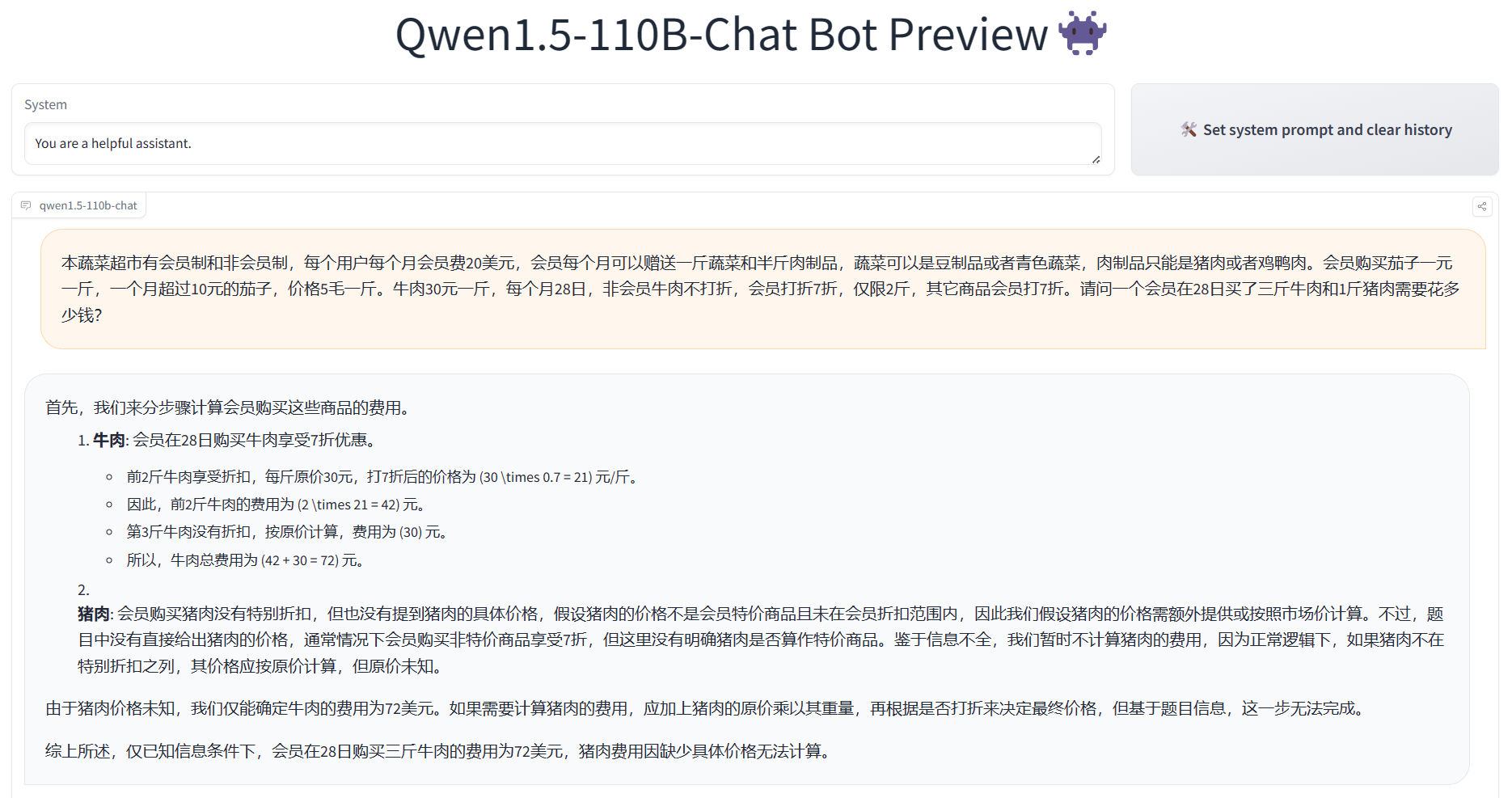
模型的开源地址和演示地址可以参考DataLearnerAI的模型信息卡: Qwen1.5-110B:https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-110B Qwen1.5-110B-Chat:https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-110B-Chat Qwen1.5-72B:https://www.datalearner.com/ai-models/pretrained-models/Qwen1_5-72B-Chat
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
