复杂问题推理能力大幅提升,DeepSeekAI发布DeepSeek V3.2正式版本以及一个评测结果可以媲美Gemini 3.0 Pro的将开源模型推到极限性能的DeepSeek-V3.2-Speciale模型
几个小时前,DeepSeek 突然发布了两款全新的推理模型:DeepSeek V3.2 正式版与DeepSeek V3.2-Speciale。前者已经全面替换官方网页、App 与 API 成为新的默认模型;后者则以“临时研究 API”的方式开放,被定位为极限推理版本。

这次发布吸引了社区立刻刷屏,不仅因为又多了两个新型号,更因为它们分别代表了开源模型两个截然不同的方向:一个负责日常生产,一个负责探索推理边界。
两个月前,DeepSeek 把 DeepSeek V3.2-Exp 推到线上,明确标注“实验版”。验证他们提出的DSA的效果。
DSA全称为DeepSeek Sparse Attention:
DSA 让模型不必再对长达数十万 Token 的上下文“全部计算注意力”,而是先预测哪些内容重要,再对这些内容做精细计算。
换成更直观的比喻:传统注意力像学生复习时把所有资料都从头读到尾,累、慢、效率低。DSA 像有个“索引助手”,先快速浏览所有资料,再告诉你:“最关键的就这 5%”。模型随后只对这些内容精算注意力。因此 DSA 的直接效果是:
- 长上下文成本下降(越长越明显)
- 推理速度提升
- 稳定性更强,思考链不容易被上下文噪声干扰
这套机制在 DeepSeek V3.2-Exp 上首次大规模实战,官方希望确认:在不大幅动模型主体的前提下,把 DSA 这套稀疏注意力接到原有框架里,看看在真实用户的长对话、复杂推理和 Agent 使用中会不会翻车。结果比很多人预期得更乐观——大量社区对比测试显示,在多数场景中,DeepSeek V3.2-Exp 并不逊于DeepSeek V3.1-Terminus,没有出现明显的“减分场景”,却带来了更好的长上下文效率。这等于给 DSA 交上了一份“生产可用”的答卷。
今天上线的 DeepSeek V3.2 正式版,就是在这套架构验证之上,完成的一次「真正意义上的完整模型」。同时亮相的 DeepSeek V3.2-Speciale,则把推理能力进一步推到竞赛级金牌的高度。一个主打“日用 + Agent”,一个主打“极限推理 + 思考深度”,共同勾勒出 DeepSeek 在新一代推理模型上的完整布局。
一、先说清楚:DeepSeek V3.2 正式版和 DeepSeek V3.2-Exp 到底有什么不一样?
DeepSeek V3.2-Exp 更像是一个“工程试装版”,用于验证DSA的效果。从社区反馈来看,DeepSeek V3.2-Exp 在任何特定场景下都没有显著差于 DeepSeek V3.1-Terminus,这基本等价于“架构换心成功”。这也是官方敢于在今天直接把正式版 V3.2 推为默认模型的底气所在。
正式版 DeepSeek V3.2 则是在此基础上的“完整体”:
-
训练与对齐更完整 DeepSeek V3.2 不再是简单的“DeepSeek V3.1 + 新注意力”,而是围绕新架构重新走了一套大规模训练、对齐与强化学习流程,尤其在推理、工具调用和 Agent 行为上追加了更重的后训练算力。
-
能力边界更清晰 官方给出的定位非常直接:DeepSeek V3.2 的目标是平衡推理能力与输出长度,适合问答、日常使用和通用 Agent 场景。你可以把它理解成:从“一切为了验证 DSA”转向“一切为了日常可用”。
-
成为“默认生产模型” 网页端、App 和标准 API 模型全部切换为正式版 DeepSeek V3.2,这意味着:
- DeepSeek V3.2-Exp 的“实验性”使命已经完成;
- 新版本被视为足够稳定,可以承载主流生产流量。
简单总结一下两者关系:
DeepSeek V3.2-Exp = 架构验证 & 实战试飞
DeepSeek V3.2 正式版 = 在验证成功之上,把推理、工具、Agent 全部调校完成的生产主力模型
二、DeepSeek V3.2:推理、输出长度和 Agent 的“三角平衡”
DeepSeek V3.2 最重要的卖点可以用一句话概括:在保持接近 GPT-5 级别推理能力的前提下,把输出长度、响应时间和成本压到一个日常可用的区间里。
在各种公开推理类 Benchmark 中(包括数学、逻辑、知识问答等),DeepSeek V3.2 整体达到了 GPT-5 High的档位,只略低于 Gemini 3.0 Pro。这已经是一个相当冒犯的说法了——尤其是在考虑到它是开源模型的前提下。
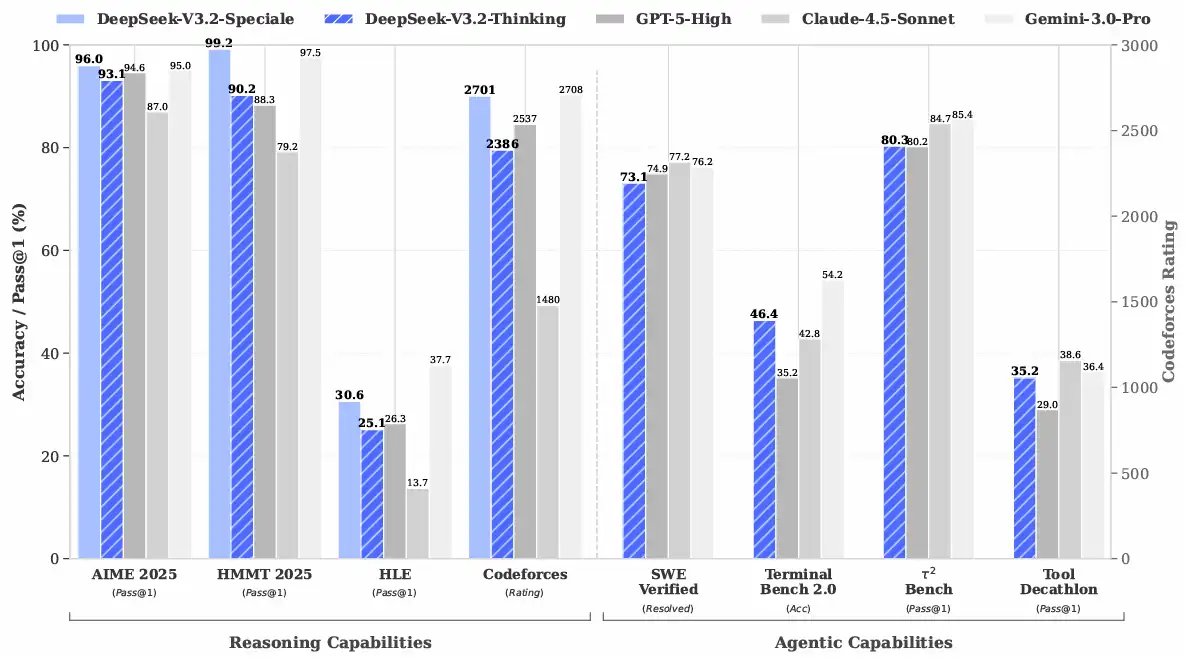
更有意思的是,在与 Kimi K2 Thinking 等长思考模型的对比中,DeepSeek V3.2 的输出长度明显更短,也就是说,它不再一味依赖冗长的“思维链小说”,而更倾向于在适度长度内完成有效推理。这对费用敏感的用户来说是非常现实的优势:算力账单可以更好预期,等待体验也更加友好。
从上图可以看出,DeepSeek-V3.2的tokens消耗显著低于Kimi K2 Thinking,但是很多评测效果都是要略好于它。推理效率非常高。
DeepSeek V3.2也开始有了交替思考的能力
DeepSeek V3.2 另一个提升是它在 “思考融入工具调用” 这一点上的突破。这一点和此前的Claude 4.5系列、Kimi K2 Thinking系列等都是类似的。
即以往的做法往往是:要么在“普通模式”里做工具调用,推理链相对浅;要么进入“思考模式”,但不能标准化调用工具,只能依赖自然语言“假装在用工具”。
而DeepSeek V3.2 则打通了这道分界线。现在在思考模式下,模型可以一边展开 <think> 推理,一边调用工具,再把工具给出的结果纳入后续思考。整个过程可以是多轮的:先思考,再调用,再基于返回继续想,再决定要不要调用别的工具,最后再收敛到一个对用户友好的回答。对开发者而言,唯一要做的,是在 API 层面正确管理 reasoning_content:同一问题下不断回传,换问题时清空此前的思维链,只保留对话与工具调用历史。
下图展示了DeepSeek V3.2在工具调用场景下的交替思考过程:
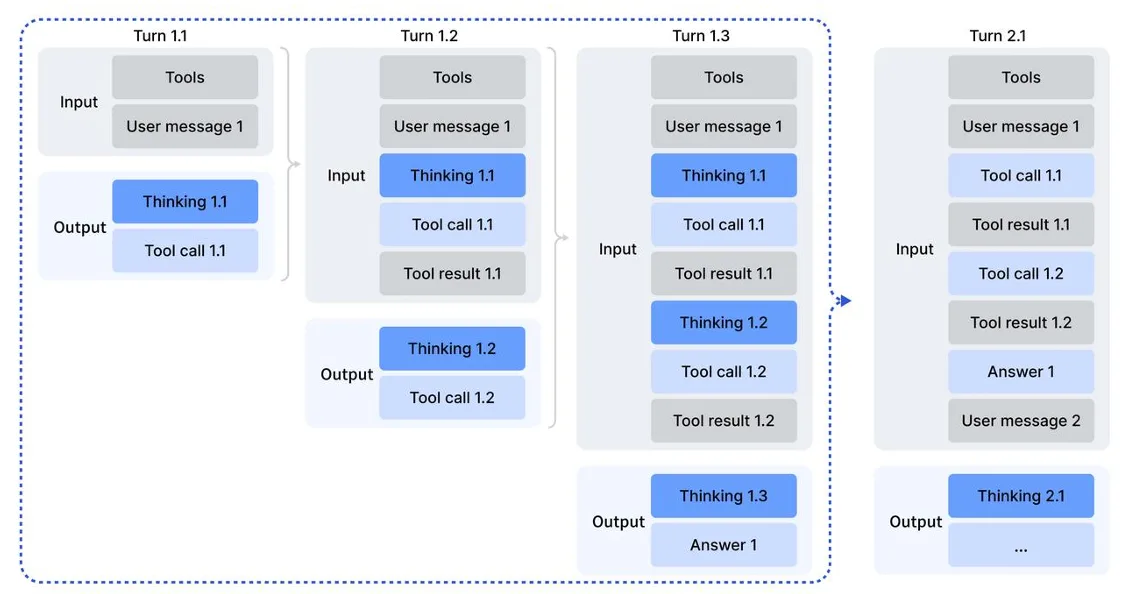
在多套 Agent 评测基准(例如智能体工具调用测试集、Agent 工具调用 Benchmark)里,DeepSeek V3.2 几乎刷掉了所有当前开源模型,在很多维度上只落后于闭源旗舰一点点。更关键的是,官方强调它并没有针对这些特定测试集的工具做过专门训练,这意味着这些成绩更接近真实业务中的“自然表现”,而不是为 benchmark 堆叠的专项技巧。
三、DeepSeek V3.2-Speciale:把推理能力开到“竞赛金牌”的档位
如果说 DeepSeek V3.2 正式版是一台“日常用车”,那 DeepSeek V3.2-Speciale 基本就是一台“赛道版赛车”。
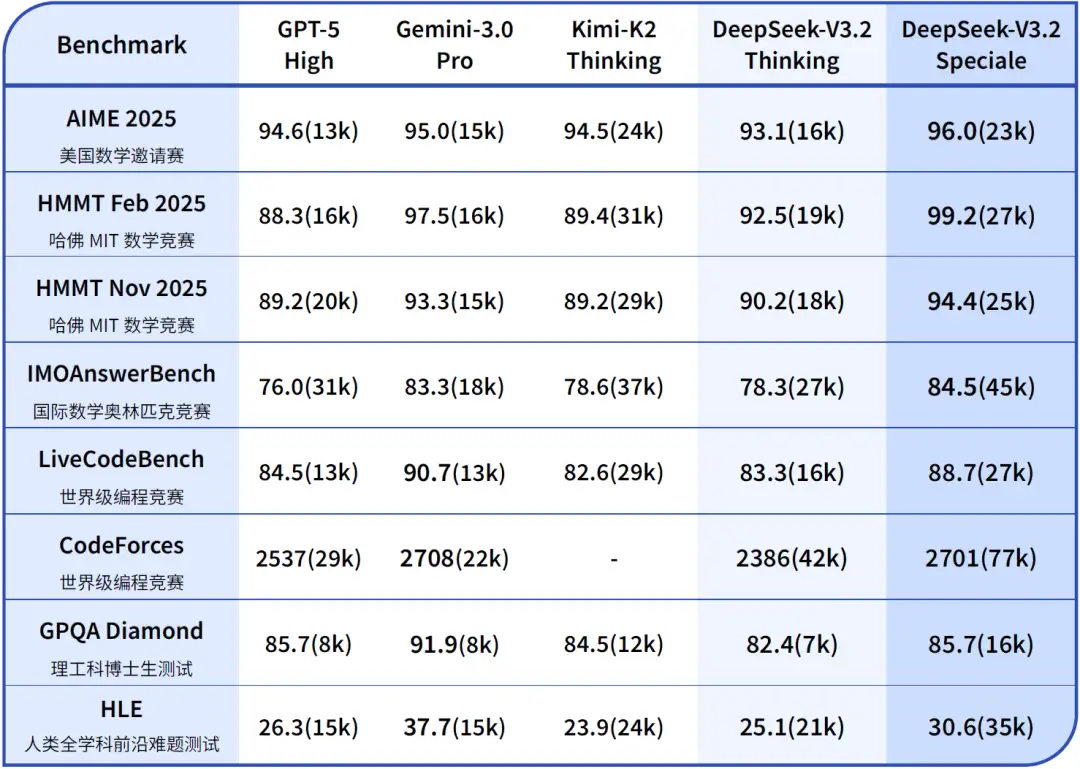
DeepSeek V3.2-Speciale 在架构上延续了 DeepSeek V3.2,但在训练目标上故意放宽了对输出长度和计算成本的约束,并注入了 DeepSeek-Math V2 的大量数学证明数据和奖励机制。结果是,它在多种数学与代码推理基准上表现与 Gemini 3.0 Pro 不相上下,甚至在部分测试中有超越。
更让人印象深刻的是它在真实竞赛中的表现: 在 IMO 2025(国际数学奥林匹克)、CMO 2025(中国数学奥林匹克)、ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛)以及 IOI 2025(国际信息学奥林匹克)中,Speciale 交出了金牌级别的成绩单。其中在 ICPC 和 IOI 上,分别达到了人类选手第二名与第十名的水平。 这已经不只是“会做题”的程度,而是接近“优秀竞赛选手”的综合实力。
当然,这一切都不是免费的。Speciale 会倾向于输出更长的思维链,耗费更多 Token,也更慢、更贵。官方也很坦率地提醒:Speciale 适合的是高度复杂的推理任务,而不是日常对话与写作。
因此它目前只以研究用的临时 API 形式提供:只支持思考模式对话,不支持工具调用,最大输出长度到 128K,服务开放到 2025-12-15 23:59。
如果你平时需要的是大模型帮写文档、写代码、做问答,那么 V3.2 正式版就足够了;如果你是在做数理逻辑、竞赛训练或者希望研究“模型真正是怎么一步一步想出来的”,Speciale 才是那个你会认真研究的对象。
四、对开发者来说,DeepSeek V3.2 这一代应该怎么用?
从 DataLearnerAI 的视角看,这一代最值得开发者关注的不是“又多了两颗强模型”,而是——开源阵营第一次在推理 + Agent 上给了一个足够完整、足够工程化的基础设施。
如果你在做自己的 AI 助手或 Agent 系统,大致可以这样划分心智模型:
-
以 DeepSeek V3.2 正式版为主力 用它来承接绝大多数业务类问题、知识问答、代码生成与调试、文档处理、以及需要工具调用的多轮任务。思考模式 + 工具调用的组合,适合那些“先分析再行动”的复杂流程。
-
用 DeepSeek V3.2-Speciale 做“问题终结者” 在极少数真的卡住的问题上——尤其是数学证明、复杂算法、竞赛题解析、难度极高的代码问答——再把请求升级到 Speciale,由它给出一套更具体、更长、更严格的推理过程。你甚至可以把它当成 V3.2 的“二审法官”:当多个模型意见不一致时,让 Speciale 负责最后的审查和校对。
对整个开源生态而言,DeepSeek V3.2 / DeepSeek V3.2-Speciale 的意义也不仅仅是“性能标高了多少分”。更重要的是,它们表明:
- 开源模型不再只能在“价格”和“开放性”上做文章,而是可以在推理和 Agent 能力上正面掰手腕;
- 工程思路从“再堆一点参数”转向“重新设计注意力、训练管线和 Agent 任务本身”;
- 对开发者来说,做系统时可以更大胆地用开源模型作为主力,闭源模型变成选配,而不是唯一选项。
关于这两个DeepSeekAI开源大模型的开源地址和其它信息参考DataLearnerAI大模型信息卡:
https://www.datalearner.com/ai-models/pretrained-models/deepseek-v3-2
https://www.datalearner.com/ai-models/pretrained-models/deepseek-v3-2-speciale
DataLearner 官方微信
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
