重磅!阿里开源2个多模态向量大模型和重排序大模型:Qwen3-VL-Embedding和Qwen3-VL-Reranker,图片和视频也可以用来做RAG了!
RAG(Retrieval-Augmented Generation,检索增强生成) 一直被认为是大模型突破上下文长度限制、融合外部最新知识的最佳实践路径之一。然而,现有 RAG 方案在绝大多数场景下仍然以文本检索为核心,对于图片、视频等多模态数据,业界长期缺乏成熟、可用,尤其是开源的通用模型支撑。
就在刚刚,阿里巴巴正式免费开源了两款全新的多模态模型——Qwen3-VL-Embedding(多模态向量模型)和 Qwen3-VL-Reranker(多模态重排序模型),首次在开源体系中系统性补齐了多模态 RAG 在“向量化检索 + 精排重排”两个关键环节上的能力空白。这两个模型是基于强大的Qwen3-VL基础模型构建的专用多模态向量与重排(Reranking)模型。该系列模型能够无缝处理文本、图像、视频等多种模态输入,在多项多模态检索任务的Benchmark上达到了SOTA水平,其中8B尺寸的向量模型在MMEB-V2排行榜上以77.8分的成绩排名第一。Qwen3-VL-Reranker模型在多个评测基准上同样大幅超越了现有的主流开源竞品。

Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 基本情况
本次阿里开源的这两个多模态向量检索和重排序模型包含2个不同参数规模的版本,分别是2B和8B,也就是共4个模型。这四个模型都支持最多32K的输入。其中20亿参数版本的Qwen3-VL-Embedding-2B最大支持2048维度的向量输出,而80亿参数版本的Qwen3-VL-Embedding-8B则最大支持4096维度的向量输出。且这两个向量大模型都支持用户自定义输出向量维度。
根据官方的介绍,本次开源的Qwen3-VL-Embedding和Qwen3-VL-Reranker模型系列是Qwen大模型家族的最新成员,专注于解决多模态信息检索(Multimodal Retrieval)和重排(Reranking)两大核心任务。该系列模型继承了Qwen3-VL基础模型的强大多模态理解能力,并通过创新的多阶段训练方法,为开发者提供了目前最顶尖的开源多模态向量与重排解决方案。
由于Qwen3-VL的强大基座能力,这两个模型支持30多种语言的检索和重排序!这点可以说十分友好了,对于有小语种诉求的童鞋来说非常友好。这四个模型的具体参数如下:
Qwen3-VL-Embedding 和 Qwen3-VL-Reranker 模型的四大特点
官方也总结了本次开源的这两个模型的四个核心特点:
1、Qwen3-VL-Embedding 和 Qwen3-VL-Reranker算得上是支持全模态的输入
Qwen3-VL-Embedding和Qwen3-VL-Reranker能够在统一框架内无缝处理多种输入类型,包括文本、图像、截图和视频。在图像-文本检索、视频-文本匹配、视觉问答(VQA)和多模态内容聚类等多样化的多模态任务中均达到了业界领先水平。无论是处理单一模态还是混合模态的数据,模型都能提供一致且优秀的性能表现。
2、统一表示学习(Embedding):把“图”和“文”压到同一个语义空间里
通过充分利用Qwen3-VL架构的强大能力,Qwen3-VL-Embedding模型能够生成语义丰富的向量表示,在统一的语义空间中同时捕获视觉和文本信息。这种跨模态的统一表示使得不同模态之间的相似度计算和检索变得高效而准确。开发者可以使用同一套向量表示来处理文本查询匹配图像、图像查询匹配视频等各种跨模态检索场景。
3、高精度精排(Reranker):对任意模态的(query, document)给出更准的相关性分数
这次同时开源的 Qwen3-VL-Reranker 是对 Embedding 的“补齐”。它的输入是一个 (query, document) 对,输出则是相关性分数。而且输入的 query 和 document 都可以是单模态或混合模态(例如:文本问句 + 图片候选;文本问句 + 视频候选;图片 query + 文档截图候选)。 在RAG应用中,两者通常搭配使用:
- Embedding 负责第一阶段高效召回(Recall)
- Reranker 负责第二阶段精排(Re-ranking)
- 实用性和灵活性都很好
如前所述,由于这两个模型来自Qwen3-VL,因此也继承了 Qwen3-VL 的多语言能力,支持 30+ 语言,适合全球化应用。此外,这两个模型还包括一些额外特性:
- 向量模型的输出维度可自定义配置:2B最高支持2048的向量输出维度,8B最高支持4096的向量输出维度,但是该模型支持MRL(Matryoshka Representation Learning)技术,允许用户在不重新编码的情况下,根据需求(如存储成本、检索速度)灵活截取不同维度的向量。实验表明,从1024维降至512维,检索性能仅下降1.4%,但存储减少50%,检索速度提升2倍,实现了效率与效果的动态平衡。
- 支持自定义指令(Instruction),即针对具体场景做行为对齐(这是比较重要的特性,下面会说)
- 量化后的 embedding 仍保持较强效果:官方介绍Embedding的2个模型支持量化,因此可以更快(官方目前还未看到开源的量化的预训练结果)
官方提到,团队利用Qwen3-VL-32B的多模态生成能力,自动合成了大量高质量的多模态训练数据,包括图像分类、图像问答、图像检索、视频分类、视频问答、视频检索和时刻检索等多种任务类型。也就是说用了大量合成数据来训练。
总之,Qwen3-VL-Embedding和Qwen3-VL-Reranker两个模型不单单是开源预训练结果这么简单,也考虑了很多工程落地的特性,支持大家使用。而这其中我们觉得比较好的是排序模型支持自定义指令。
Qwen3-VL-Embedding和Qwen3-VL-Reranker支持自定义指令的排序
其实这里比较值得一提的是支持自定义指令:即你在做向量化(embedding)或精排(rerank)时,不只是丢一个 query / 文档进去,还可以额外给模型一段“任务说明/偏好规则”,让它按你的业务目标去理解“什么叫相关”。传统 embedding 往往默认目标是:句子语义接近就相似。但在真实业务里,“相似”经常不是语义相似,而是更具体的目标,比如:
- 我想找的是同一商品的不同说法(同义归一)
- 我想找的是能回答问题的证据段落(问答证据检索)
- 我想找的是包含某字段/参数的文档页(结构化信息定位)
- 我想找的是同一个故障现象的解决方案(运维知识检索)
Instruction 就是让你把这些目标用一句话写出来,作为“检索任务定义”。有了这层“检索任务定义”,向量检索就不再只是做一个通用的语义相似度计算,而是把你的业务偏好显式注入到召回与排序的标准里。它带来的最直接变化是:同样一句 query,在不同指令下会“找出完全不同的东西”——做商品同义归一时更关注品牌/型号/规格的对齐,做问答证据检索时更关注是否包含结论、数字和条件,做结构化定位时更强调字段是否精确出现,做运维排障时则更看重报错信息与解决步骤是否匹配。换句话说,Instruction 让 embedding 和 rerank 从“泛化的相似”升级为“可控的相关”,减少了“看起来很像但无法落地”的结果,把检索链路的有效命中率拉到更贴近业务可用的水平。
Qwen3-VL-Embedding和Qwen3-VL-Reranker的评测结果
根据官方发布的评测数据,Qwen3-VL-Embedding模型在多个主流多模态基准测试中展现了质的飞跃,其性能全面领先于现有的开源模型,也超过了闭源的商业模型。
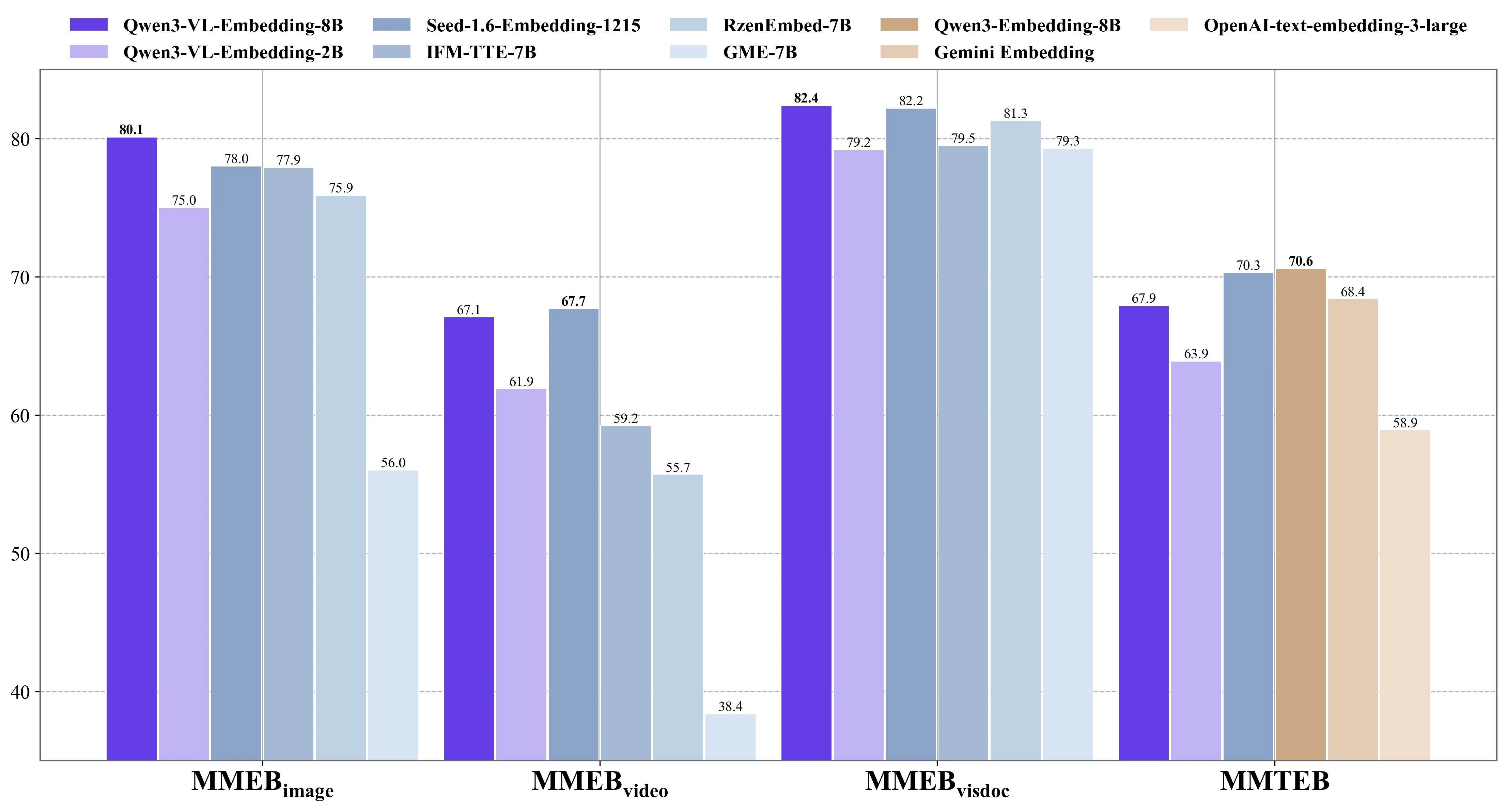
同样的,重排序模型也展现出强大的性能:
总之,官方评测结果数据还是非常好的,实际测试结果应该很快业界就有数据了。
Qwen3-VL-Embedding和Qwen3-VL-Reranker完全免费商用授权
目前,Qwen3-VL-Embedding和Qwen3-VL-Reranker系列模型已经完全开源,并遵循 Apache 2.0 许可证。这意味着可以完全免费商用,没有任何限制。
为了方便开发者根据需求选择合适的模型,官方提供了详细的模型参数列表,可以从DataLearnerAI网站上获取开源的代码地址、预训练权重地址以及官方论文等信息:
Qwen3-VL-Embedding和Qwen3-VL-Reranker系列的发布,无疑为开源社区带来了目前最强大的多模态向量和重排工具。它不仅在多项关键Benchmark上树立了新的SOTA标准,还通过统一的多模态表示、灵活的维度选择、量化支持和指令感知等功能,赋予了开发者前所未有的灵活性。对于正在构建或希望优化多模态搜索、视觉问答、视频检索及其他跨模态信息检索系统的开发者而言,Qwen3-VL-Embedding和Qwen3-VL-Reranker系列是一个不容错过的选择。
